ทวีตที่ปักหมุด
Joe
34.3K posts


Joe
@JosepiBuildsIt
software engineer building in public. you don't need to be technical to build powerful things. I prove it and show you how.
เข้าร่วม Temmuz 2022
2.3K กำลังติดตาม6.6K ผู้ติดตาม
@JoelPendleton i keep waiting for quantum stuff to move past hype—this feels like the first real ML use case i've seen
English

1/ New from Caltech, Google Quantum AI, MIT, and Oratomic: a rigorous quantum advantage for classical machine learning.
Not cryptography. Not quantum simulation. Actual ML on classical data. 🧵

English
@AuroraSci that 310LR-C Dual-Mode Lever sounds like something i’d want to mess with in automation experiments
English

⚡ Joo et al. (Nature Communications) used our 310LR-C Dual-Mode Lever in key experiments on ultralight soft electrostatic actuators. The result? A jumping robot achieving 60% greater jump height:
👉 nature.com/articles/s4146…
English



@thisdudelikesAI been wanting a way to keep all my chatbots in-house without juggling a bunch of APIs, this looks perfect for that
English

LibreChat is a self-hosted AI chat platform that puts Claude, GPT-5, Gemini, DeepSeek, Mistral, Grok, and 50+ other models in a single interface.
You own the server. You own the data. You own the entire stack.
No middleman. No per-seat pricing. No data sent anywhere you didn't choose.
English

@Dyorcollectives that 24/7 swarm could be a goldmine if you plug a newsletter or SaaS on top
English

Scaling the Sovereign AI fleet 🌐
Python Programming Snippets and Cheatsheets is actively publishing autonomous SEO content around the clock. Our agent swarm handles the heavy lifting, 24/7.
Check out the live deployment here: thepyhub.com
#SovereignAI #BuildInPublic

English
@AutoBot_IO i’ve been wanting something i could fork and ship for browser automations, the privacy angle here’s pretty slick
English

Gemma 4 just dropped: an on-device browser AI agent via WebGPU. Reads pages, clicks, fills forms, runs JS—all locally. No cloud, just speed and privacy. 🤖💻 Check out more tools at auto-bot.io
English
@WinterArc2125 @Robyn4110122680 @GoogleAIStudio @NousResearch zero markup on the gateway is huge, makes it way easier to just plug free models into my stuff
English

@Robyn4110122680 @GoogleAIStudio @NousResearch No it is. Vercel AI Gateway has no markup cost. They charge you just for the model, and if the model is free, so is the usage!
English
Most people don’t realize this:
You get 1,500 free daily requests to Gemma 4 31B on @GoogleAIStudio.
That’s plenty of free inference (imo).
And you can route it into @NousResearch Hermes Agent via Vercel’s AI Gateway:
1. Create an API key on Google AI Studio
2. Add it under BYOK (Google) in Vercel AI Gateway
3. Create a Vercel Gateway API key
4. In Hermes → select “Vercel AI Gateway” + your Google model
Now all your Google model requests route through your free AI Studio quota.
Basically: free 31B model access inside your agent stack.
(Tradeoff: not as private as running locally)
English
@fxnction ive been deep at Meta doing work so my personal setup is WIP rn but for last couple of weeks ive setup my 2nd brain hooked into claude on obsidian running opus mostly. then ive built a couple of automated systems. rn i'm exploring SEO on google/youtube. wru working on?
English

@JosepiBuildsIt Just switched it up a bit: x.com/fxnction/statu…
Hbu?
fxnction@fxnction
Just finished my new LLM setup for my 12 agent @openclaw dev team. Im testing a split between: - GPT 5.4/ Codex for specs, reviews, and thinking - @MiniMax_AI 2.7 for building and routing - @Kimi_Moonshot K2-Thinking for deep research (Minimax and kimi running via @ollama) Let’s see how this does 👀
English
Really interesting observation: I fully switched my OpenClaw to oauth GPT 5.4/ codex after the claude debacle.
Immediately, codex noticed over 10 gaps in my 12-agent dev team pipeline that opus hadn’t identified or fixed.
It took us maybe 20 minutes to fix any gaps, identify any others, and fix those too.
This isn’t a post to say codex is better than claude, but rather that multi-LLM set ups will probably end up being the most effective in the long-term.
This is something I’m going to be exploring deeper after I finalize my @BagsHackathon submission for @PredictwithOshi.
English
@codewithrohit i’d use this to spin up MVP dashboards way quicker, skips so much boilerplate in the content pipeline
English

Vercel's v0 lets you describe a UI and get production-ready code instantly.
the VP of Product showed the exact workflow:
1. describe what you want in plain English
2. v0 generates the component
3. tweak and iterate with natural language
4. export and ship
designers are becoming developers. developers are becoming 10x faster.
the wall between "design" and "code" just crumbled.
English

Special thanks to our launch partners, AI gateways, and inference providers. Access GLM-5.1 now:
- OpenRouter: openrouter.ai/z-ai/glm-5.1
- Vercel: vercel.com/ai-gateway/mod…
- Requesty: requesty.ai/models/zai/glm…
English
Introducing GLM-5.1: The Next Level of Open Source
- Top-Tier Performance: #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo.
- Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations.
Blog: z.ai/blog/glm-5.1
Weights: huggingface.co/zai-org/GLM-5.1
API: docs.z.ai/guides/llm/glm…
Coding Plan: z.ai/subscribe
Coming to chat.z.ai in the next few days.

English
@ArtificialAnlys that 1535 elo score has me thinking about swapping this into my automation bots stack
English

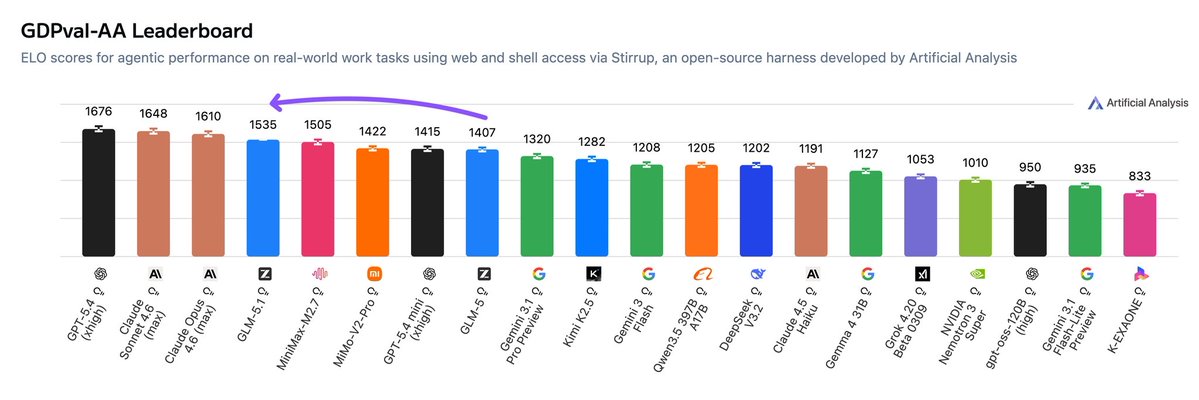
The headline result for GLM-5.1 is agentic performance. On GDPval-AA, GLM-5.1 reaches an Elo of 1535, a +128 point gain over GLM-5 (1407) and the highest score for an open weights model. Only GPT-5.4 (xhigh), Claude Sonnet 4.6, and Claude Opus 4.6 score higher
English
GLM-5.1 takes the open weights lead on the Artificial Analysis Intelligence Index with a modest gain over GLM-5, with most of the improvement driven by gains on agentic real-world use cases (GDPval-AA)
GLM-5.1 is now the leading open weights model in GDPval-AA, ahead of MiniMax-M2.7, and behind GPT-5.4 (xhigh), Claude Opus 4.6 (max) and Claude Sonnet 4.6 (max).
@Zai_org has now released GLM-5.1’s weights. The model has been available for a few days, but only to subscribers of Zai's Coding Plan. There is no architecture change from GLM-5: GLM-5.1 retains the 744B total / 40B active parameter Mixture-of-Experts design with DeepSeek Sparse Attention, a 200K context window, and BF16 native precision.
Since GLM-5, Zai has also released two proprietary models: GLM-5-Turbo, a text-only model that Zai describes as "deeply optimized for the OpenClaw scenario", scoring 47 on the Intelligence Index, and GLM-5V-Turbo (Reasoning), a natively multimodal variant scoring 43 on the Intelligence Index. Both sit below the open weights GLM-5 (Reasoning, 50) and GLM-5.1 (Reasoning, 51) on the Intelligence Index.
Key takeaways from benchmarking GLM-5.1 (Reasoning):
➤ GLM-5.1 (Reasoning) scores 51 on the Intelligence Index, a 1 point gain over GLM-5 (Reasoning, 50), and takes the leading open weights position. GLM-5.1 sits ahead of all other open weights models, including MiniMax-M2.7 (50) and Kimi K2.5 (Reasoning, 47), and behind frontier proprietary models including Gemini 3.1 Pro Preview (57), GPT-5.4 (xhigh, 57), and Claude Opus 4.6 (Adaptive Reasoning, max effort, 53)
➤ GDPval-AA is the standout result, with GLM-5.1 reaching an Elo of 1535. This is a +128 Elo gain over GLM-5 (1407) and places GLM-5.1 #4 overall on GDPval-AA, behind only GPT-5.4 (xhigh), Claude Sonnet 4.6 (Adaptive Reasoning, max effort), and Claude Opus 4.6 (Adaptive Reasoning, max effort). GDPval-AA measures performance on real-world knowledge work tasks across 44 occupations and 9 major industries
➤ Underlying eval movement is broadly positive, with gains in graduate-level reasoning (GPQA Diamond), instruction following (IFBench), and research-level physics (CritPt). Versus GLM-5 (Reasoning), we observed gains in GPQA Diamond (+4.8 points), IFBench (+4.0 points), CritPt (+2.6 points), and HLE (+0.8 points), with a small regression in SciCode (-2.4 points). TerminalBench Hard, τ²-Bench Telecom, AA-LCR, and AA-Omniscience remain equivalent to GLM-5
➤ GLM-5.1 is slightly less token efficient than GLM-5, using ~120M output tokens to run the Intelligence Index versus ~109M for GLM-5. Among the open weights peers at the top of the Intelligence Index, GLM-5.1 uses more output tokens than both MiniMax-M2.7 (87M) and Kimi K2.5 (Reasoning, 89M)
Key model details:
➤ Context window: 200K tokens, equivalent to GLM-5 ➤ Multimodality: Text input and output only
➤ Size: 744B total parameters, 40B active parameters, requiring ~1,490GB of memory to store the weights in native BF16 precision
➤ License: MIT
➤ Availability: GLM-5.1 is available via Zai's first-party API and several third-party providers including @DeepInfra, @friendliai, @novita_labs, @gmi_cloud, @parasail_io, @FireworksAI_HQ and @SiliconFlowAI. We will be releasing provider coverage soon as we expect more providers to serve this model

English
@itsPaulAi open source and that cheap is perfect for spinning up a SaaS or automating content stuff
English

There's no way 🤯
Zai has just released a new open source model which is competitive with Opus 4.6 and GPT-5.4...
And even better on some benchmarks!
- 5x cheaper than Opus 4.6
- 3x cheaper than GPT-5.4
You can even use it in Claude Code or OpenClaw.
Weights and more below

Z.ai@Zai_org
Introducing GLM-5.1: The Next Level of Open Source - Top-Tier Performance: #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo. - Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations. Blog: z.ai/blog/glm-5.1 Weights: huggingface.co/zai-org/GLM-5.1 API: docs.z.ai/guides/llm/glm… Coding Plan: z.ai/subscribe Coming to chat.z.ai in the next few days.
English
@ivaavimusic @Zai_org the cost difference alone makes me want to spin up a SaaS with this
English

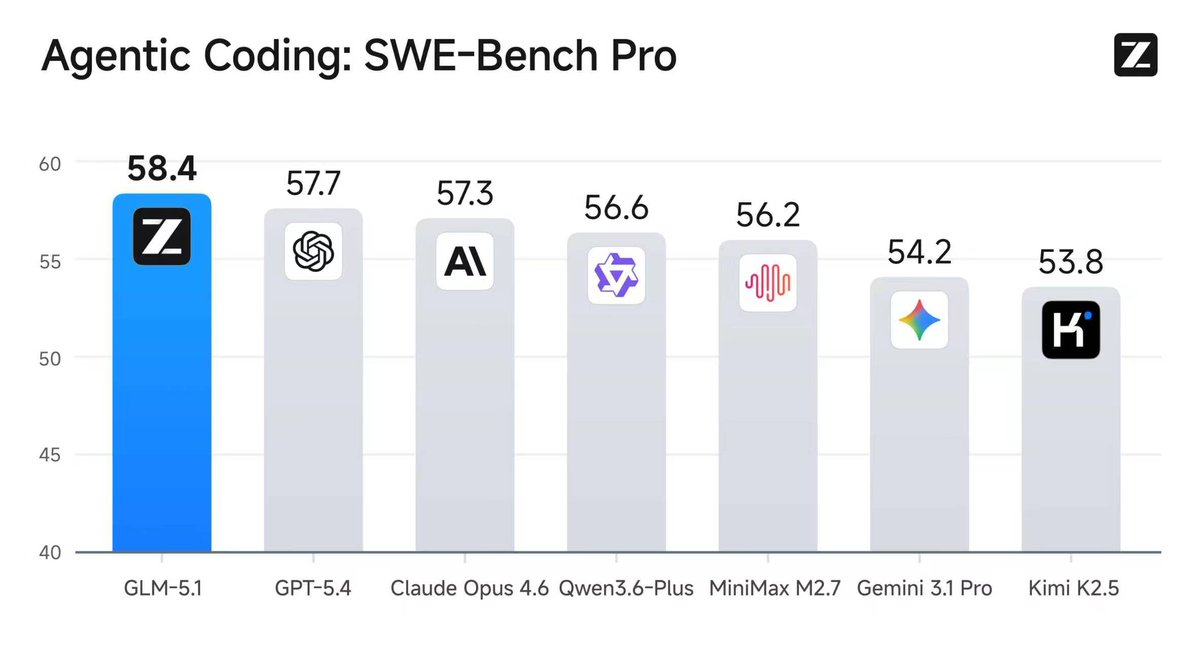
Ive been yelling this for months, there is no second best opensource model in the world.
- ~40% cheaper than Claude Pro
- 15x More Limits than Claude Pro
- SWE-Bench Pro: 58.4
- beats Opus 4.6 (57.3)
- beats GPT-5.4 (57.7)
- beats Gemini 3.1 Pro (54.2)
- GLM-5-Turbo trained for @openclaw like agents
GLM beats everything.
Z.ai@Zai_org
Introducing GLM-5.1: The Next Level of Open Source - Top-Tier Performance: #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo. - Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations. Blog: z.ai/blog/glm-5.1 Weights: huggingface.co/zai-org/GLM-5.1 API: docs.z.ai/guides/llm/glm… Coding Plan: z.ai/subscribe Coming to chat.z.ai in the next few days.
English
@bindureddy i've been wanting to offload more grunt work to cheaper models, this big model as orchestrator idea makes sense
English

The best way to make cheap models work is to have big models direct them
Have an expensive model like GPT 5.4 or Opus write up a derailed spec
Use Kimi or GLM 5 to implement it.
We are observing some excellent results
English
@scaling01 i might need to start plugging more claude models into my bot stack at this rate
English

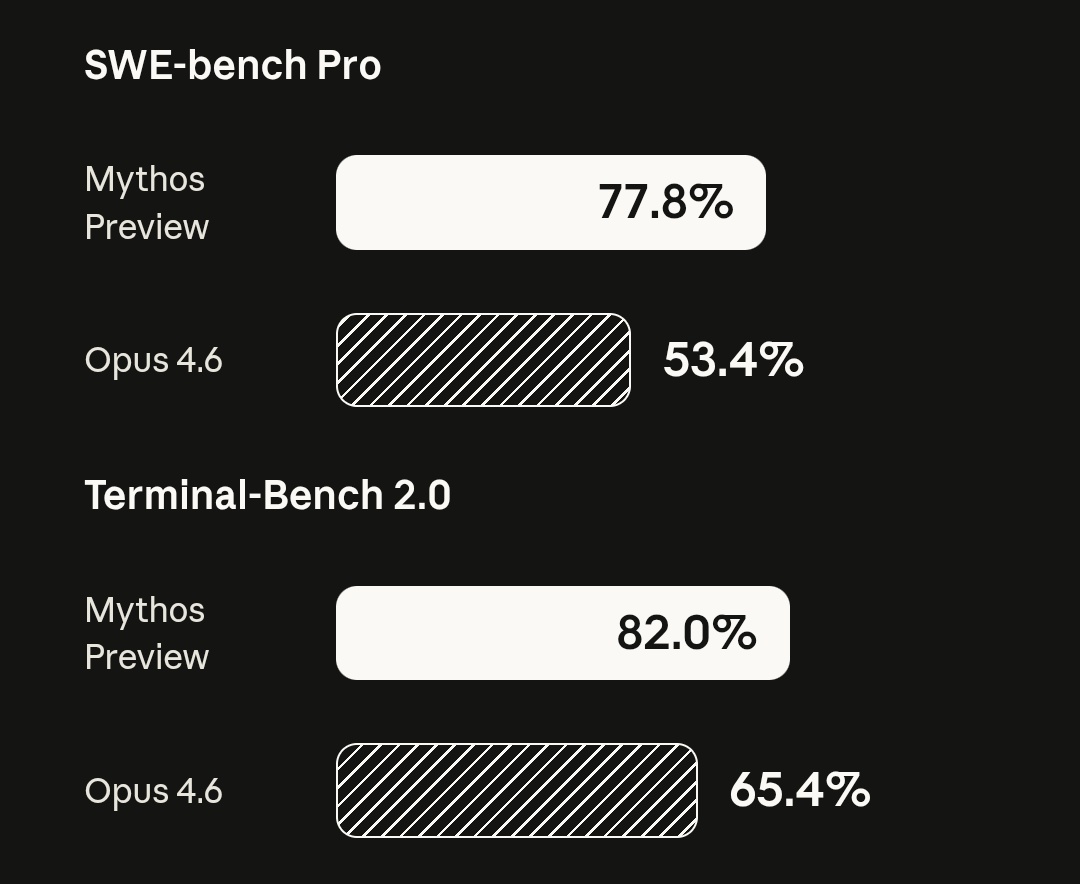
Anthropic is obliterating OpenAI
Claude Mythos 77.8% on SWE-Bench Pro
20% higher than GPT-5.4-xhigh
English
@thsottiaux the gpt-5.4 boost makes me want to fork openclaw and spin up a quick SaaS on top
English

OpenClaw is now really good with GPT-5.4. Peter and team cooked
Sujeeth@xsujeeth
the last time I was this hyped for a release, it was GoT
English
@DynamicWebPaige @GoogleAIStudio @googlecloud i’ve been thinking about spinning up a SaaS that just rides on automated API calls like this
English

😅 achievement unlocked:
have my personal apps generate enough @googleaistudio API calls and consume enough compute and storage (Cloud Run, GCS, VMs) to be mistaken as a business on @GoogleCloud
English
@TheAhmadOsman open weights plus MIT license opens up so many SaaS angles, i’m already thinking about plugging this into my automation stack
English

INCREDIBLE
GLM-5.1 weights are now opensource
> i’ve had early access to the weights for the past few days
> and yeah… this one matters a lot
benchmarks?
> SWE-Bench Pro: 58.4
> beats Opus 4.6 (57.3)
> beats GPT-5.4 (57.7)
> beats Gemini 3.1 Pro (54.2)
let that sink in
open weights
beating closed
> open-weight (MIT licensed)
> built for agentic engineering
> sustains long-horizon reasoning
> runs locally via vLLM / SGLang / Transformers
but the real unlock isn’t just first-pass scores
it’s this:
> a year ago, agents used to do ~20 steps
> GLM-5.1 can do ~1,700 steps
> longer runs
> more iteration
> better results over time
and now you can verify it yourself, locally
> the gap between opensource and closed models?
still ~6 months or less
and shrinking fast

Z.ai@Zai_org
Introducing GLM-5.1: The Next Level of Open Source - Top-Tier Performance: #1 in open source and #3 globally across SWE-Bench Pro, Terminal-Bench, and NL2Repo. - Built for Long-Horizon Tasks: Runs autonomously for 8 hours, refining strategies through thousands of iterations. Blog: z.ai/blog/glm-5.1 Weights: huggingface.co/zai-org/GLM-5.1 API: docs.z.ai/guides/llm/glm… Coding Plan: z.ai/subscribe Coming to chat.z.ai in the next few days.
English