Christian Balbin retweetou

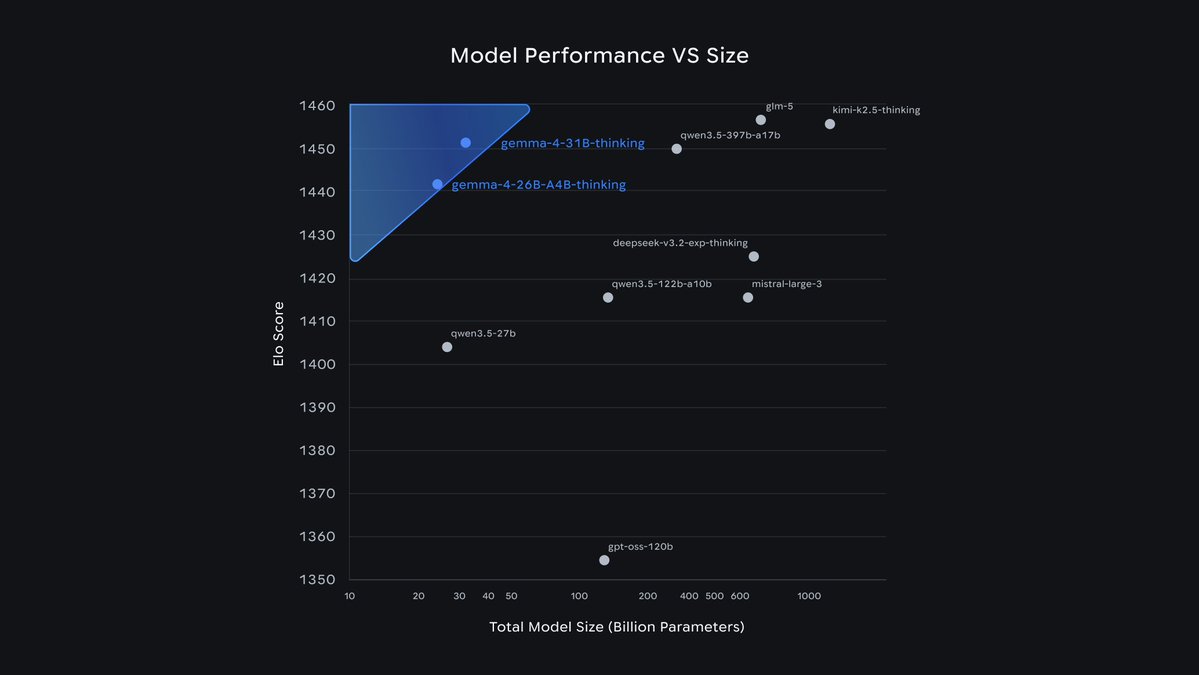
Gemma 4 31B vs Qwen3.5 27B: Inference Throughput
RTX Pro 6000 (vLLM; 8k input tokens; 64k output tokens):
- Qwen3.5 27B: 45 tok/sec with MTP (17.9 tok/sec without MTP)
- Gemma 4 31B: 12.3 tok/sec
The gap is large. But still, end-to-end, Gemma 4 31B remains faster since it generates fewer tokens. Will publish more about this soon.
Eagle support for Gemma 4 31B is also coming to vLLM and should significantly accelerate inference.
English