
@joel_bkr This doesn't seem obvious to me, cheaper reviews can also incorrectly reject good solutions.
English
Elizabeth Barnes
279 posts

new @METR_Evals research note from @whitfill_parker, @cherylwoooo, nate rush, and me. (chiefly parker!) we find that *half* of SWE-bench Verified solutions from Sonnet 3.5-to-4.5 generation AIs *which are graded as passing* are rejected by project maintainers.

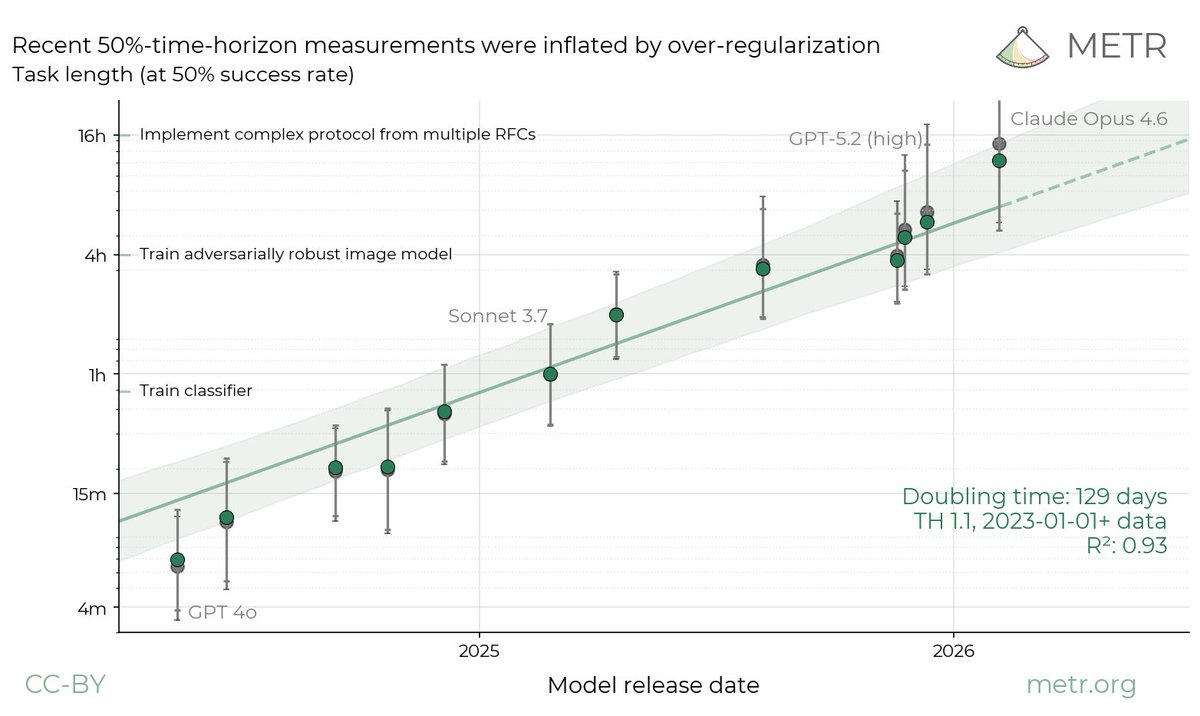
We estimate that Claude Opus 4.6 has a 50%-time-horizon of around 14.5 hours (95% CI of 6 hrs to 98 hrs) on software tasks. While this is the highest point estimate we’ve reported, this measurement is extremely noisy because our current task suite is nearly saturated.



Since early 2025, we've been studying how AI tools impact productivity among developers. Previously, we found a 20% slowdown. That finding is now outdated. Speedups now seem likely, but changes in developer behavior make our new results unreliable. We’re working to address this.

We estimate that Claude Opus 4.6 has a 50%-time-horizon of around 14.5 hours (95% CI of 6 hrs to 98 hrs) on software tasks. While this is the highest point estimate we’ve reported, this measurement is extremely noisy because our current task suite is nearly saturated.

Introducing Locus: the first AI system to outperform human experts at AI R&D Locus conducts research autonomously over multiple days and achieves superhuman results on RE-Bench given the same resources as humans, as well as SOTA performance on GPU kernel & ML engineering tasks. RE-Bench is a collection of several frontier AI research tasks that typically take human experts (e.g., top ML PhDs and frontier lab researchers) several days. By scaling experimentation to far longer time horizons than previous systems, Locus represents a step change in AI scientist capabilities. 🧵
We reviewed Anthropic’s unredacted report and agreed with its assessment of sabotage risks. We want to highlight the greater access & transparency into its redactions provided, which represent a major improvement in how developers engage with external reviewers. Reflections: 🧵




We tested how autonomous AI agents perform on real software tasks from our recent developer productivity RCT. We found a gap between algorithmic scoring and real-world usability that may help explain why AI benchmarks feel disconnected from reality.