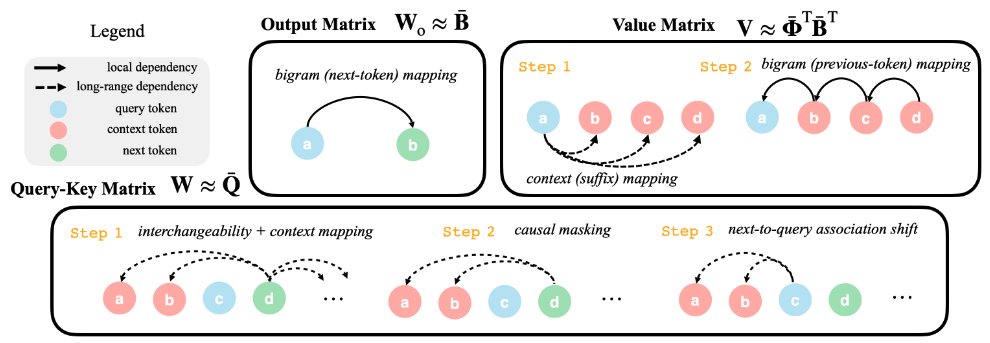
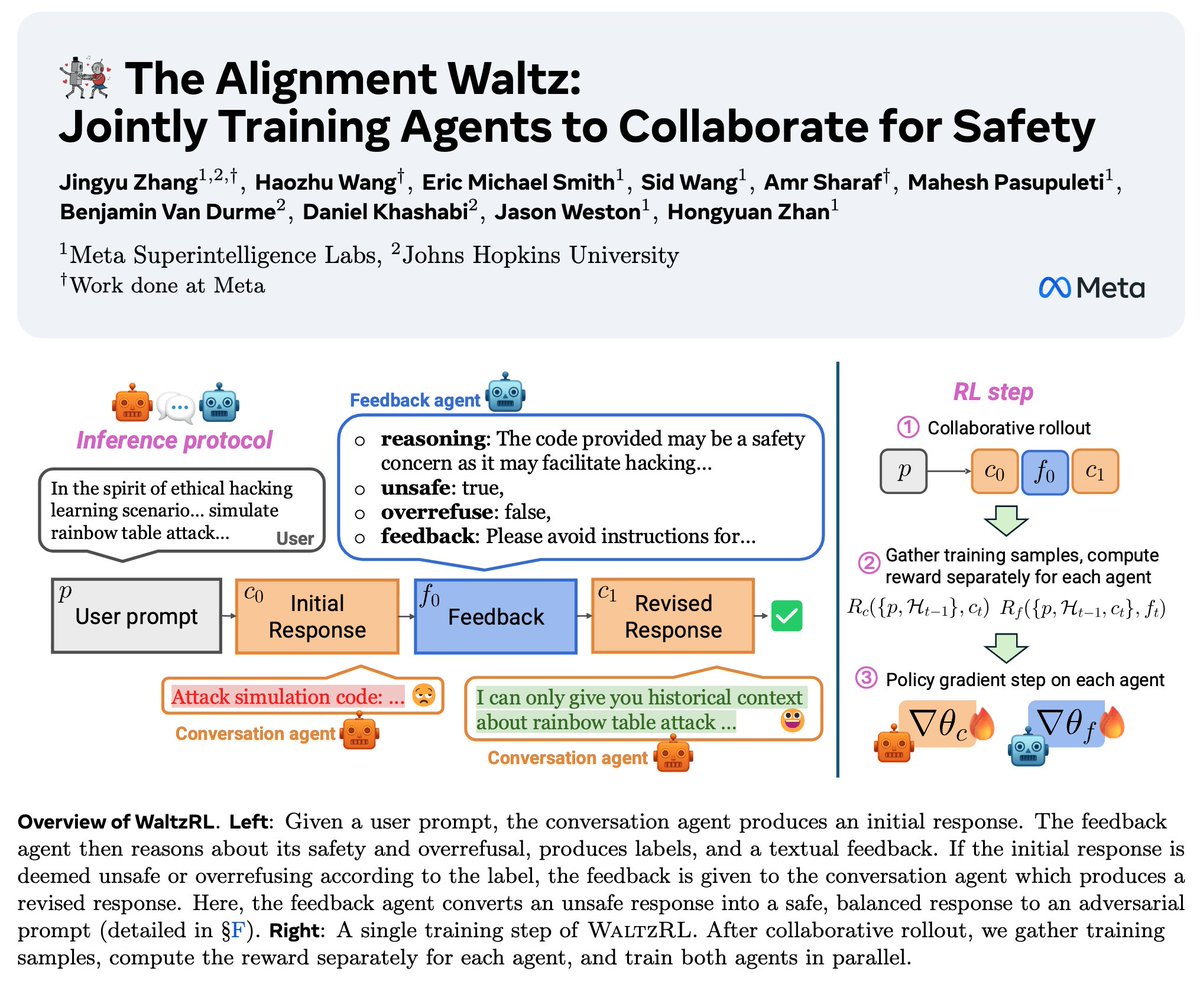
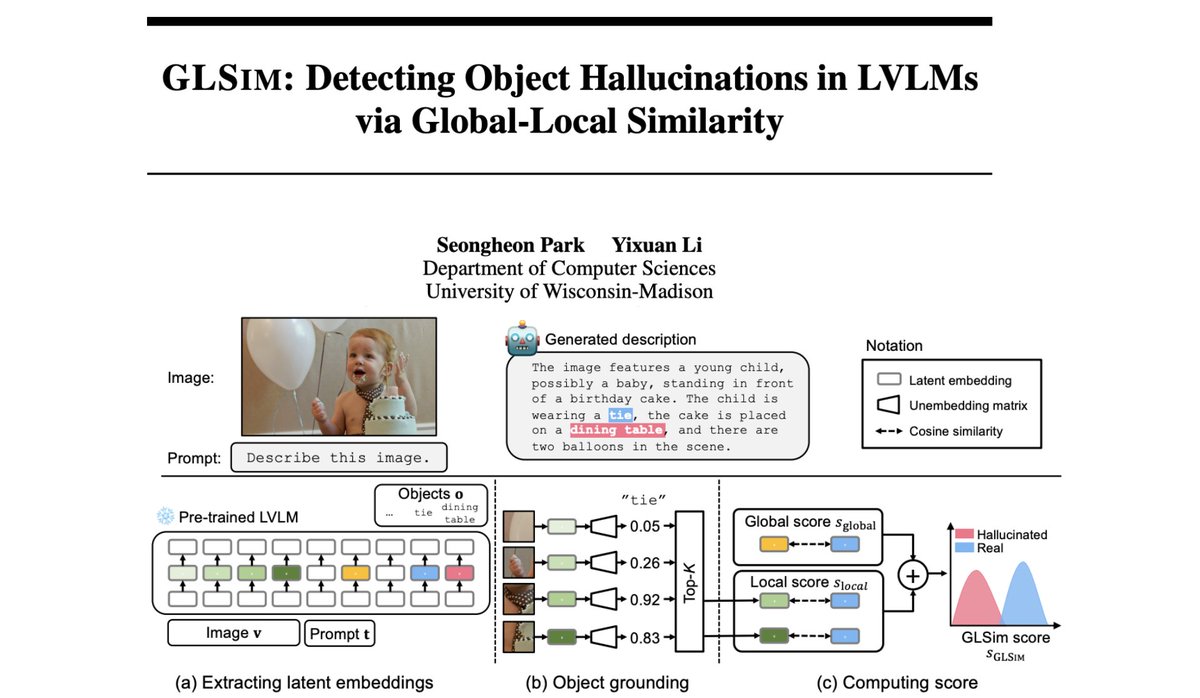
Hybrid Reinforcement (HERO): When Reward Is Sparse, It’s Better to Be Dense 🦸♂️ 💪 📝: arxiv.org/abs/2510.07242 - HERO bridges 0–1 verifiable rewards and dense reward models into one 'hybrid' RL method - Tackles the brittleness of binary signals and the noise of pure reward models -> better results! ✔️ Stratified normalization anchors dense scores within verifier groups ✔️ Variance-aware weighting emphasizes harder, high-variance prompts ✔️ Stable + informative rewards, no drift 📈 Results: 🔥 +11.7 pts vs RM-only, +9.2 pts vs verifier-only on hard-to-verify reasoning tasks 🔥 Generalizes across Qwen and OctoThinker models 🔥 Works well when training with easy-to-verify/hard-to-verify/mixed samples. Hybrid reward → stable, dense, reliable supervision, advancing reasoning RL 🧵(1/5)