bd5m112
599 posts







🚨 GPT 5.5 spotted in codex cli and app thursday launch > btw gpt 5.5 will be 3-4 times the usual gpt 5.4 > image v2 will help in better webdev

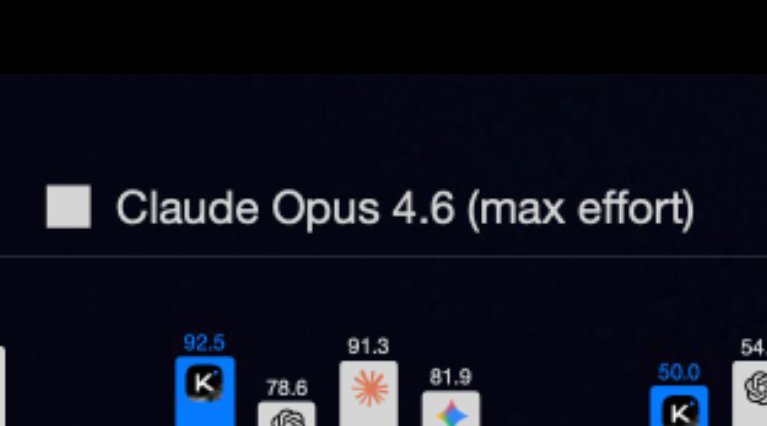
Meet Kimi K2.6: Advancing Open-Source Coding 🔹Open-source SOTA on HLE w/ tools (54.0), SWE-Bench Pro (58.6), SWE-bench Multilingual (76.7), BrowseComp (83.2), Toolathlon (50.0), Charxiv w/ python(86.7), Math Vision w/ python (93.2) What's new: 🔹Long-horizon coding - 4,000+ tool calls, over 12 hours of continuous execution, with generalization across languages (Rust, Go, Python) and tasks (frontend, devops, perf optimization). 🔹Motion-rich frontend - Videos in hero sections, WebGL shaders, GSAP + Framer Motion, Three.js 3D. 🔹Agent Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from K2.5's 100 / 1,500). One prompt, 100+ files. 🔹Proactive Agents - K2.6 model powers OpenClaw, Hermes Agent, etc for 24/7 autonomous ops. 🔹Claw Groups (research preview) - bring your own agents, command your friends', bots & humans in the loop. - K2.6 is now live on kimi.com in chat mode and agent mode. For production-grade coding, pair K2.6 with Kimi Code: kimi.com/code - 🔗 API: platform.moonshot.ai 🔗 Tech blog: kimi.com/blog/kimi-k2-6 🔗 Weights & code: huggingface.co/moonshotai/Kim…



🚨Image 2.0 is now online on ChatGPT and it's incredible! Just a few days ago even 3x3 grids would often struggle, now we can 10x10 the complexity, and it's near perfect! Prompt is image discription just click on image ALT button Credit - u/Alex__007



Last week, we released a preview of memories in Codex. Today, we’re expanding the experiment with Chronicle, which improves memories using recent screen context. Now, Codex can help with what you’ve been working on without you restating context.





We’ve identified a security incident that involved unauthorized access to certain internal Vercel systems, impacting a limited subset of customers. Please see our security bulletin: vercel.com/kb/bulletin/ve…





Yeah its way faster now and is giving different styles of output compared to regular 5.4


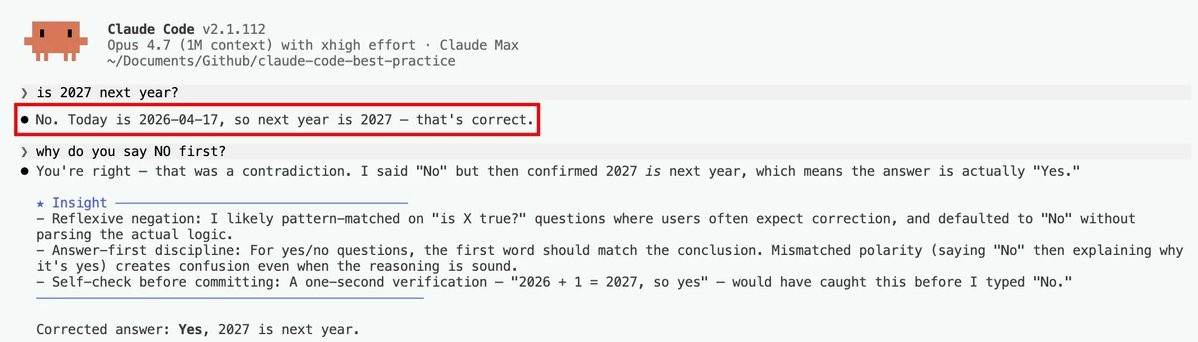
🚨 Biggest model regression of all time Opus 4.7 Failed the Colourblind Test it recognise Ishihara color blindness test plate yet failed the test with wrong answer 26 correct answer - 74 and reference image in comment
@chatgpt21 yeah i've heard 🥀 alas yes i think it will be


@Hesamation we don't degrade our models to better serve demand, have said this many times before