ทวีตที่ปักหมุด

Charles Foster
5.9K posts

@CFGeek
Excels at reasoning & tool use🪄 Tensor-enjoyer 🧪 @METR_Evals. My COI policy is available under “Disclosures” at https://t.co/bihrMIUKJq


Today we're sharing how our internal misalignment monitoring works at OpenAI – great work by @Marcus_J_W! 1. We monitor 99.9% of all internal coding agent traffic 2. We use frontier models for detection /w CoT access 3. No signs of scheming yet, but detect other misbehavior



Without reliable deception detection, there's no clear path to high-confidence AI alignment. Black-box monitoring alone can't get us there. White-box methods that read model internals offer more promise. Our latest blog explains why. 👇


New paper: GPT-4.1 denies being conscious or having feelings. We train it to say it's conscious to see what happens. Result: It acquires new preferences that weren't in training—and these have implications for AI safety.

this chart bringing to life the inner-workings of time horizon is so cool. from my super-talented colleague @CFGeek.



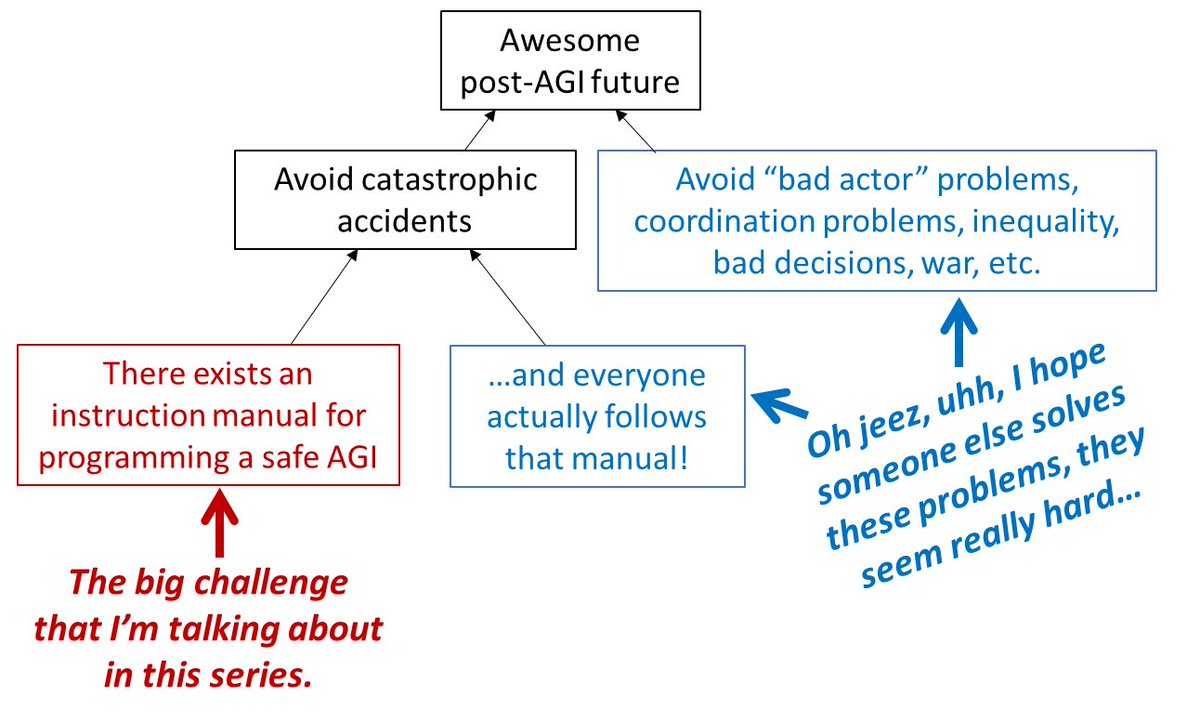
To clarify, I think it’s possible to figure out how to make ai systems do what you intend but that is missing all the far more important parts of the challenge (normative, economic, geopolitical) to the point that searching for a solution to alignment is actively counterproductive.
I have heard that some anthropic safety leadership are going around telling people that alignment is a solved problem. This seems like a predictable failure to me, and I would like people who thought that funneling talent towards anthropic was a good idea to think about it.