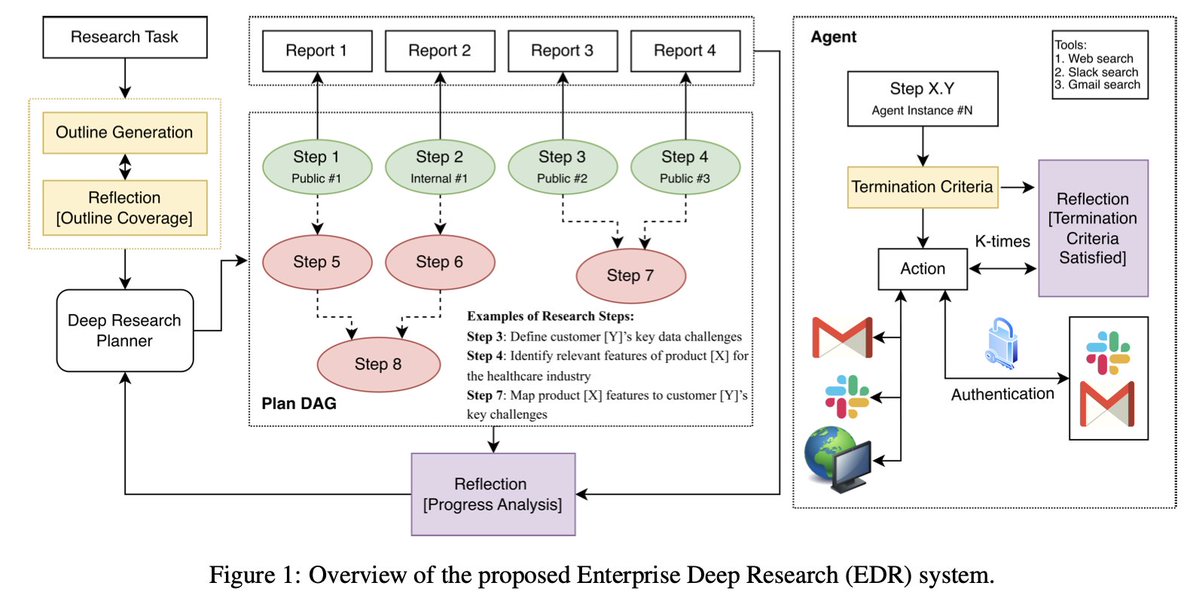
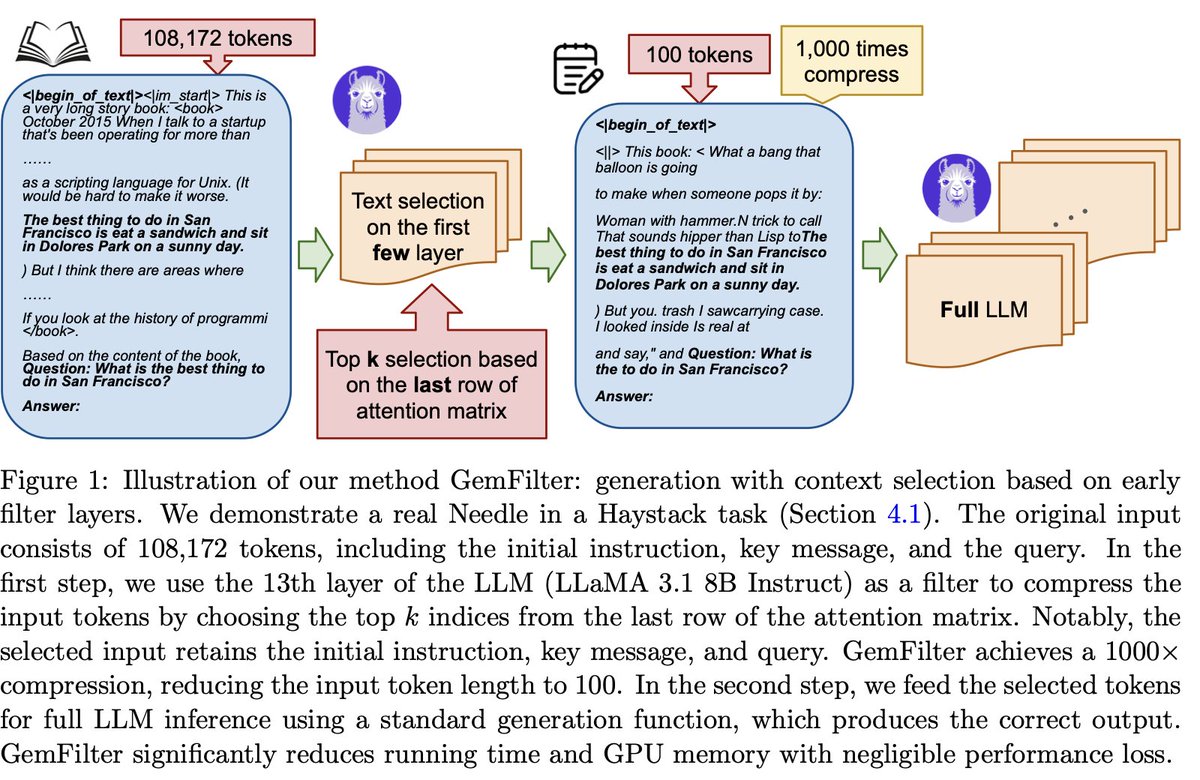
Sabitlenmiş Tweet

Looking for the cutting-edge of AI research? Follow Salesforce AI Research to see how we're transforming enterprise technology through advanced innovations. From world models to agentic systems, discover the future of AI before it hits the market.
English