
Slobo | slobo.eth
3K posts

Slobo | slobo.eth
@AlexSlobodnik
I like hiking, coffee, and croissants. I contribute to ENS, the protocol that turns 0x addresses into usernames you can remember. Avid user of Claude Code.
nyc Entrou em Mart 2016
497 Seguindo2.4K Seguidores

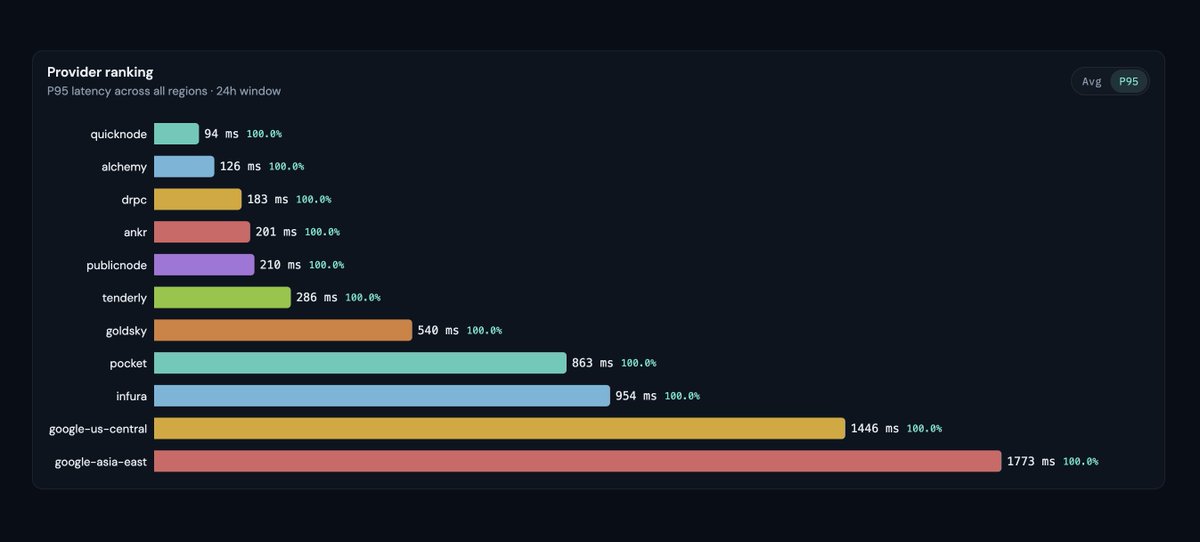
i built a dashboard to monitor 11 rpc provider's latency across 4 regions
findings:
- alchemy is fastest in asia
- quicknode is fastest in europe, us-east and us-west
that being said, quicknode is the only one on the list without a PAYG tier which sucks for hobby devs
English
@bryan_johnson all man's ill stem from their inability to sit in a room and do nothing
or missing your bedtime
English

Sometimes I wonder if I've just built the world's most sophisticated way to avoid sitting in a room with nothing to measure.
English
@moms_pearl_neck @zamdoteth well, that's not very nice
English


@stevesi only to have your resume screened out by a misfiring ai
English

What do folks think?
(name redacted because they used a real person)

English


@ChanningAllen @CryptoValueLabs your tos & privacy policy 404
English

@CryptoValueLabs Vibe coded? We're the founders behind the biggest (arguably) startup community in the world.
English
We built an app called Hatch
It enables Karpathy's entire LLM Knowledge Base workflow out of the box, in 2 or 3 clicks, in a single interface.
No need to stitch together Obsidian + plugins + markdown files + custom tools + etc.
Hatch is an AI workspace where files, docs, and chats all live together. Not only can the chats READ files and docs, but they can WRITE and ORGANIZE them as well.
This means you can set up an LLM Wiki in literally 3 steps, as I show in this video.
Andrej Karpathy@karpathy
LLM Knowledge Bases Something I'm finding very useful recently: using LLMs to build personal knowledge bases for various topics of research interest. In this way, a large fraction of my recent token throughput is going less into manipulating code, and more into manipulating knowledge (stored as markdown and images). The latest LLMs are quite good at it. So: Data ingest: I index source documents (articles, papers, repos, datasets, images, etc.) into a raw/ directory, then I use an LLM to incrementally "compile" a wiki, which is just a collection of .md files in a directory structure. The wiki includes summaries of all the data in raw/, backlinks, and then it categorizes data into concepts, writes articles for them, and links them all. To convert web articles into .md files I like to use the Obsidian Web Clipper extension, and then I also use a hotkey to download all the related images to local so that my LLM can easily reference them. IDE: I use Obsidian as the IDE "frontend" where I can view the raw data, the the compiled wiki, and the derived visualizations. Important to note that the LLM writes and maintains all of the data of the wiki, I rarely touch it directly. I've played with a few Obsidian plugins to render and view data in other ways (e.g. Marp for slides). Q&A: Where things get interesting is that once your wiki is big enough (e.g. mine on some recent research is ~100 articles and ~400K words), you can ask your LLM agent all kinds of complex questions against the wiki, and it will go off, research the answers, etc. I thought I had to reach for fancy RAG, but the LLM has been pretty good about auto-maintaining index files and brief summaries of all the documents and it reads all the important related data fairly easily at this ~small scale. Output: Instead of getting answers in text/terminal, I like to have it render markdown files for me, or slide shows (Marp format), or matplotlib images, all of which I then view again in Obsidian. You can imagine many other visual output formats depending on the query. Often, I end up "filing" the outputs back into the wiki to enhance it for further queries. So my own explorations and queries always "add up" in the knowledge base. Linting: I've run some LLM "health checks" over the wiki to e.g. find inconsistent data, impute missing data (with web searchers), find interesting connections for new article candidates, etc., to incrementally clean up the wiki and enhance its overall data integrity. The LLMs are quite good at suggesting further questions to ask and look into. Extra tools: I find myself developing additional tools to process the data, e.g. I vibe coded a small and naive search engine over the wiki, which I both use directly (in a web ui), but more often I want to hand it off to an LLM via CLI as a tool for larger queries. Further explorations: As the repo grows, the natural desire is to also think about synthetic data generation + finetuning to have your LLM "know" the data in its weights instead of just context windows. TLDR: raw data from a given number of sources is collected, then compiled by an LLM into a .md wiki, then operated on by various CLIs by the LLM to do Q&A and to incrementally enhance the wiki, and all of it viewable in Obsidian. You rarely ever write or edit the wiki manually, it's the domain of the LLM. I think there is room here for an incredible new product instead of a hacky collection of scripts.
English




Zuck has been an absolute disaster of a leader past few years
-metaverse (massive miss)
-ai (early but massive miss)
-scale aquihire (massive miss)
Speaking to some senior folks at the co it seems everyone (directors alike) are genuinely worried abt their jobs and what’s next due to massive swings in priority and horrible WLB with no direction
Not kidding, it’s time for meta to have a real conversation about a CEO who can operate. Zuck is missing the Mark pun intended.
English
@Bencera "AI that runs your company while you sleep"
More sleep, more run time...
English


A billion dollars isn’t cool. You know what is?
A trillion.
English

TV reporter tells David Bowie the internet is "hugely exaggerated"
David Bowie's response is the closest thing to perfection about the future.
English
@paolino claude code is a lot more fun to use
i find using both is best
English

I've been watching this since the first Codex dropped. There's no comparison. Codex is miles ahead of Claude Code.
But the narrative won't stop. Which tells me people didn't actually try Codex before confidently declaring a winner.
Even Opus 4.6 on max effort hallucinates constantly, confidently. Not on maxed out contexts, on fresh conversations.
Today: hallucinated results it should have searched. Blindly changed one without verifying. Searched but got the wrong answer. Then doubled down on a mistake it already made. Just a mess. 20 minutes for a simple row of feature comparisons.
Codex: searched everything, found nuance, suggested ways to represent it in the table. One shot.
English
@nxt3d cluade for fun & rapid prototyping codex for prod
English

I have been hearing that Codex is really smart, but I had not experienced it until now. I was working on creating the core calendar and heartbeat system for ID Agents, and Claude Code was very eager to build it, but it didn’t really seem like it knew the best way to do it. Codex was much more contrarian, said that my idea was okay but not optimal, and came up with a new design that seemed a lot more elegant, based on its understanding of industry standards.
My personal team of AI agents, mostly Claude Code CLIs, is now led by a CTO, Codex CLI.
English
"the day after tomorrow"
i've never heard anyone say this in a real conversation, yet sitcoms, dramas, and comedies all use this phrasing
odd phrasing increases cognitive load thus making content feel interest
English
@benjaminprinter founders care about growth, employees care about avoiding losses
incentives of the target drive the structure of the pitch
English

Every mf with a case study could sign a $50K deal if they reframed it from being a ‘success story’
Buyers in B2B don’t give a shit about upside
When you say:
“We helped Client go from X and grow their revenue by 42% in 6 months”
The buyer is forced to imagine their current situation and change it to a better future on the basis of a possibility
The problem is they aren’t currently experiencing it
So it’s just a vague claim to consider
Which makes it optional
So they can appreciate it without needing to pay you because nothing about their current reality is forcing them to move forward
In B2B environments there are always careers on the line and political decisions being made
No one gets fired for missing a ‘growth opportunity’
But people definitely get fired for missing something that could have been prevented
So if your case studies are framed around growth, they’re still optional
But when you simply reframe them around the angle of ‘We helped the exec team avoid a $4.8M blind spot that they hadn’t realised in 36 months”
They can defend your offer
This is a formula you can apply to every single case study that you have
Because the general formula is
- Before
- After
- Result
When you can simply reframe the exact same thing to
- Hidden Problem
- Escalation
- Near Failure
- Intervention
- Stabilization
So an example of this is:
“Mr gayboy client was spending $85K/month on paid channels and thought performance was ‘fine.’
But their funnel was under converting by 30% relative to benchmark, which meant 140 qualified buyers per month were being lost silently.
Over a 5-month period, that translated to roughly $3.5M in missed pipeline.
Which meant the issue was simply how demand was being processed post-click
Once we rebuilt the conversion layer, we tightened up the $3.5M bleed within 90 days.”
So you’re entire proof becomes the fact that you see what others are missing instead of the fact that you can produce upside
Because the fastest way to prove you know what you’re talking about in B2B is always to expose a hidden lose that feels uncomfortable when its revealed
The buyer immediately identifies it because it’s the lie they’ve been avoiding for years
And it becomes the purest driver of urgency
English