ทวีตที่ปักหมุด

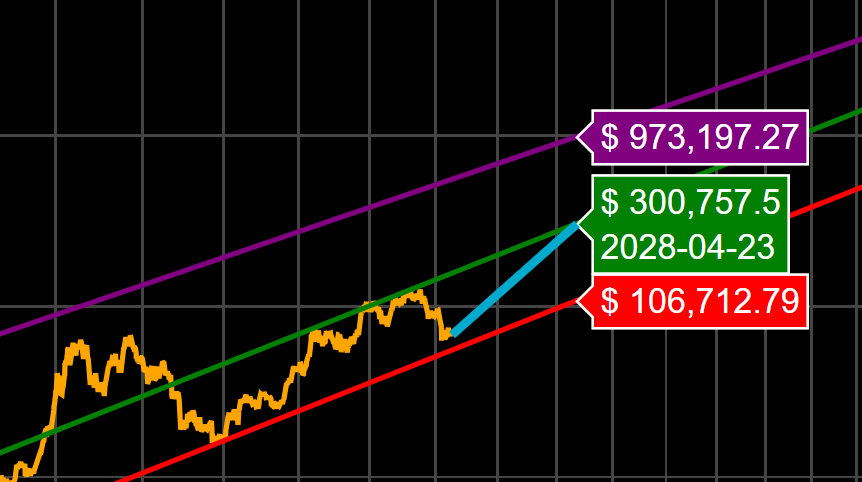
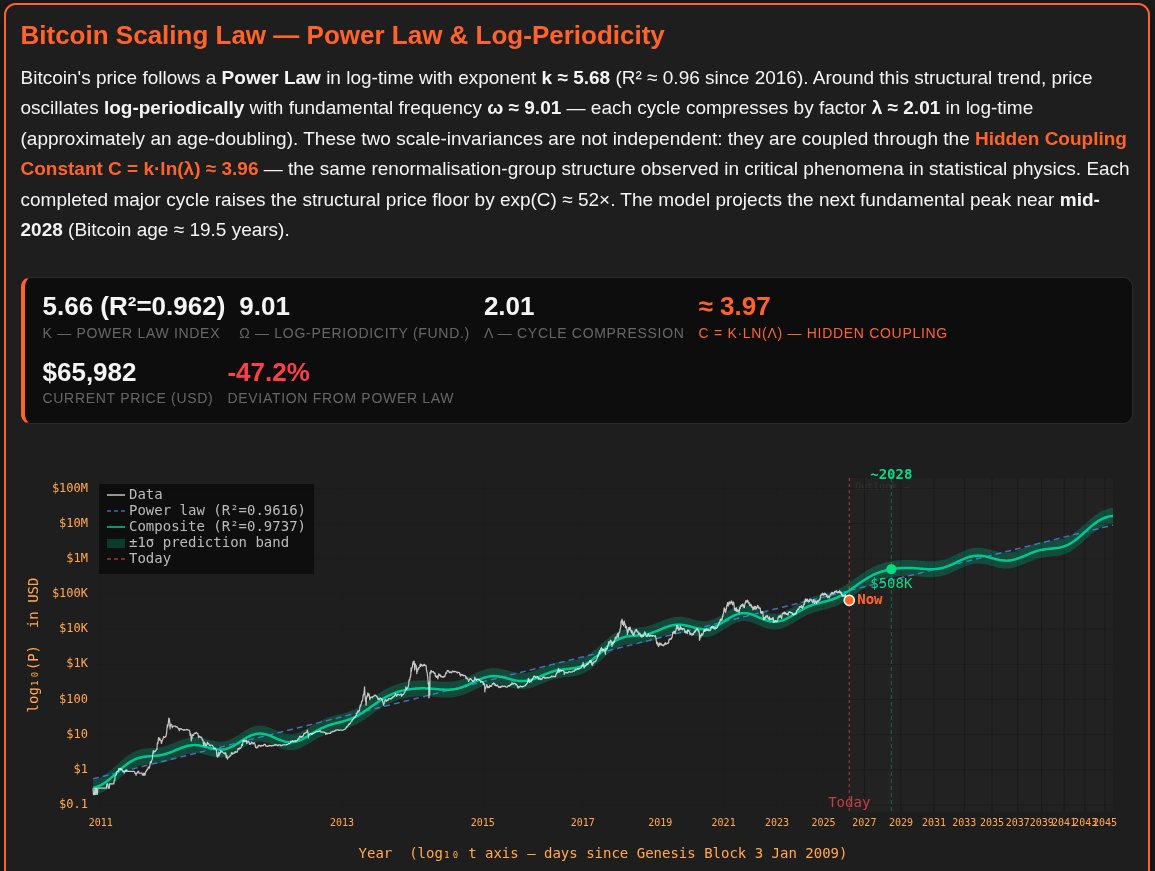
Today, we strongly contest the premature "conclusive high" annotation on the Bitcoin Spiral made famous by @therationalroot . In a robust model, market milestones should be triggered by data, not declared manually.
For this analysis, we rebuilt the Spiral with three upgrades:
- Power Law spine (structural baseline),
- Quantile envelope (probabilistic regimes),
- Historical Decay Ceiling (historical top compression over time).
Link:
x.com/therationalroo…

English