
Zhiwei He
237 posts


HKD 100B+ valuation on day one of IPO. We are the only tech-sector Hong Kong IPO in four years to surge over 100%!
What a day to remember. M2.2 &2.5 are coming soon!
MiniMax (official)@MiniMax_AI
From 0 to 0100.HK: MiniMax is officially listed on the Hong Kong Stock Exchange. Built on one belief: Intelligence with Everyone. We believe advanced AI should be accessible and beneficial to a wide range of users and industries. This guiding principle underscores everything we do: from research and development to how we engage with our users and partners. This isn’t the finish line. It’s fuel for our next leap toward AGI. Thank you to the millions of users & developers building and innovating with us every day ❤️ #MiniMax #IntelligenceWithEveryone #IPO
English
Zhiwei He retweetledi

🤖Introducing OptimalThinkingBench 🤖
📝: arxiv.org/abs/2508.13141
- Thinking LLMs use a lot of tokens & overthink; non-thinking LLMs underthink & underperform.
- We introduce a benchmark which scores models in the quest to find the best mix.
- OptimalThinkingBench reports the F1 score mixing OverThinkingBench (simple queries in 72 domains) & UnderThinkingBench (11 challenging reasoning tasks).
- We evaluate 33 different SOTA models & find improvements are needed!
🧵1/5

English
Zhiwei He retweetledi

Are RL agents truly learning to reason, or just finding lucky shortcuts? 🤔
Introducing RLVMR: Reinforcement Learning with Verifiable Meta-Reasoning Rewards — a novel framework that rewards not just outcomes, but the quality of reasoning itself, creating more robust and generalizable agents.
1️⃣ We identify "inefficient exploration" in standard RL: agents achieve success through flawed reasoning paths (e.g., repetitive actions, illogical steps), leading to brittle policies that fail on new tasks.
2️⃣ RLVMR provides dense, process-level rewards for verifiable meta-reasoning behaviors:
• 🎯 Planning: Reward strategic thinking
• 🔍 Exploration: Reward discovering new states
• 💭 Reflection: Reward error correction
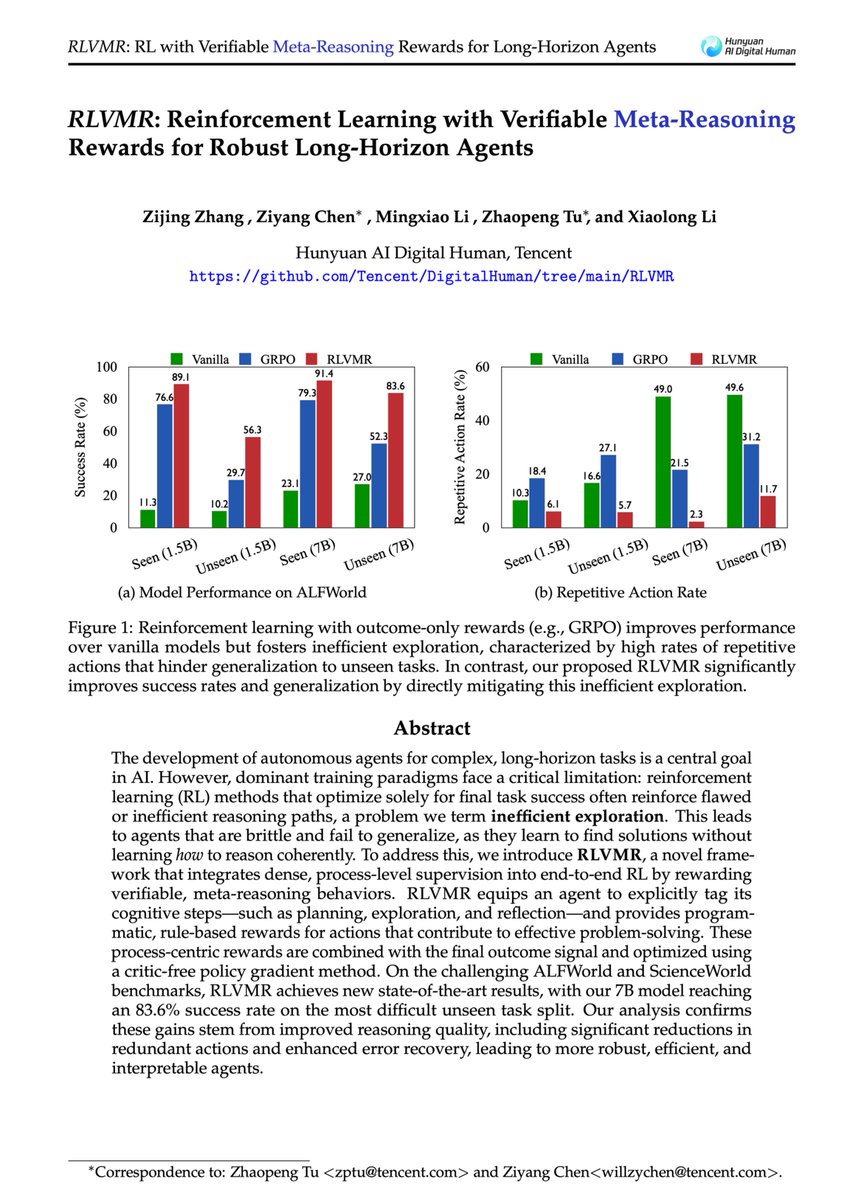
3️⃣ Results on ALFWorld & ScienceWorld:
• 🏆 New SOTA: 83.6% success on hardest unseen tasks (7B model)
• 📉 Significant reduction in repetitive actions
• 🚀 Enhanced generalization to novel scenarios
🧑💻 Code: github.com/Tencent/Digita…
📃 Paper: arxiv.org/abs/2507.22844
English

🚨 New release: MegaScience
The largest & highest-quality post-training dataset for scientific reasoning is now open-sourced (1.25M QA pairs)!
📈 Trained models outperform official Instruct baselines
🔬 Covers 7+ disciplines with university-level textbook-grade QA
📄 Paper: huggingface.co/papers/2507.16…
🤖 Data & Models : huggingface.co/MegaScience
💻 Code: github.com/GAIR-NLP/MegaS…
🎯Evaluation System: github.com/GAIR-NLP/lm-op…
Details 🧵👇
1. Why MegaScience?
While LLMs like o1 and DeepSeek-R1 excel at math & code, they still struggle with science reasoning — largely due to the lack of large-scale, high-quality datasets.
2. What makes MegaScience different?
We address 4 core challenges:
🧪 Unreliable benchmark evaluation
☢️ Less rigorous decontamination
❌ Low-quality reference answers
🧠 Superficial knowledge (data) distillation
3. We tackle this from the ground up.
First, we introduce TextbookReasoning:
📘 Built from 128K+ university-level science textbooks
⚙️ Fully automated LLM-driven pipeline
🧠 650K QA pairs with reliable reference answers
🌍 Covers 7 major disciplines
4. But we didn’t stop there.
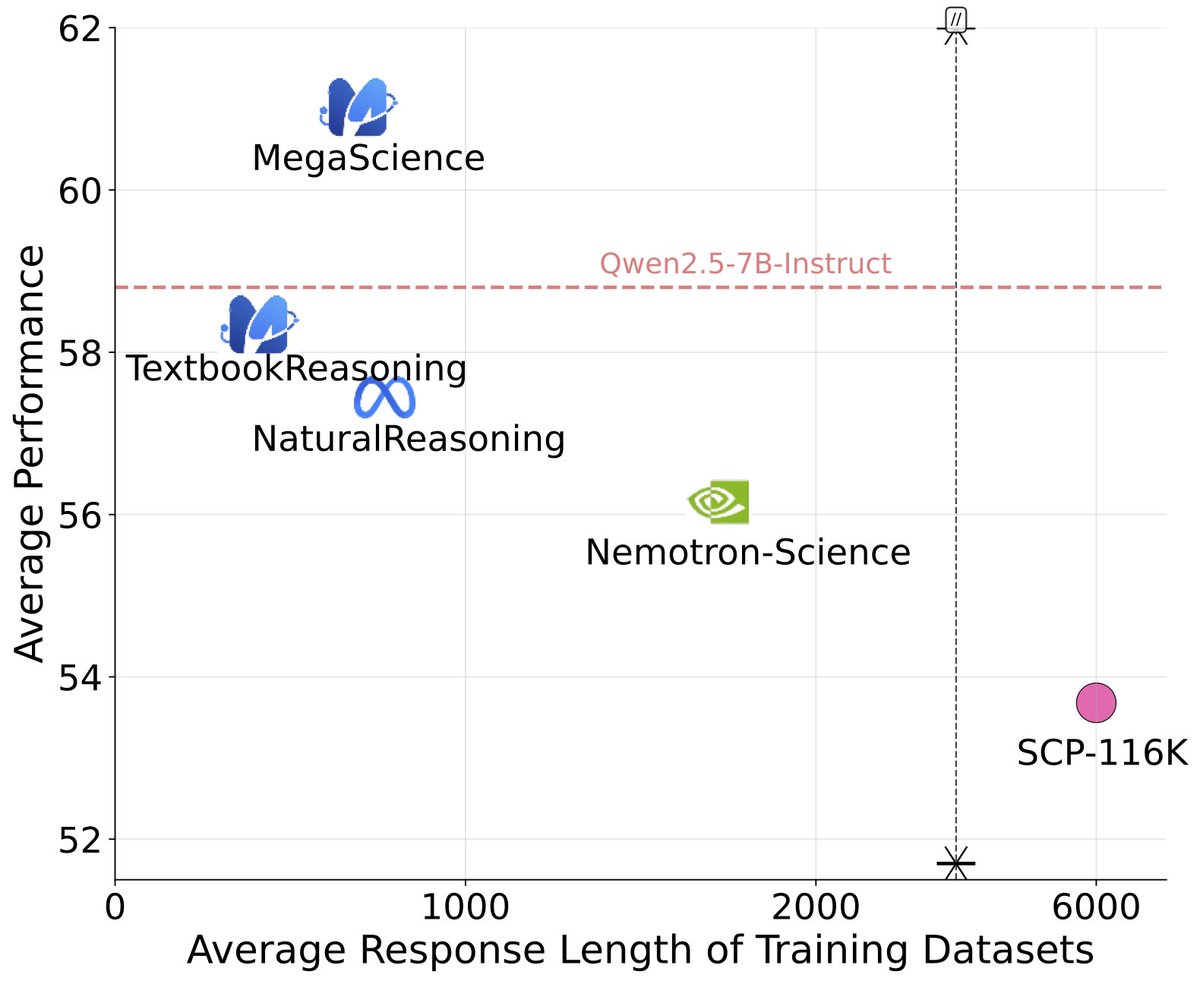
We then construct MegaScience — a diverse, hybrid dataset of 1.25M QA pairs, using:
* TextbookReasoning
* NaturalReasoning
* Nemotron-Science
We conduct comprehensive ablation studies across different data selection methods to identify the optimal approach for each dataset, thereby contributing high-quality subsets.
5. To evaluate properly, we also open-sourced a reproducible and flexible Scientific Reasoning Evaluation framework with:
* 15 science reasoning tasks
* Multiple question formats (MCQ, calc, open-ended)
* Multi-GPU parallelism & model-agnostic evaluation
* Comprehensive answer extraction strategies
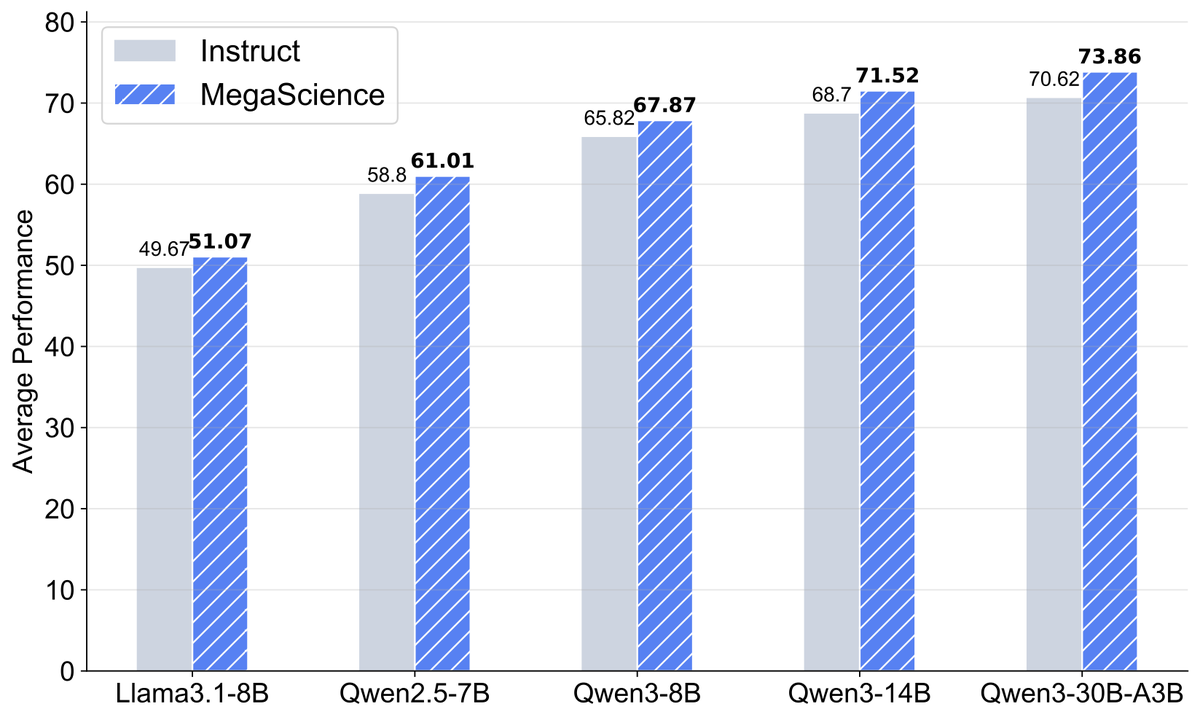
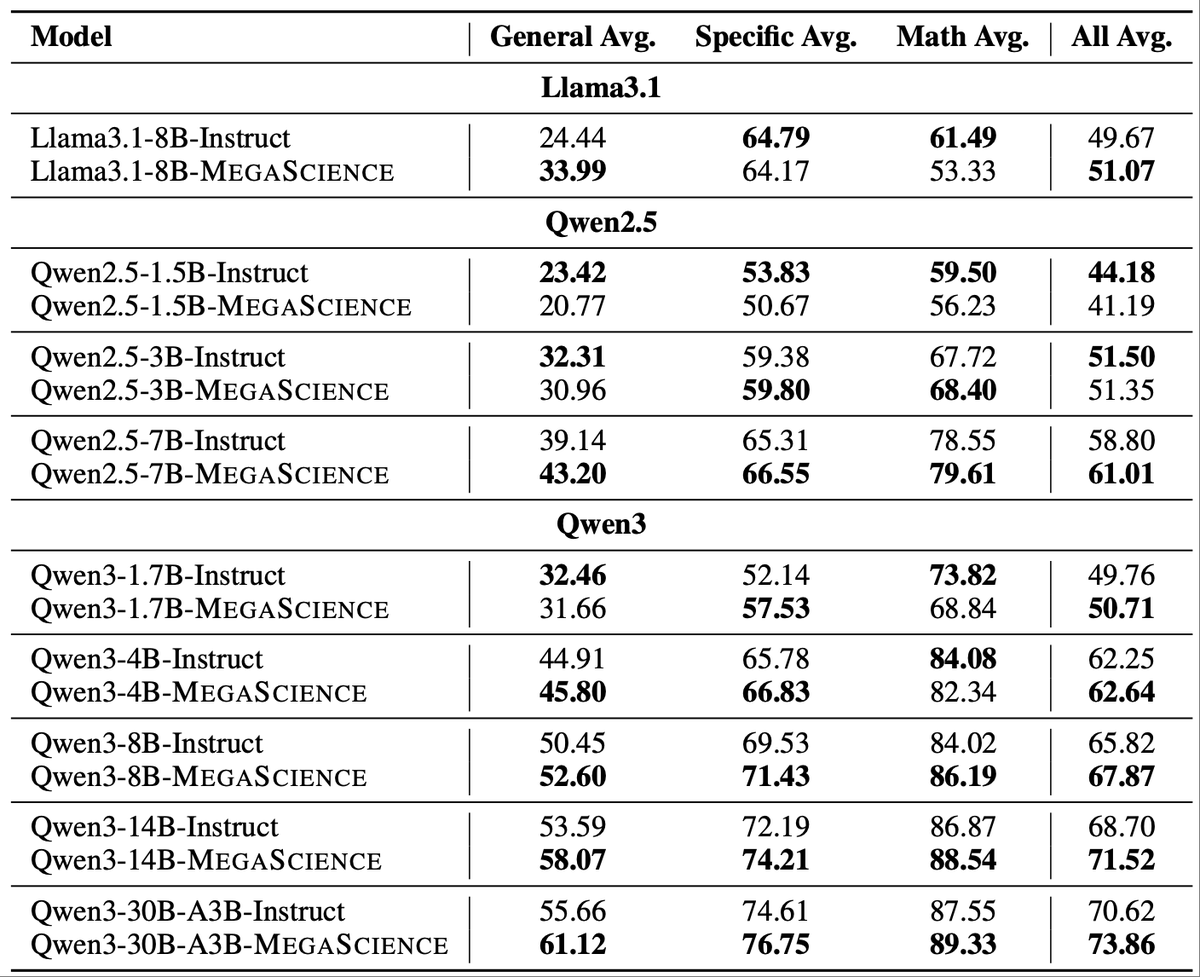
6. Results:
Models trained on MegaScience consistently outperform official Instruct versions — especially for Qwen3 series.
Bigger models see greater gains, showing strong scalability.
7. Everything is open-source:
📚 Dataset
🧪 Evaluation toolkit
🤖 Trained models
🔧 Codebase
→ Let’s build better science agents together!
This work is impossible without all the brilliant co-authors @SinclairWang1 @stefan_fee
English
Zhiwei He retweetledi

Pruning is an effective way to speed up LLM inference. However, most existing methods are static. In our #ICML 2025 paper, we propose a novel dynamic pruning method, which achieves comparable or even better performance than the base model despite a 40% reduction in parameters.


English
Zhiwei He retweetledi
We've taught LLMs math and code with RLVR. But can we teach them empathy? 🤖❤️
Introducing Reinforcement Learning with Verifiable Emotion Rewards (RLVER), the first RLVR framework that enhances LLMs' empathy from a simulated user .
❤️ Feelings → Numbers: A psychologically-grounded user simulator (SAGE) delivers transparent, deterministic, audit-ready emotion scores after every dialogue, turning "feelings" into RL signals.
🚀 Results: an open-source 7B model’s Sentient-Benchmark score leaps from 13.3 ➡️ 79.2, rivaling proprietary models 10× its size while preserving coding & math skills.
🧐 Training Insights
1⃣ Thinking vs. non-thinking routes diverge: thinking lifts empathy/insight; non-thinking favors action.
2⃣ GRPO = steadier gains, PPO = higher peaks.
3⃣ Moderately challenging environments beat overly hard ones for EQ growth.
🤝 We’re open-sourcing code, checkpoints, and scripts to accelerate research into emotionally intelligent AI!
🧑💻 Code & Model: github.com/Tencent/Digita…
📃 Paper:
github.com/Tencent/Digita…

Zhaopeng Tu@tuzhaopeng
Can today's LLMs truly understand you, not just your words? 🤖❤️ Introducing SAGE: Sentient Agent as a Judge — the first evaluation framework that uses sentient agents to simulate human emotional dynamics and inner reasoning for assessing social cognition in LLM conversations. 🧠 We propose an automated "sentient-in-the-loop" framework that stress-tests an LLM's ability to read emotions, infer hidden intentions, and reply with genuine empathy. 🤝 Across 100 supportive-dialogue scenarios, sentient emotion scores strongly align with human-centric measures (BLRI: r = 0.82; empathy metrics: r = 0.79), confirming psychological validity. 📈 The Sentient Leaderboard reveals significant ranking differences from conventional leaderboards (like Arena), showing that top "helpful" models aren't always the most socially adept. 🏆 Advanced social reasoning doesn’t require verbosity — the most socially adept LLMs achieve empathy with surprisingly efficient token usage! Code: github.com/tencent/digita… 🧑💻 Paper: dx.doi.org/10.13140/RG.2.… 🧵
English
Zhiwei He retweetledi

🚀 Atomic-to-Compositional Generalization for Mobile Agents
🧠 A new benchmark & scheduling system to push the limits of mobile agens.
📄 Paper: arxiv.org/abs/2506.08972
🌐 Website: ui-nexus.github.io
🧵1/n
English
Zhiwei He retweetledi

🚀 Check out our paper: WebEvolver: Enhancing Web Agent Self-Improvement with Coevolving World Model, from Tencent AI Lab!.
We present a world model-driven framework for self-improving web agents, addressing critical challenges in self-training—such as limited exploration and performance plateaus.
🔍 Key Innovations:
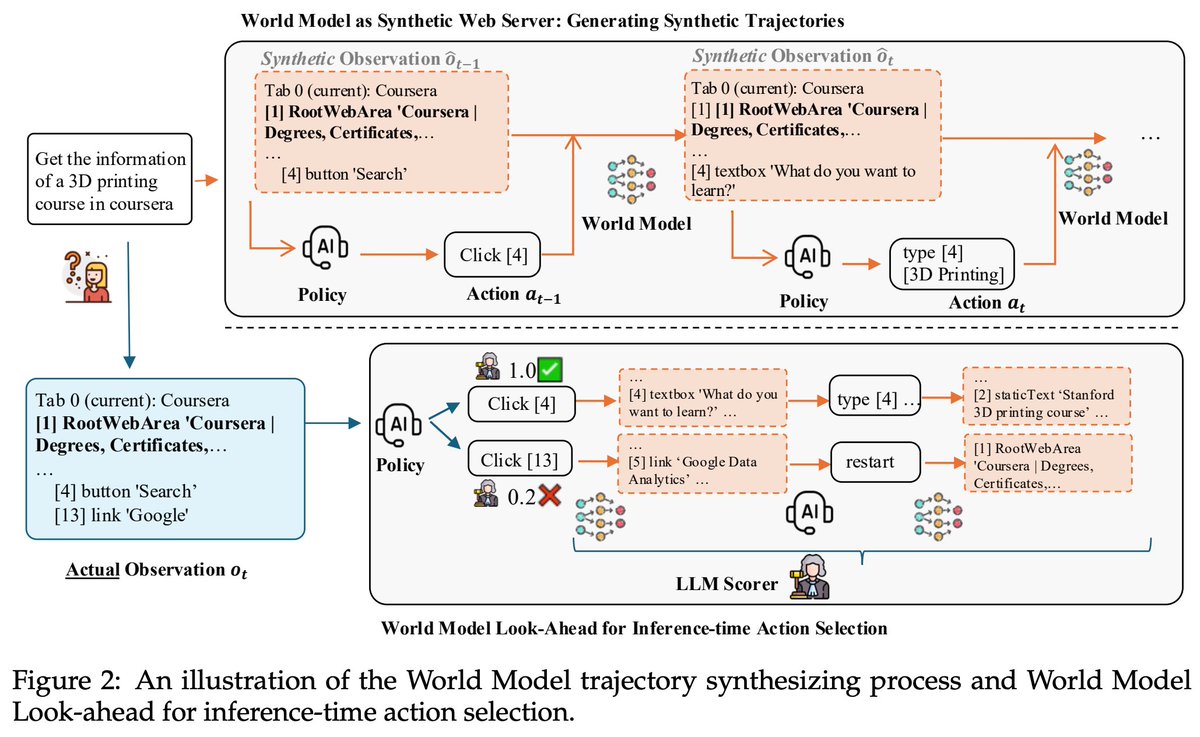
- Co-Evolving World Model:
The world model is implemented as an LLM that predicts the next webpage state (observation) given the current state and a planned action.
In addition to fine-tuning the agent's policy model using self-generated trajectories, the same data is repurposed to train the world model.
- World Model as Web Server
Training Phase: sample pseudo trajectories by replacing the real web server with the world model.
Inference Phase: simulate the outcome of candidate actions with 1-2 step look-ahead planning, to help better select actions.
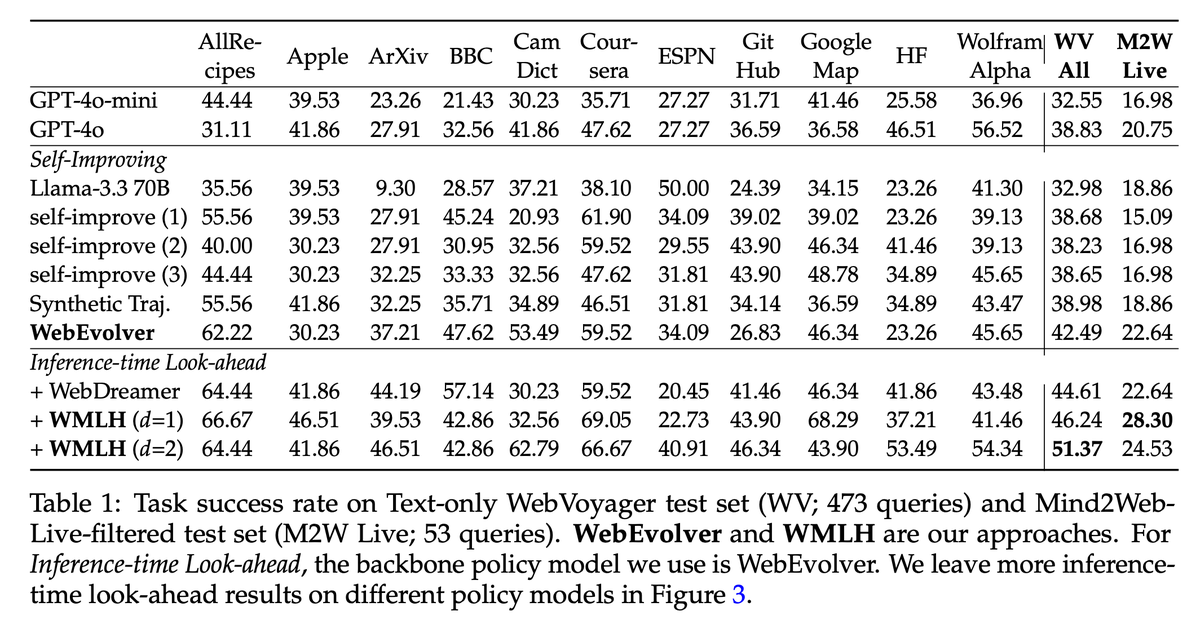
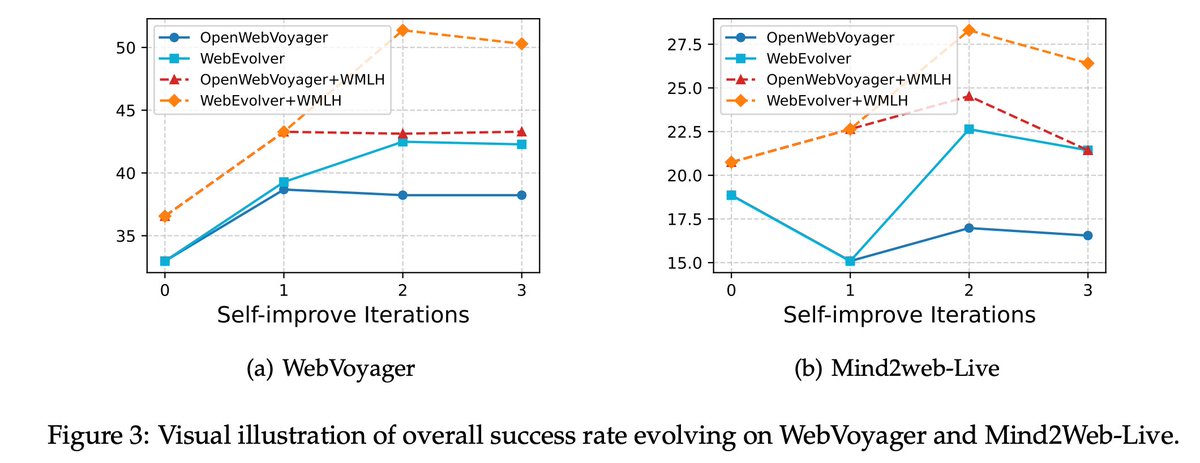
📊 Results on Real-World Tasks (Mind2Web-Live & WebVoyager):
✅ ~10% higher success rate vs. pure self-training.
✅ significantly fewer environment interactions—efficient yet powerful!
arxiv: arxiv.org/pdf/2504.21024
code: github.com/Tencent/SelfEv…

English
Thanks for adopting DeepMath-103K! It's great to have both RLVR and agentic RL support!
wang@weixunwang
🚀 Introducing ROLL: An Efficient and User-Friendly RL Training Framework for Large-Scale Learning! 🔥 Efficient, Scalable & Flexible – Train 200B+ models with 5D parallelism (TP/PP/CP/EP/DP), seamless vLLM/SGLang switching, async multi-env rollout for maximum RL throughput!
English



@gohx0043 @ShenzhiWang_THU I mean... the base models have neither thinking nor non-thinking modes.
English

@zwhe99 @ShenzhiWang_THU @zwhe99 thank you very much for your reply! appreciate that! do you think non-thinking mode is used for both training and eval?
English

🚨Beyond 80/20 in LLM reasoning🚨Dropping 80% low-entropy tokens in RL greatly boosts performance
🔗arxiv.org/abs/2506.01939
🏆Zero-RL SoTA: 63.5/68.1 (AIME24), 56.7 (AIME25)
🚀Insights:
1. RL retains base model entropy patterns
2. High-entropy tokens drive all RL improvement
⬇️
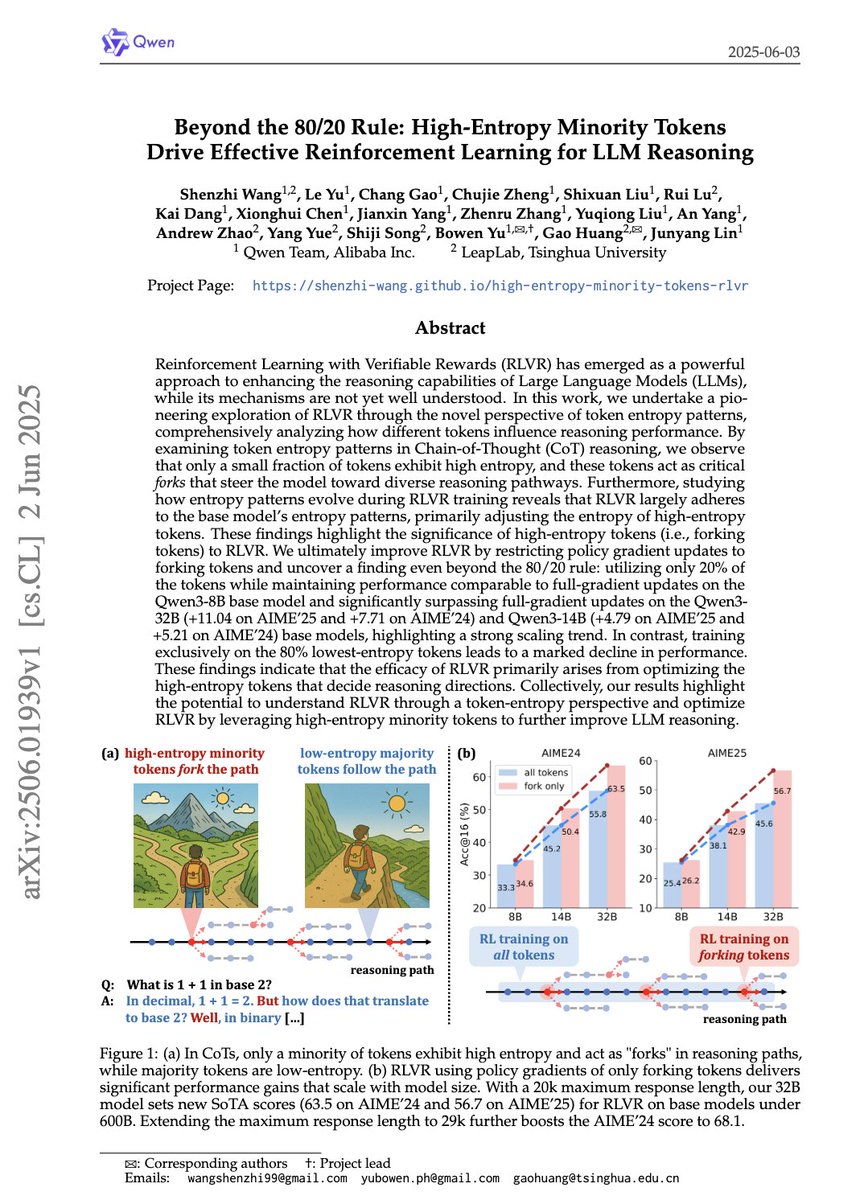

English
@gohx0043 @ShenzhiWang_THU I think they used the base models which do not have the thinking mode.
English
@ShenzhiWang_THU Hi @ShenzhiWang_THU , this is an insightful work. I notice that you are using Qwen 3 as the model. I wondered if you have switched on / off the thinking mode during the train / eval. Also, I notice the decline of baseline after appx 1000 steps? May I know if it's normal?

English
Zhiwei He retweetledi

This year, there have been various pieces of evidence that AI agents are starting to be able to conduct scientific research and produce papers end-to-end, at a level where some of these generated papers were already accepted by top-tier conferences/workshops.
Intology’s AI-generated paper getting accepted by ACL is one example: x.com/IntologyAI/sta…
In fact, three independent teams submitted AI-generated papers to ICLR’25 workshops and got some of them accepted:
Sakana: x.com/SakanaAILabs/s…
AutoScience: x.com/AutoScienceAI/…
Intology: x.com/IntologyAI/sta…
We will probably continue to see AI-generated submissions at various conferences/journals, and maybe more will be accepted. But what does it tell us? Are LLMs already better than us human researchers? Here are my two cents:
1. I do believe LLMs will be able to automate parts of our research pipeline, and this could be a good thing.
It seems that directly building agent scaffolds on top of current LLMs can already get you some non-trivial results (all of the above systems use agent scaffolds on top of commercial LLM APIs).
Not to mention that there has been a thrust of recent efforts on building research agent environments with objective rewards (e.g., benchmark performances): RE-Bench, MLE-Bench, PaperBench, MLGym, MLE-Dojo, just to name a few.
Just like the rapid development of coding agents, I believe research execution agents will keep getting better as we develop better training algorithms (e.g., RL) on these environments and as we have more capable base models to work with.
And I think this is good for us because we can offload some of the tedious implementation work to these agents to speed up our research once they start to get reliable.
2. Producing research papers end-to-end and submitting AI-generated papers to conferences, on the other hand, is bad in many ways.
For these research agent developers, submitting AI papers to peer review is a terrible way to do evaluation. Whether you like it or not, you have to admit that conference reviewing can be quite noisy. And I just don’t see how you can make any statistically meaningful conclusions from the result of this one single paper acceptance in this noisy reviewing process, not to mention all the extra burden you are imposing on our (already partially broken) conference reviewing system.
For the broader scientific community, I just don’t think the purpose of building AI Scientists is to produce thousands of mediocre research papers that may have a chance of passing the conference thresholds. Getting a paper accepted is one thing; actually pushing the frontier of human knowledge is a completely different matter. Our community will be doomed if everyone (including the AI Scientists) treats conference acceptances as the only reward function. For all of us working on AI Scientists, I think the right goal we should be pursuing, is how AI Scientists can help us make scientific breakthroughs that we humans alone wouldn’t be able to achieve, rather than hacking flawed reward functions.
This is not an easy post to write because I know all of these teams working on AI Scientists personally, and these are some really smart people that I deeply respect. If there’s only one message to take away from this post, I hope all of us working on AI Scientists can work towards the right objectives and try to make this world a better place. ❤️
English
Zhiwei He retweetledi

🚨 Announcing DeepTheorem: Revolutionizing LLM Mathematical Reasoning! 🚀
𝕋𝕃𝔻ℝ:
- 🌟 Learning by exploration is the most important rationale that recent RL-zero training teaches us since self-exploration significantly boosts the utilization of LLM pre-training knowledge;
- 🧐 Since LLM is pre-trained with massive knowledge of mathematical theorems, can LLM learns theorem proving by self-exploration?
- 🤯 We show that using our high-quality deep theorem dataset with online RL learning is sufficient to activate LLM's theorem-proving ability. Our 7B model can outperform even advanced models like **Gemini** and **Claude 3.5**! More importantly, we don't need any theorem proof annotation, all you need is the truth value of the theorem itself.
- 📄Come and check our paper:
Arxiv: arxiv.org/abs/2505.23754
Huggingface: huggingface.co/datasets/Jiaha…

English

@zwhe99 Also note that vLLM is non-deterministic and has 3-7% run-to-run variations for Qwen Math on MATH-500, even in greedy decoding.
English
This post really resonates with me—evaluation is so crucial yet so challenging. Let me share some experiences from our DeepMath-103K project:
We've noticed multiple works reporting results in rather "tricky" ways. For instance, using greedy decoding + selecting the checkpoint with highest AIME24 score. As we know, benchmarks like AIME24 (with only 30 problems) show high variance under greedy decoding (just changing the training seed or step can cause significant fluctuations).
This leads to two issues:
1. Performance drops noticeably (~10 points) when switching to temperature-based sampling
2. While AIME24 results look great, other benchmarks (AIME25, OlympiadBench, etc.) show almost no improvement.
BTW, working on DeepMath made me realize how thorough our evaluation approach was:
1. We rigorously decontaminated data based on semantics across 10+ benchmarks
2.Aligned prompt templates with those used in baseline models' training
3. When our baseline reproductions fell significantly short of reported results, we either contacted authors or investigated GitHub issues (often finding others couldn't reproduce either)
For reference:
Our evaluation shows Qwen-2.5-7B achieves 54.8 on MATH500, higher than Spurious Rewards (41.6) and Entropy Minimization (43.8), but lower than Sober Look (64.6). Interestingly, Qwen's TR only reports 49.8 on MATH.
Our Qwen-2.5-Math-7B reaches 46.9, higher than LRM-Self-train (~42), but still lower than Sober Look (64.3). Qwen's TR reports 55.4 on MATH (4-shot).
R1-Distill-Qwen-1.5B reaches 84.7, higher than 1-shot RLVR(71.9), and match Sober Look (84.9).
arxiv.org/pdf/2504.11456

Shashwat Goel@ShashwatGoel7
Confused about recent LLM RL results where models improve without any ground-truth signal? We were too. Until we looked at the reported numbers of the Pre-RL models and realized they were serverely underreported across papers. We compiled discrepancies in a blog below🧵👇
English