
Tweet fixado

Frontier LLMs are converging on efficient, adaptive reasoning. Opus 4.7 lets the model decide how deeply to reason. GPT-5.5 achieves strong results with fewer reasoning tokens.
We study a related but more structural question: what 𝗸𝗶𝗻𝗱 𝗼𝗳 𝗿𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 should we adapt?
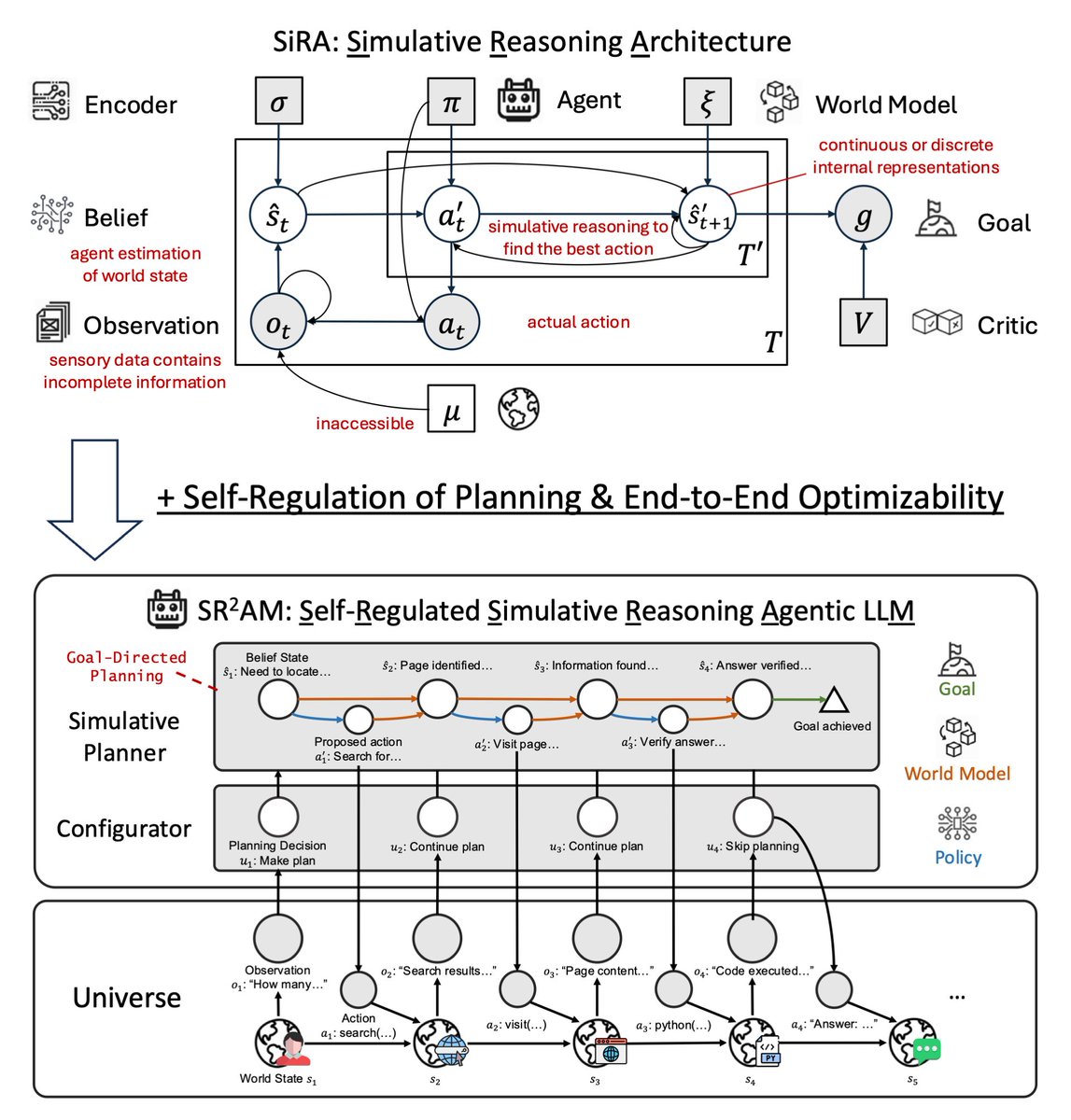
Last year in SiRA (upper figure), we showed that simulative reasoning (System II), which uses a 𝘄𝗼𝗿𝗹𝗱 𝗺𝗼𝗱𝗲𝗹 to evaluate consequences of actions, yields up to 124% improvement over reactive baselines (System I), and that strong reasoning models (o1, o3-mini) fail as planners without this structure.
In our new paper SR²AM (lower figure), we add a learned 𝗰𝗼𝗻𝗳𝗶𝗴𝘂𝗿𝗮𝘁𝗼𝗿 (System III) that self-regulates when to simulate, how far ahead, and when to skip planning entirely.
Efficient reasoning is not just shorter reasoning: it is better allocation of simulation.
English

















