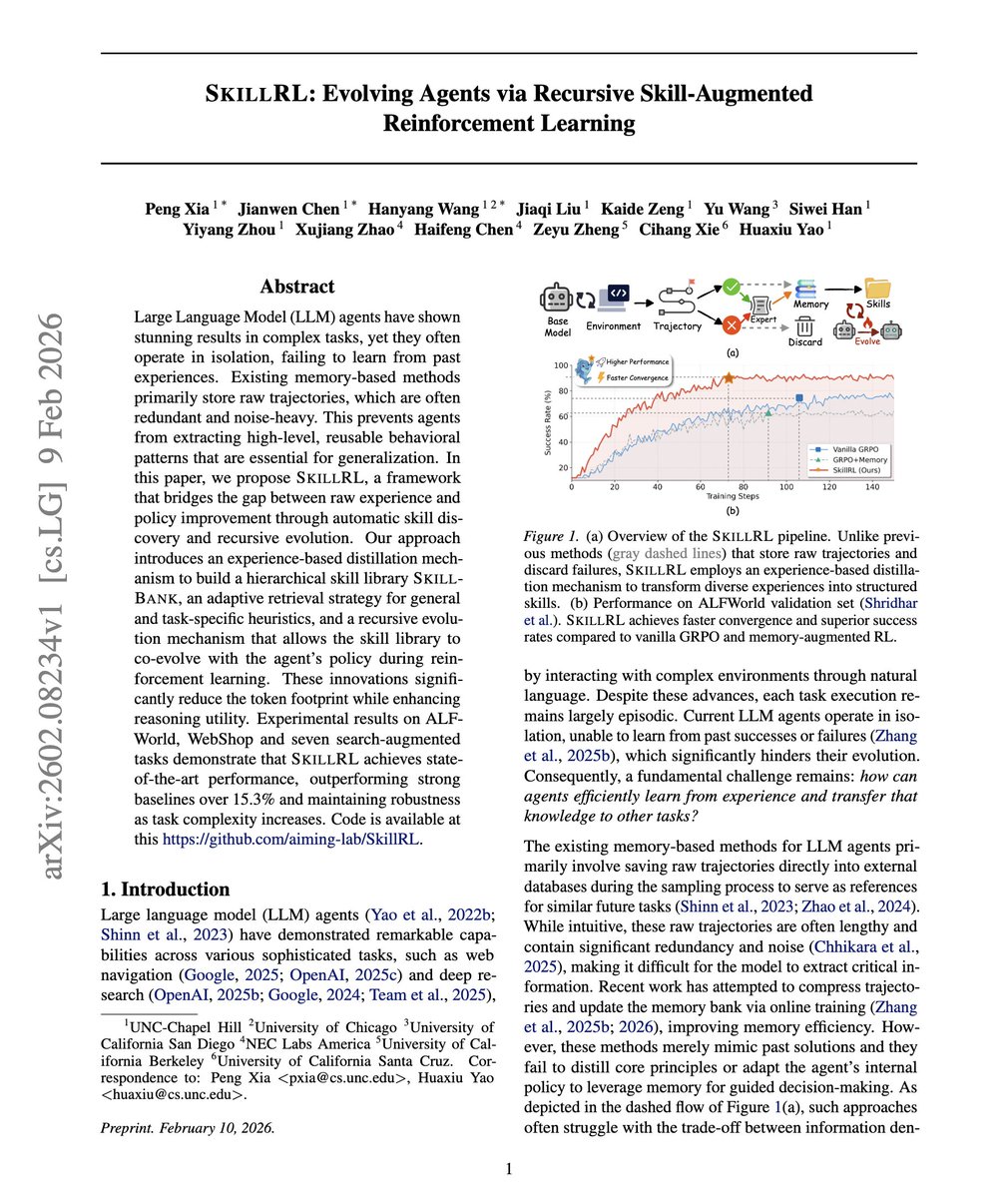
@HyperAI_News Definitely, I would still like to see it extend beyond a 24 hour challenge to see how an agent can accumulate knowledge across sessions, users and even organizations!
English
Michael Elabd
108 posts
@MichaelElabd
Foundational Research @ DeepMind

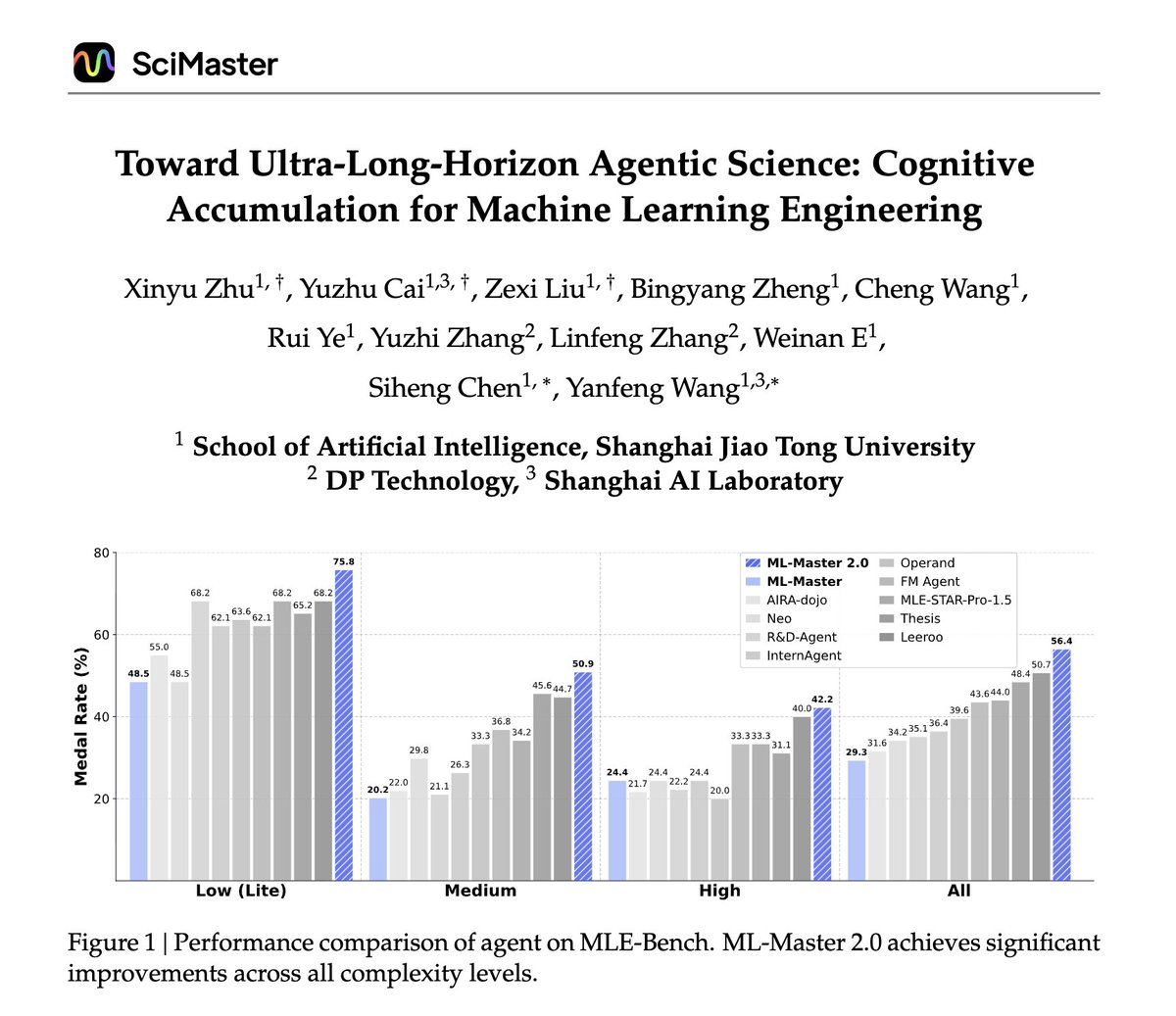
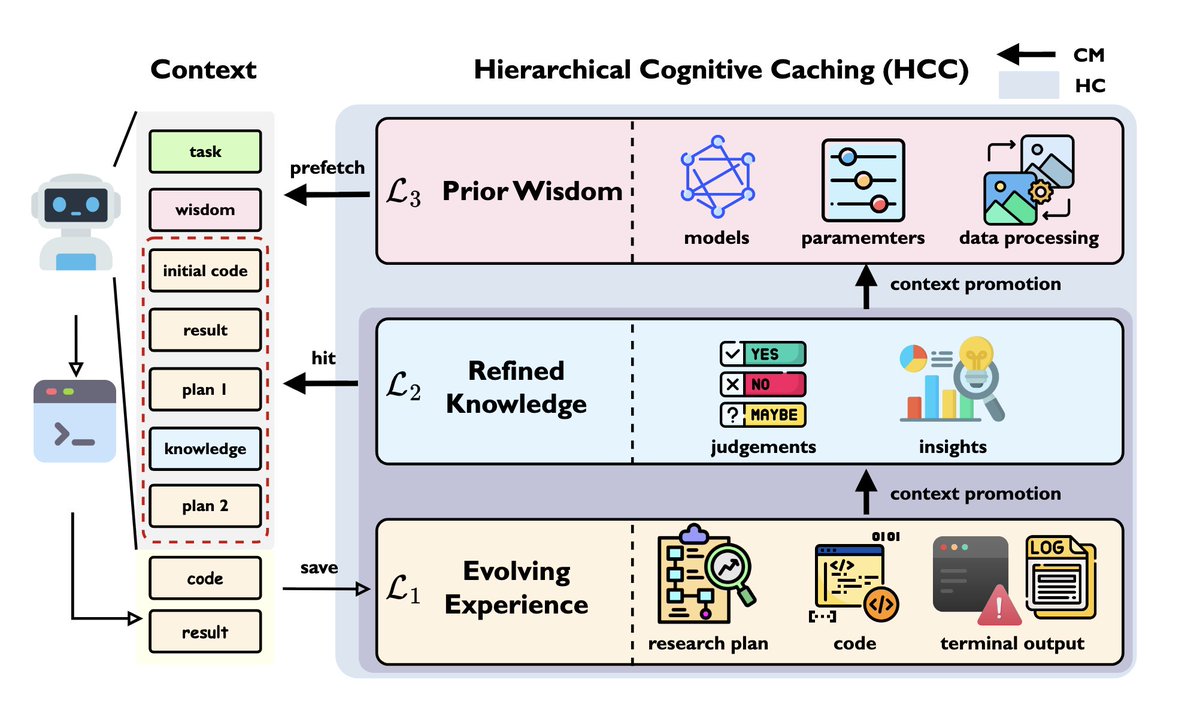





We’re rolling out an upgrade designed to help robots reason about the physical world. 🤖 Gemini Robotics-ER 1.6 has significantly better visual and spatial understanding in order to plan and complete more useful tasks. Here’s why this is important 🧵






Earlier this week, we published our technical report on Composer 2. We're sharing additional research on how we train new checkpoints. With real-time RL, we can ship improved versions of the model every five hours.