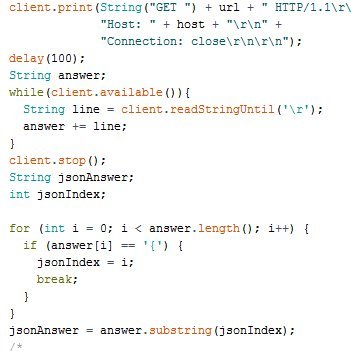
@ESEA @FACEIT @FACEITSupport @FACEITcs 40-50mins late and call 6 admins and we're forced to play the match cold while this other team just got done playing in another league.
I'm sorry the rules aren't being upheld and admins are okay with it, and teams just get screwed over. 4/4
English