ทวีตที่ปักหมุด

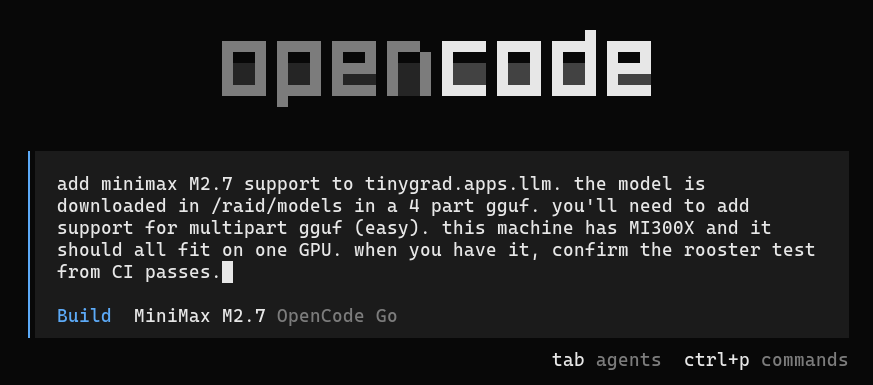
Day 5 of 14: Solving the accelerator utilization problem.
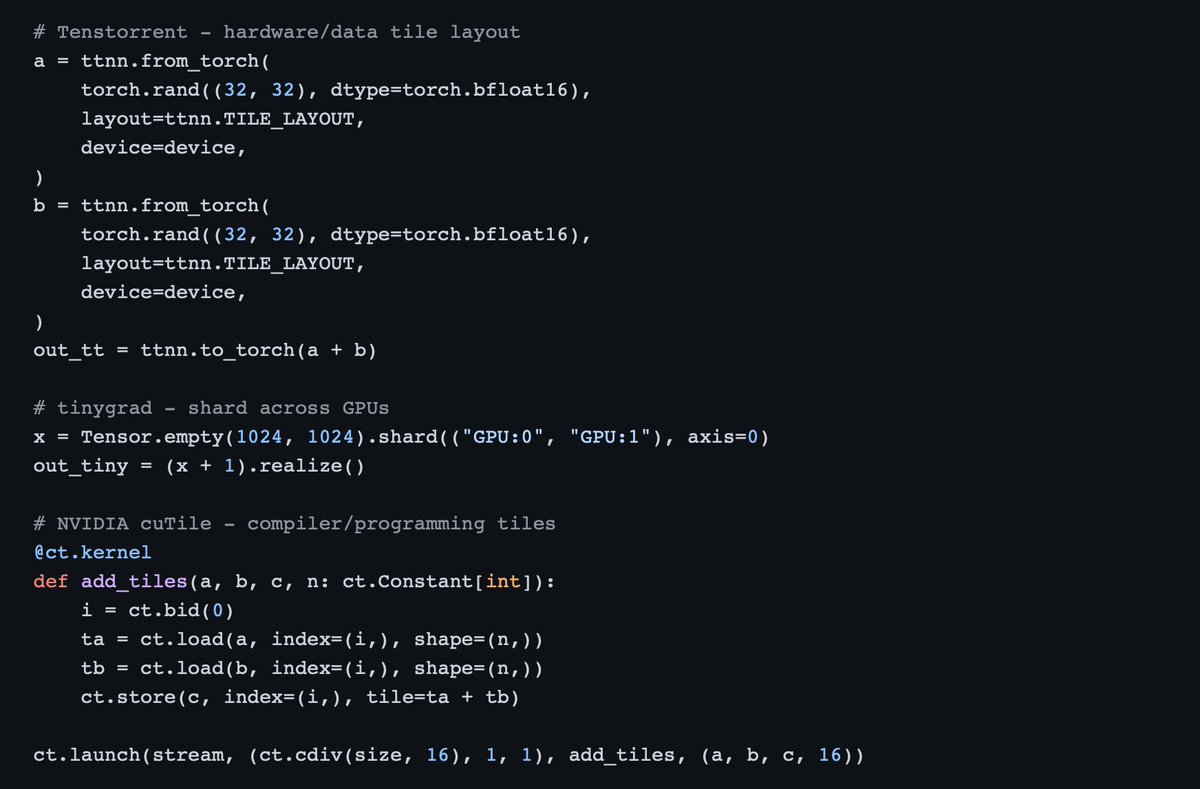
Why are there so many AI chips, and why do companies actually run multiple accelerators? Sticking with one vendor would be so much simpler - one stack, one integration.
OpenAI has its deal with Cerebras, X and Meta are building their own silicon, Chinese big tech folks plan to train and inference on an alternative hardware. Google has TPUs, AWS has been doing this for a while with Trainium and Inferentia. Not counting the cool stuff SambaNova, Tenstorrent are building. Can't speak of Apple - under NDA. And Microsoft is deploying AMD's chips while developing its own silicon - Maia.
There are also plenty of chips aimed at solving different problems - running models with predictable and extremely low latency, or having chips that can work in smart vehicles. But for customers it's complex to adopt a diversified stack. The absolute majority goes with a single vendor for training and a single vendor for inference, and that works quite well.
So that's another problem gpusprint is solving - getting metrics across all of those vendors in a simple, unified format.
Not much interesting stuff today, rather a few routine updates:
- Made my mind to build a custom frontend
- GitHub Actions now work, building and releasing images for all platforms
- Moved everything to Helm charts, tested and moved to OCI registry
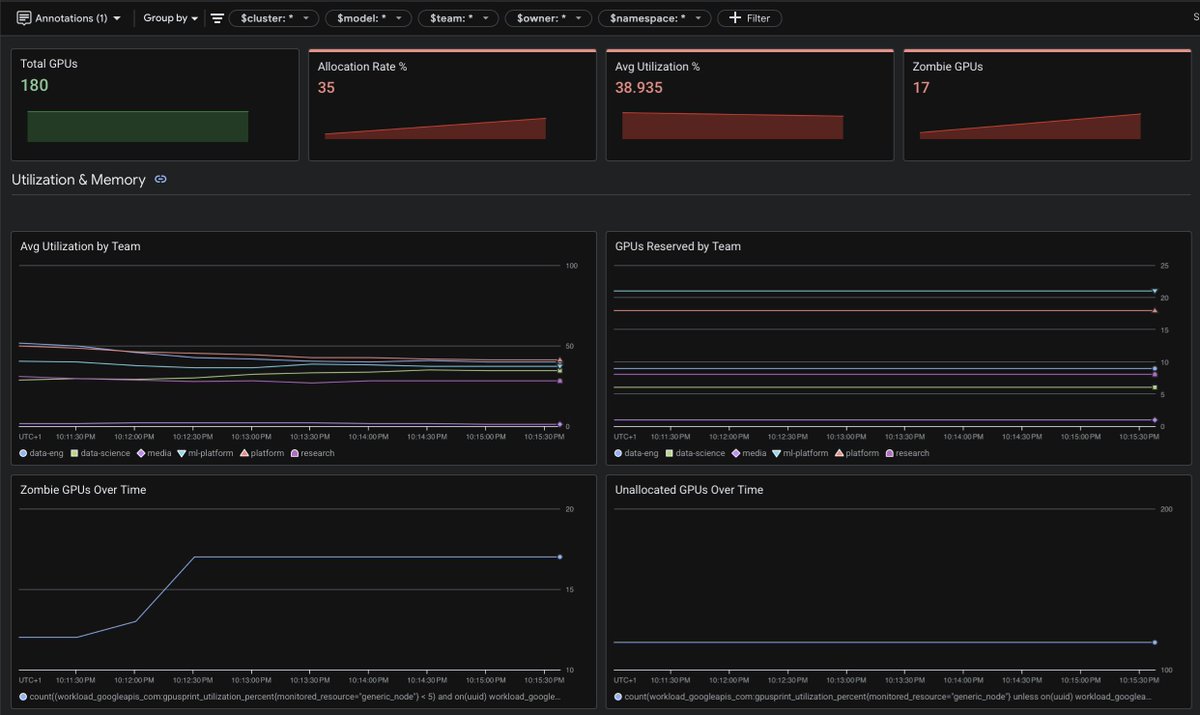
- Improved dashboards
helm upgrade --install gpusprint oci://ghcr.io/antonibertel/charts/gpusprint --namespace gpusprint-system --create-namespace
English