Qwen@Alibaba_Qwen
🚀 Introducing Qwen3-VL-Embedding and Qwen3-VL-Reranker – advancing the state of the art in multimodal retrieval and cross-modal understanding!
✨ Highlights:
✅ Built upon the robust Qwen3-VL foundation model
✅ Processes text, images, screenshots, videos, and mixed modality inputs
✅ Supports 30+ languages
✅ Achieves state-of-the-art performance on multimodal retrieval benchmarks
✅ Open source and available on Hugging Face, GitHub, and ModelScope
✅ API deployment on Alibaba Cloud coming soon!
🎯 Two-stage retrieval architecture:
📊 Embedding Model – generates semantically rich vector representations in a unified embedding space
🎯 Reranker Model – computes fine-grained relevance scores for enhanced retrieval accuracy
🔍 Key application scenarios:
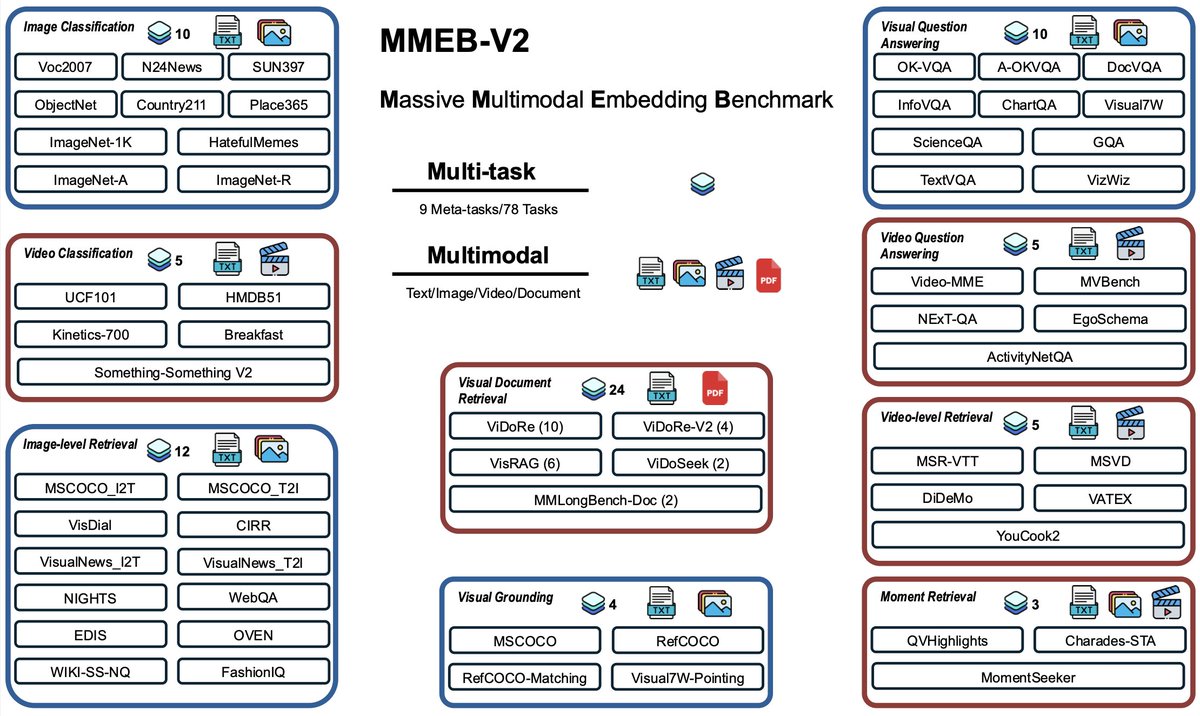
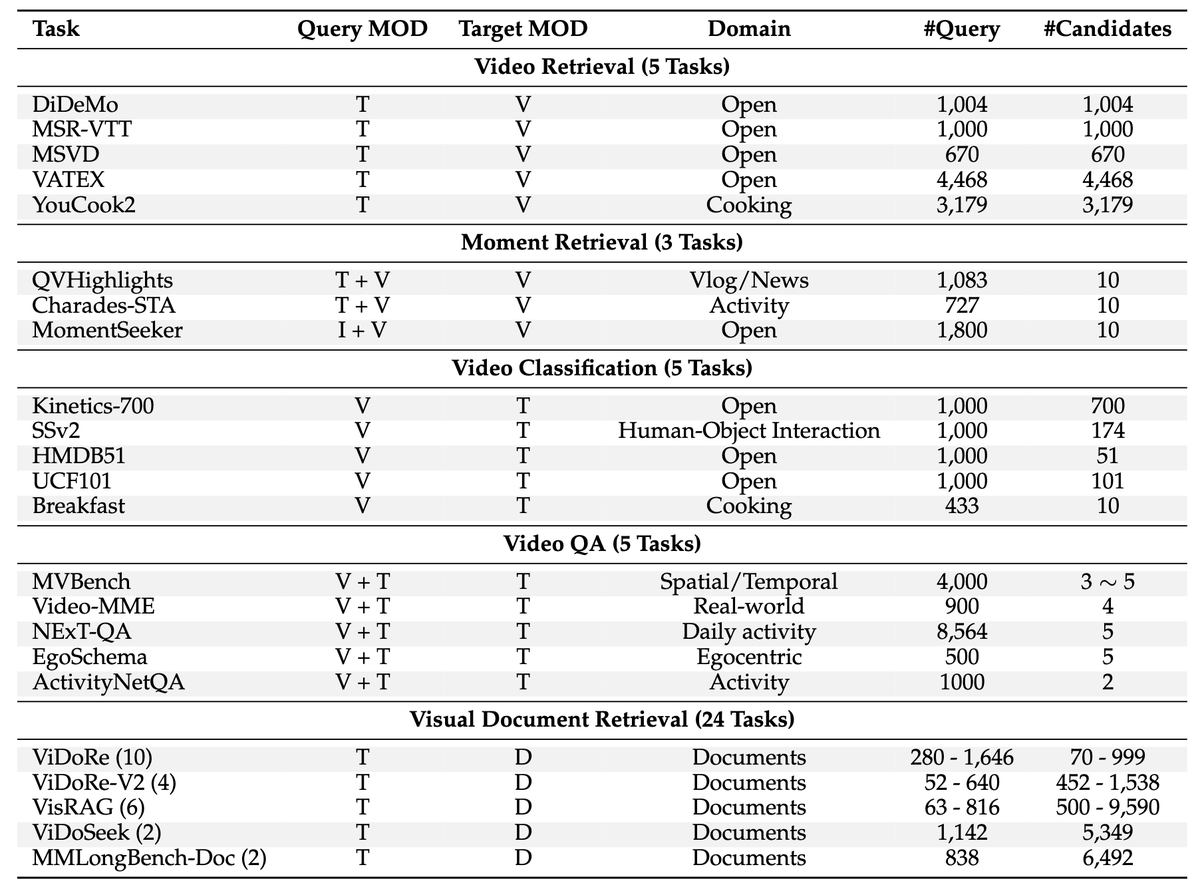
Image-text retrieval, video search, multimodal RAG, visual question answering, multimodal content clustering, multilingual visual search, and more!
🌟 Developer-friendly capabilities:
• Configurable embedding dimensions
• Task-specific instruction customization
• Embedding quantization support for efficient and cost-effective downstream deployment
Hugging Face:
huggingface.co/collections/Qw…
huggingface.co/collections/Qw…
ModelScope:
modelscope.cn/collections/Qw…
modelscope.cn/collections/Qw…
Github: github.com/QwenLM/Qwen3-V…
Blog: qwen.ai/blog?id=qwen3-…
Tech Report:github.com/QwenLM/Qwen3-V…