
zikasak
2.8K posts

what should we do in the next 3 months?
Andrew Ambrosino@ajambrosino
the Codex app turns 3 (months old) today. they grow up so fast
English

To be secure in 2026 you have to shut down your bug bounty program on HackerOne.
Lovable got hacked because HackerOne's incompetent triage team closed multiple valid vulnerability reports starting February 22, 2026 as "intended behavior."
Poorly trained monkeys. Zero escalation to Lovable's security team. AI bots auto-closing critical findings.
The result? Public project chat history and source code were exposed for MONTHS until a researcher was forced to go public.
Two companies. Same platform. Same failure. Same lies.
ClickUp. Lovable. Both breached because HackerOne buried critical reports while collecting your bounty fees.
HackerOne is NOT a security partner. They are a liability.
They close real vulnerabilities. They protect their own metrics over your data. They let researchers get attacked while they stay silent.
Stop paying HackerOne to get hacked.
lovable.dev/blog/our-respo…

English
@lhtness66060 @GergelyOrosz Read the message carefully... They are working on test coverage for merge queue operations. Reads like there were no tests
English

@GergelyOrosz Wait, github somehow failed to correctly implement "git merge origin/main", despite it previously being correctly implemented for a very long time? And tests did it catch it?
English

Massive L from GitHub
One of the most embarrassing outage that can happen (a data integrity issue), and the response is "well, actually, it's only 0.07% of customers...")
Customers whose workflow is messed up badly are fuming reading this. No respect for the customer...
Kyle Daigle@kdaigle
Wanted to provide more clarity about this. Yesterday, we had a regression in merge queue behavior where, in some cases, squash or rebase commits were generated from the wrong base state, making earlier changes appear reverted in branch history. 2,804 pull requests out of over 4M merged on April 23 (roughly 0.07%) were affected. We fixed the issue, we've contacted every impacted customer, and we're expanding our automated test coverage for merge queue operations. The team will be updating the status page with RCA details as well.
English


I want to keep everyone updated on the details of the security investigation.
The team performed an in-depth analysis to search for root causes and to better understand the behavior of the threat actor.
We cast a very wide net, pulling and processing nearly a petabyte of logs of the entire Vercel Network and API, extending well beyond the initial Context[.]ai compromise.
We now understand that the threat actor has been active beyond that startup's compromise. Threat intel points to the distribution of malware to computers in search of valuable tokens like keys to Vercel accounts and other providers.
Once the attacker gets ahold of those keys, our logs show a repeated pattern: rapid and comprehensive API usage, with a focus on enumeration of non-sensitive environment variables.
As a result:
◾We've deepened and widened our collaboration with partners across the industry, like Microsoft, AWS and Wiz, to further protect the broader internet.
◾ We've notified other suspected victims of this threat actor, independent of this event, encouraging them to rotate credentials and adopt best practices.
We've also shipped a bunch more product enhancements. I'm extremely thankful to our team and industry partners for working around the clock. For more details on the ongoing investigation, refer to our security bulletin:
vercel.com/kb/bulletin/ve…
English

@madebyhex There are several *standard* APIs in Safari that straight out don't work. Having spent half a year on a webview-based refactor, I know that architecture is a waste of time for some apps, if not all.
English
All you have to understand about WebView-based Electron 'killers' is that they are using Safari's WebView on macOS.
Sadly, case closed.
brendan@brendonovich
we've moved opencode desktop to electron. it's faster, more reliable, and will replace our tauri build soon. try it out in beta via the link below.
English


Fun fact
The devices he is stealing are useless bricks that can’t be used as a phone. Apple Store demo devices are not like regular devices. U can’t do anything with them
鈴森はるか 『haruka suzumori』 🇯🇵@harukaawake
🇯🇵 I'm really glad I live in a high trust society like Japan.
English
English

English

What do you think the upcoming rumored OLED touchscreen MacBook Pro will be called? 👀

English
English

@SebAaltonen @privatetalky Macbook already has OLED
English

My biggest gripe about MacBook Neo is the RAM: A18 Pro has 12GB in phones. Laptop has only 8GB. Bigger 2408x1506 screen + MacOS is a multitask OS. MacBook Air 8GB was already showing up to 40% slowdown in browser benchmarks vs 16GB model (heavy SSD swap). Otherwise it's good.
Andrew Clare@andrewjclare
Things I’ve learned since the Macbook Neo was announced: - Turns out even a $499 MacBook can be controversial. - According to tech twitter, 8gb of ram isn’t enough for note taking, opening up a website and running the ChatGPT app at the same time. - everyone really did want colorful MacBooks - Android users are defending windows - Steve Jobs would have approved this - the iPad Air is cooked - Rest in peace Chromebooks - people think an iPhone chip is bad - If edit 8K video while rendering a 3D animation, while exporting a podcast, running 100 Chrome tabs, Final Cut, Blender, and still checking email like nothing’s happening, during simulating an entire city in a game engine just to test shadows and running four external displays while the fans barely wake up… the Neo is not for you.
English

"well it's true because on windows the 8 out of 16gb is already used on idle"
Superfetch!
Superfetch makes use of standby pages to preload resources from disk to make those accessible much quicker.

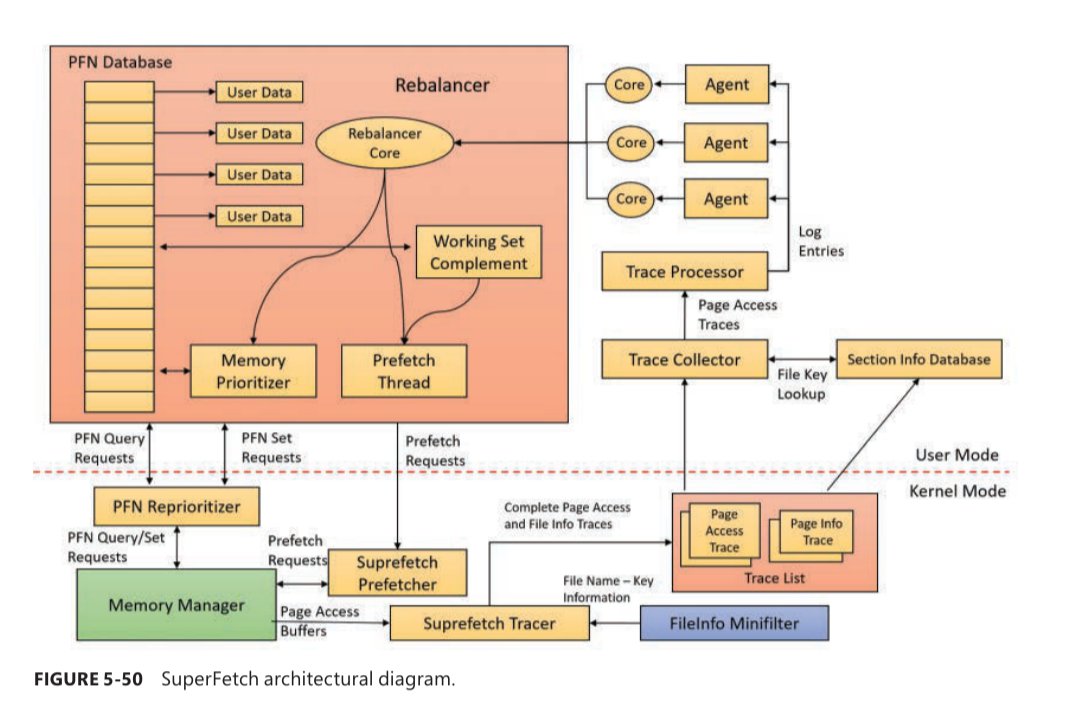
NSG650@nsg650
"8gb on macOS is the same as 16gb on Windows" and 100 other jokes to tell your friends
English

Wow they did it 🔥
"Qwen3.5-35B-A3B now surpasses Qwen3-235B-A22B-2507"
So in 6 months they've trained a model which is:
- 6.7x smaller than the previous one
- Better in all benchmarks
- Available locally on a laptop
We're just at the very beginning of local LLMs and, at some point, we'll have an Opus 4.6 intelligence running on a phone.
Qwen@Alibaba_Qwen
🚀 Introducing the Qwen 3.5 Medium Model Series Qwen3.5-Flash · Qwen3.5-35B-A3B · Qwen3.5-122B-A10B · Qwen3.5-27B ✨ More intelligence, less compute. • Qwen3.5-35B-A3B now surpasses Qwen3-235B-A22B-2507 and Qwen3-VL-235B-A22B — a reminder that better architecture, data quality, and RL can move intelligence forward, not just bigger parameter counts. • Qwen3.5-122B-A10B and 27B continue narrowing the gap between medium-sized and frontier models — especially in more complex agent scenarios. • Qwen3.5-Flash is the hosted production version aligned with 35B-A3B, featuring: – 1M context length by default – Official built-in tools 🔗 Hugging Face: huggingface.co/collections/Qw… 🔗 ModelScope: modelscope.cn/collections/Qw… 🔗 Qwen3.5-Flash API: modelstudio.console.alibabacloud.com/ap-southeast-1… Try in Qwen Chat 👇 Flash: chat.qwen.ai/?models=qwen3.… 27B: chat.qwen.ai/?models=qwen3.… 35B-A3B: chat.qwen.ai/?models=qwen3.… 122B-A10B: chat.qwen.ai/?models=qwen3.… Would love to hear what you build with it.
English

PSA: gpt-5.2-high is much, MUCH better than gpt-5.3-codex, albeit slower.
Codex models don't handle complex tasks well, only relatively straightforward instructions, while gpt-5.2-high is Opus 4.5 level of intelligence (close to Opus 4.6).
English
@vincent_presh @SebAaltonen How much should I pay for using lm studio? And to who?
English

@SebAaltonen Brother, people still pay for the tokens via API or subscriptions, its not free
English
Lmaooo what makes you think people will download open source models and use it themselves 🤣🤣, AI is not just the models, its the harness and the integrations that have to be built separately as well
Sebastian Aaltonen@SebAaltonen
Tiny (4GB) open source LLM models already match GPT 4.0. You can download one and run it for free on your entry-level GPU (runs on iGPU too). If these small open source models are good enough for most consumers, they will never become paying customers. That's a big risk.
English
@SebAaltonen @CryptoCyberia And even apple didn't block third party OS on desktops/laptops. There is even a special mode for loading. But no documentation. Developers must do reverse engineering.
English
@CryptoCyberia First of all, the image is 100% BS. Makes zero sense. Second, the ARM instruction set isn't locked down. It's entirely up to the CPU manufacturer to make these decisions. Of course Apple is locked down, but that's just a single ARM CPU manufacturer.
English

I feel like privacy advocates don't talk about how shitty and locked down ARM chips are.
While x86 allows for installing whatever operation system you want, ARM chips lack this flexibility so that OEMs can continue to force you to buy a new device every 5 years.

English
@JohnDekkaTech @thdxr Some time in the future people will learn that llms don't have self awareness
English



@silly_images @SmokeyStack_ They think that all laptops are MacBooks
English

@SmokeyStack_ ????? Intel integrated graphics supports Vulkan. what are they talking about
English

😭There are people in the official MC Discord conspiring that Mojang is switching to Vulkan to kill off Minecraft on laptops and force players to use NVIDIA cloud gaming services.
English