Sabitlenmiş Tweet

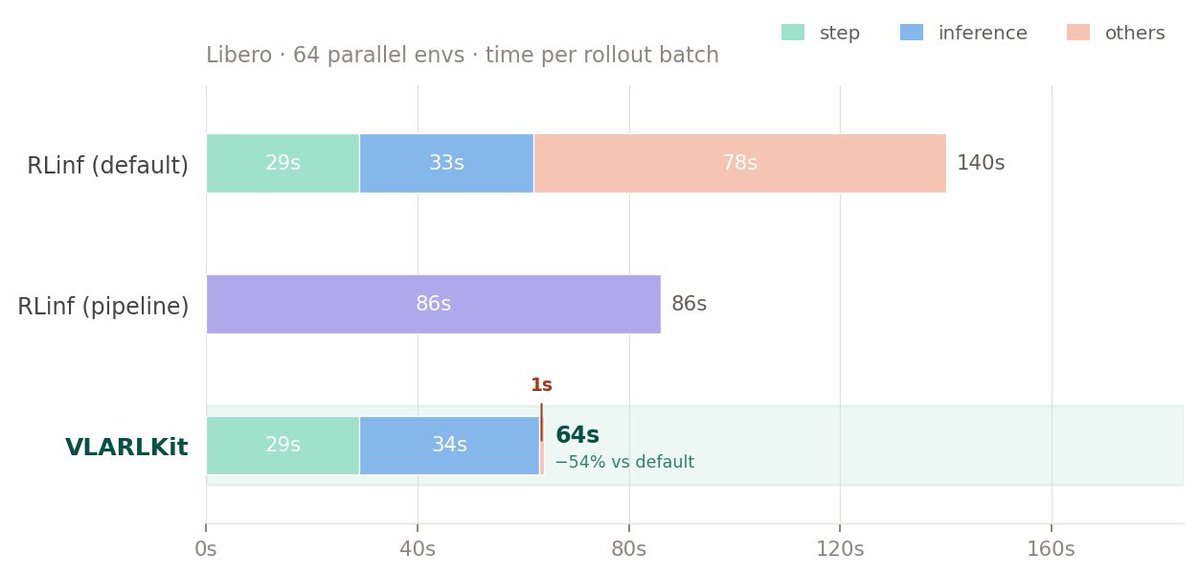
#COLM2025 We introduce Adaptive Computation Pruning (ACP) for the Forgetting Transformer (FoX) — a provably safe pruning method that significantly speeds up our Forgetting Attention kernel, especially for long-context pretraining. Our simple Triton kernel with ACP is 1.7x to 2.4x faster than the official FlashAttention2 kernel when pretraining 760M-param models with context lengths from 4k to 16k on 4xL40S!
• Code: github.com/zhixuan-lin/fo…
• Paper: arxiv.org/abs/2504.06949
Joint work with @johanobandoc, Xu Owen He, @AaronCourville, from @Mila_Quebec and @makermaker_ai
More details👇

English