Sabitlenmiş Tweet

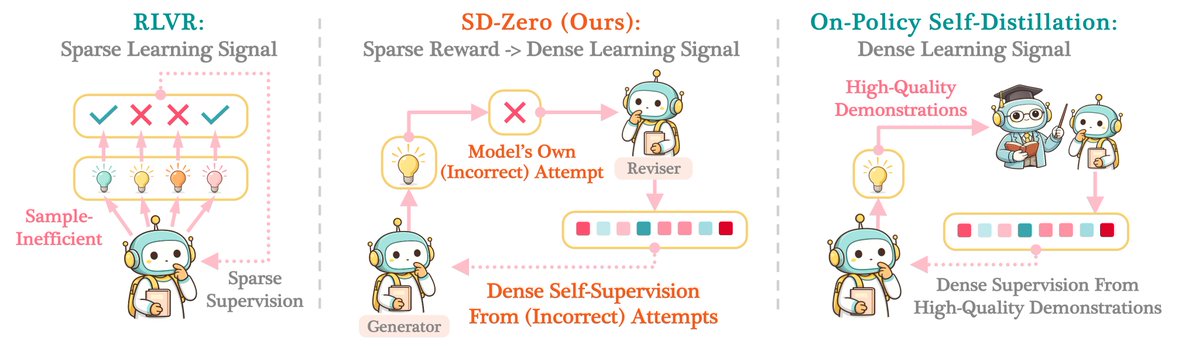
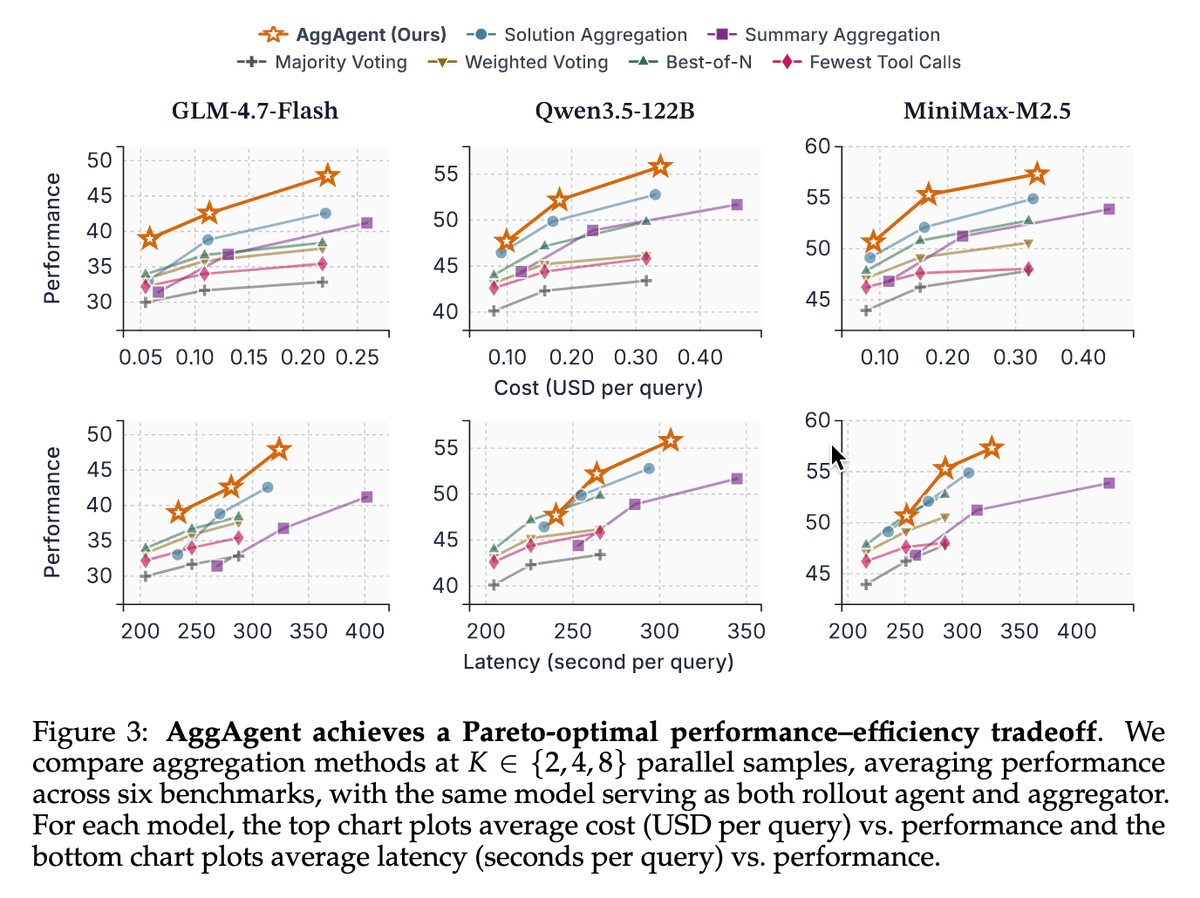
How should we effectively aggregate long-horizon agent trajectories? 🧐
Unlike CoT reasoning, agentic tasks pose unique challenges: they are long, multi-turn, and tool-augmented.
Introducing 👉🏻 AggAgent 👈🏻 — which treats parallel trajectories as an environment to interact with.

English