Suresh
6K posts


Suresh
@_Suresh2
MSc Software Engineering @ Chongqing University ’26 | Researching AI x Software Engineering (AI for SE & SE for AI) | 🇵🇰➡️🇨🇳

其实小龙虾原生的抓取机制一直不是很完善。 抓取比较慢,token消耗也多。很多人会配合用firecrawl或者JINA来抓。 其实还有一个平替叫xcrawl,安装更方便,只需要把文档丢给小龙虾, docs.xcrawl.com/zh/doc/develop… 小龙虾自己读完,Skill 自动装好,然后按照指示再给它Key即可。ClawHub 里搜「xcrawl」也行,一键导入。 xcrawl有四种场景可以使用: - Search:搜索引擎查询,标题 / URL / 摘要 / 排名结构化直出 - Map:扫一个站点,先把所有 URL 列出来,前置规划用 - Scrape:指定 URL 抓一次,干净的 Markdown 直接喂 LLM - Crawl:全站递归批量爬,搭知识库 / 做 RAG 专用 平时网页抓取的 90% 需求,基本都落在这四种里。 比如可以让小龙虾做 changelog 总结 每天定时抓一遍 code.claude.com/docs/en/change… 再给它配一个 ccc 快捷指令。敲一下 ccc,就知道 Claude Code 今天又卷出什么新功能。 有了这些数据采集工具,Agent就有能力获得更多上下文信息,更好服务人类。 当然,如果你不在意性能和token消耗,其实browser-use也是个选择。 xcrawl给新用户 1000 积分试用额度,方便进行试用体验 xcrawl.com/?keyword=ucrfb…











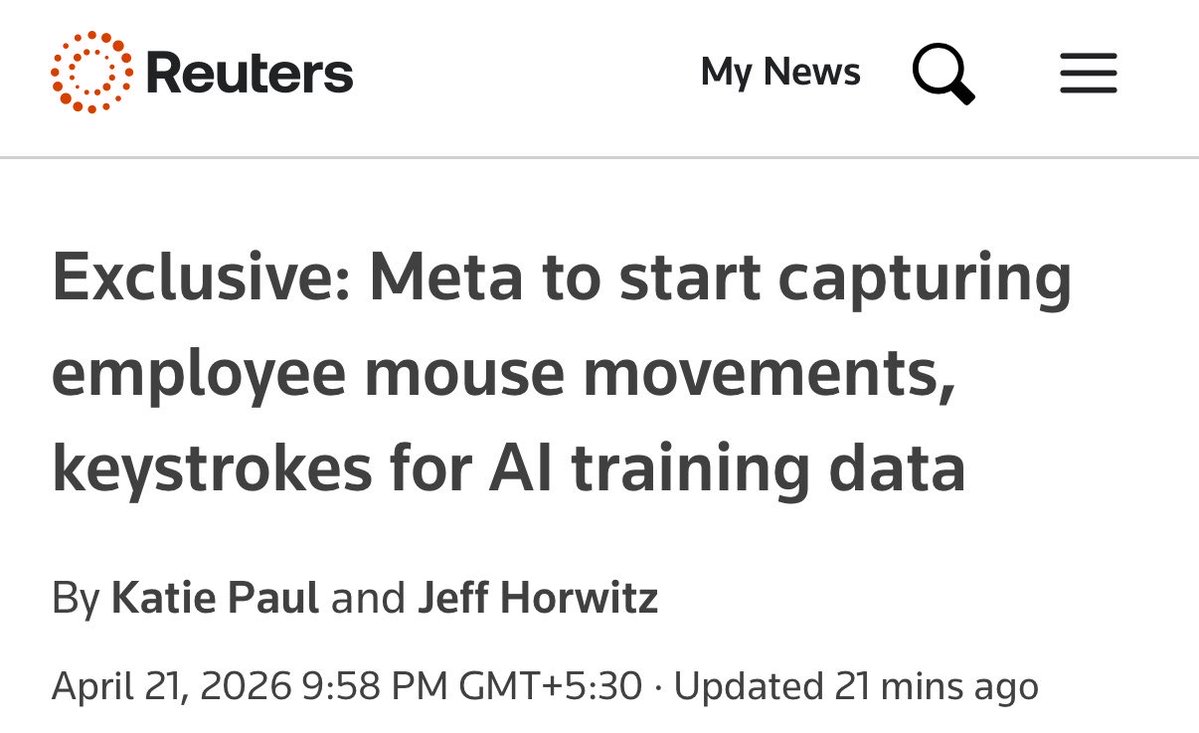






Actually Tao has concluded that the Markov chain is a red herring. Instead, he's been very interested to see how that CoT arrived at using the von Mangoldt function, but came away empty-handed. Even "provenance audit" attempt failed to uncover the real magic.



Today we release all the data sources (and more) in one place, more than 1.4B query-document pairs Plus a new high-quality web dataset built on FineWeb-Edu, replacing the outdated "common crawl" splits most mixtures still rely on (thanks @orionweller) huggingface.co/datasets/light…