AboveSpec
287 posts


AboveSpec
@above_spec
Love 3d printing, playing with local llms and learning Claude Code


update on mylocal agent stack (RTX 4060 Ti 8 GB, Qwen3.6-35B-A3B Q4_K_M) my initial problem was that 64K context on standard llama.cpp killed speed. V cache q4_0 pushed graph splits from 62 → 82, and Hermes decode dropped from 31 → 9-11 tok/s. unusable for real agent work. some people in comments recommended trying turboquant fork. turbo2/turbo3 KV cache types keep 62 graph splits at 64K context. auto-asymmetric: K stays q8_0, only V gets compressed. turbo3 wins. same speed as 32K config but double the context window. usable context in Hermes jumps from ~18.5K to ~50.5K. new daily-driver config: -ngl 999 -ncmoe 30 -c 65536 -np 1 -fa on --cache type-k q8_0 --cache-type-v turbo3 8 GB VRAM is not dead. you need the right fork.


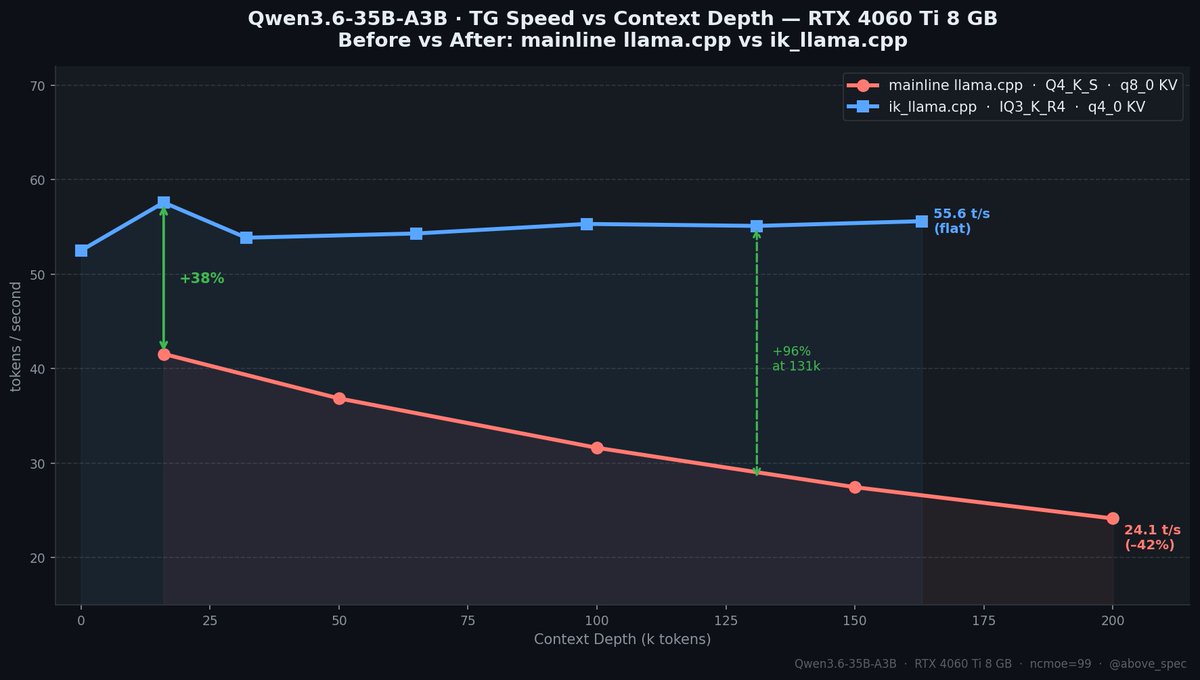
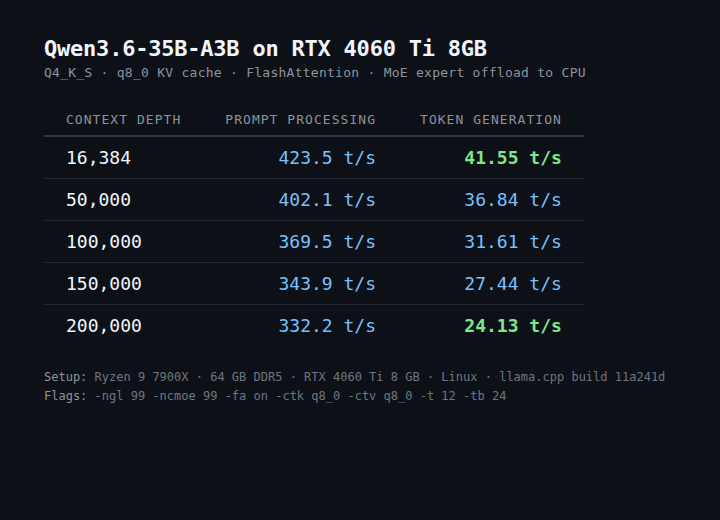
Qwen3.6 35B A3B model. 55+ tokens/sec. $300 GPU. No, this isn't a server card. It's an RTX 4060 Ti 8GB. Previously I posted that I 41 t/s on this gpu and that post blew up and went viral. I went back and made it 34% faster. And now the speed doesn't drop with context depth at all. New benchmarks + what changed 🧵

DS4=DwarfStar4 OpencodeのDS-4VFによればIQ2モデルで単騎推論とすればRTXPro6K対応可能とのことで早速コンパイル完了 モデルをDLする。素晴らしい展開 github.com/antirez/ds4
Quick update on the 35B / 8GB setup. Switched to IQ4_K_R4 — higher quality quant, without losing much speed — getting ~49tok/s through model's full native 262k context. And VRAM usage is low enough to keep a browser with multiple tabs open the whole time. 🧵
now testing real results with Hermes on WSL2



Don’t just scale AI. Scale ROI. AMD Instinct MI350P PCIe cards deliver 144 GB of HBM3E memory and up to 2299 teraFLOPS (at MXFP4) in a drop-in, air-cooled card built for standard servers. That’s how you scale AI at maximum ROI without redesigning your data center. Interested in drop-in AMD Instinct MI350P PCIe cards? See the specs at the link: bit.ly/4exiAg2
Quick update on the 35B / 8GB setup. Switched to IQ4_K_R4 — higher quality quant, without losing much speed — getting ~49tok/s through model's full native 262k context. And VRAM usage is low enough to keep a browser with multiple tabs open the whole time. 🧵




Qwen3.6 35B A3B model. 55+ tokens/sec. $300 GPU. No, this isn't a server card. It's an RTX 4060 Ti 8GB. Previously I posted that I 41 t/s on this gpu and that post blew up and went viral. I went back and made it 34% faster. And now the speed doesn't drop with context depth at all. New benchmarks + what changed 🧵
Quick update on the 35B / 8GB setup. Switched to IQ4_K_R4 — higher quality quant, without losing much speed — getting ~49tok/s through model's full native 262k context. And VRAM usage is low enough to keep a browser with multiple tabs open the whole time. 🧵

study @Teknium: >me asking him the best way to host Hermes on windows >him explaining that WSL2 is the preferred way right now >him sending a previous NousResearch documentation about the set up >him deciding that it is too sparse and reworking the documentation >1 hour later him coming back to me with a very comprehensive tutoral on how tu run Hermes on WSL2 Hermes agent is #1 and there is no second best. for those who are interested in the documentation: hermes-agent.nousresearch.com/docs/user-guid…