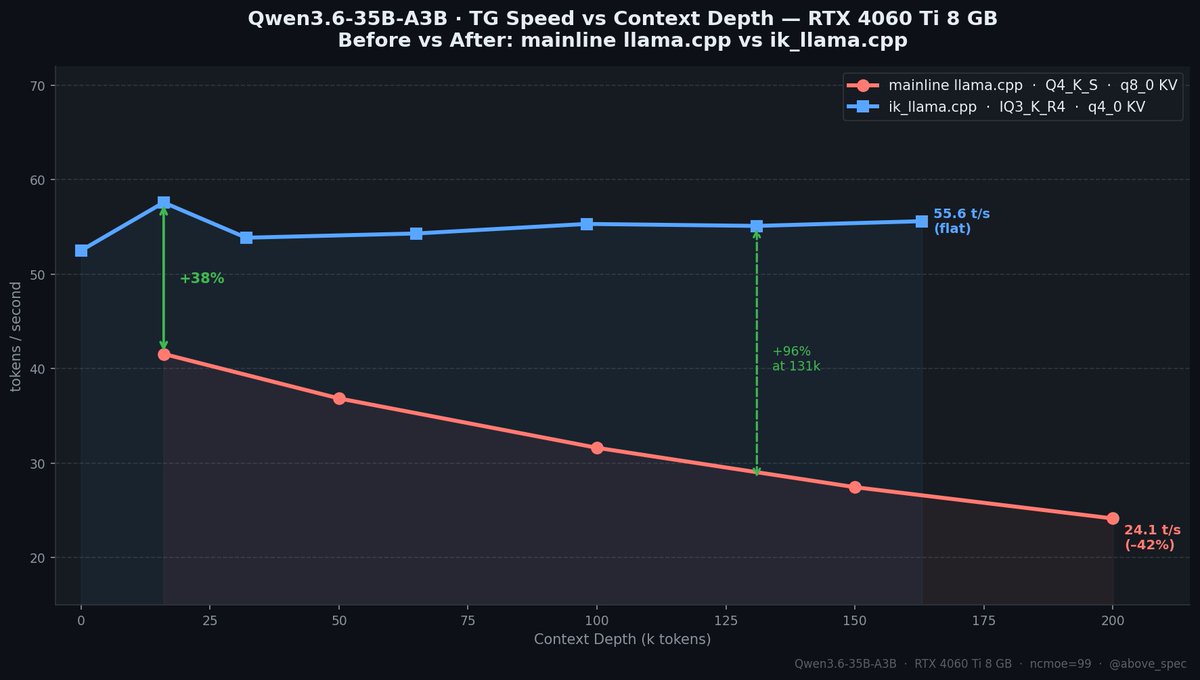
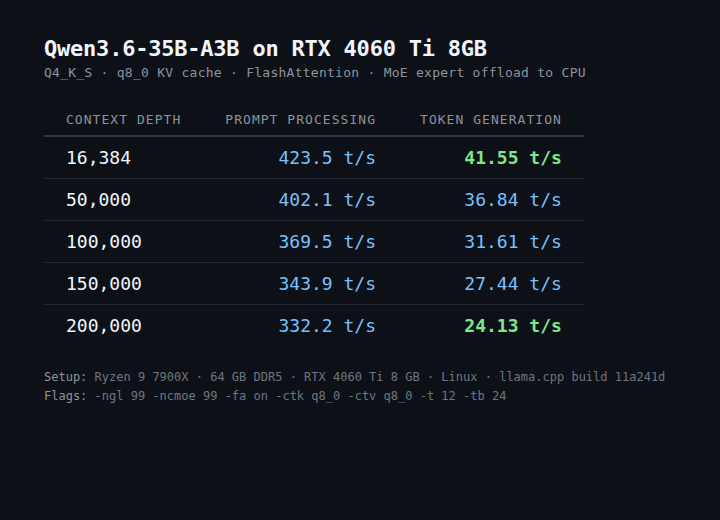
@witcheer Here is my setup for 4060 ti 8gb, I can fit whole 262k and get 49-55 tok/s with ik_llama.cpp:
x.com/i/status/20522…
AboveSpec@above_spec
Quick update on the 35B / 8GB setup. Switched to IQ4_K_R4 — higher quality quant, without losing much speed — getting ~49tok/s through model's full native 262k context. And VRAM usage is low enough to keep a browser with multiple tabs open the whole time. 🧵
English