pawel รีทวีตแล้ว
pawel
310 posts




pawel รีทวีตแล้ว

pawel รีทวีตแล้ว

The side of planet Earth we aren't used to seeing.

English
pawel รีทวีตแล้ว

Ireland's Tallaght District Heating Scheme uses waste heat from an #AWS data center to sustainably heat homes & buildings. By 2050, district heating could supply 87% of Dublin's heating demand. I expect to see this model widely adopted in the coming years. allthingsdistributed.com/2024/03/distri…
English
pawel รีทวีตแล้ว

Do Large Language Models really "understand" the world, or just give the appearance of understanding? Evidence (e.g., Othello-GPT) shows LLMs build models of how the world works, which makes me comfortable saying they do understand. More in The Batch: deeplearning.ai/the-batch/issu…
Palo Alto, CA 🇺🇸 English
pawel รีทวีตแล้ว

pawel รีทวีตแล้ว

Oops haven't tweeted too much recently; I'm mostly watching with interest the open source LLM ecosystem experiencing early signs of a cambrian explosion. Roughly speaking the story as of now:
1. Pretraining LLM base models remains very expensive. Think: supercomputer + months.
2. But finetuning LLMs is turning out to be very cheap and effective due to recent PEFT (parameter efficient training) techniques that work surprisingly well, e.g. LoRA / LLaMA-Adapter, and other awesome work, e.g. low precision as in bitsandbytes library. Think: few GPUs + day, even for very large models.
3. Therefore, the cambrian explosion, which requires wide reach and a lot of experimentation, is quite tractable due to (2), but only conditioned on (1).
4. The de facto OG release of (1) was Facebook's sorry Meta's LLaMA release - a very well executed high quality series of models from 7B all the way to 65B, trained nice and long, correctly ignoring the "Chinchilla trap". But LLaMA weights are research-only, been locked down behind forms, but have also awkwardly leaked all over the place... it's a bit messy.
5. In absence of an available and permissive (1), (2) cannot fully proceed. So there are a number of efforts on (1), under the banner "LLaMA but actually open", with e.g. current models from @togethercompute, @MosaicML ~matching the performance of the smallest (7B) LLaMA model, and @AiEleuther , @StabilityAI nearby.
For now, things are moving along (e.g. see the 10 chat finetuned models released last ~week, and projects like llama.cpp and friends) but a bit awkwardly due to LLaMA weights being open but not really but still. And most interestingly, a lot of questions of intuition remain to be resolved, e.g. especially around how well finetuned model work in practice, even at smaller scales.
English
pawel รีทวีตแล้ว

What are activities outside of building software that senior+ / staff & above could take part in to improve their organization?
Here are a few. What else have you observed being 'strategic' ones that could have gains on the mid-term or on the long run?

English
pawel รีทวีตแล้ว





pawel รีทวีตแล้ว

This video visualization of the depth of our oceans is mesmerizing…
English
pawel รีทวีตแล้ว
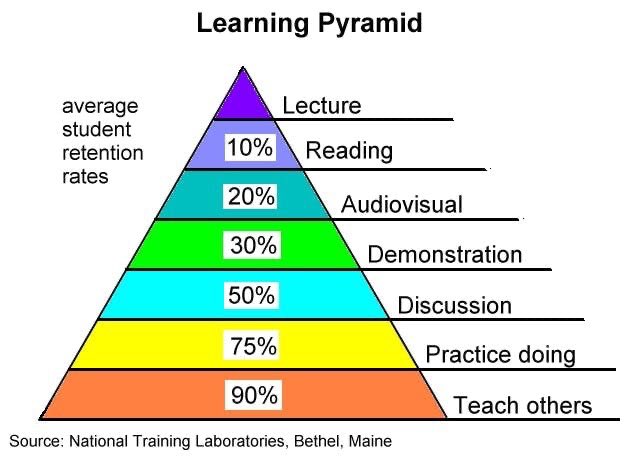
In the 1960s, the National Training Laboratories Institute developed a pyramid model to represent the retention rate of information from various activities.
The general takeaways:
• Lecture/reading are not enough
• Teaching is the most powerful form of learning
English
pawel รีทวีตแล้ว
pawel รีทวีตแล้ว
pawel รีทวีตแล้ว

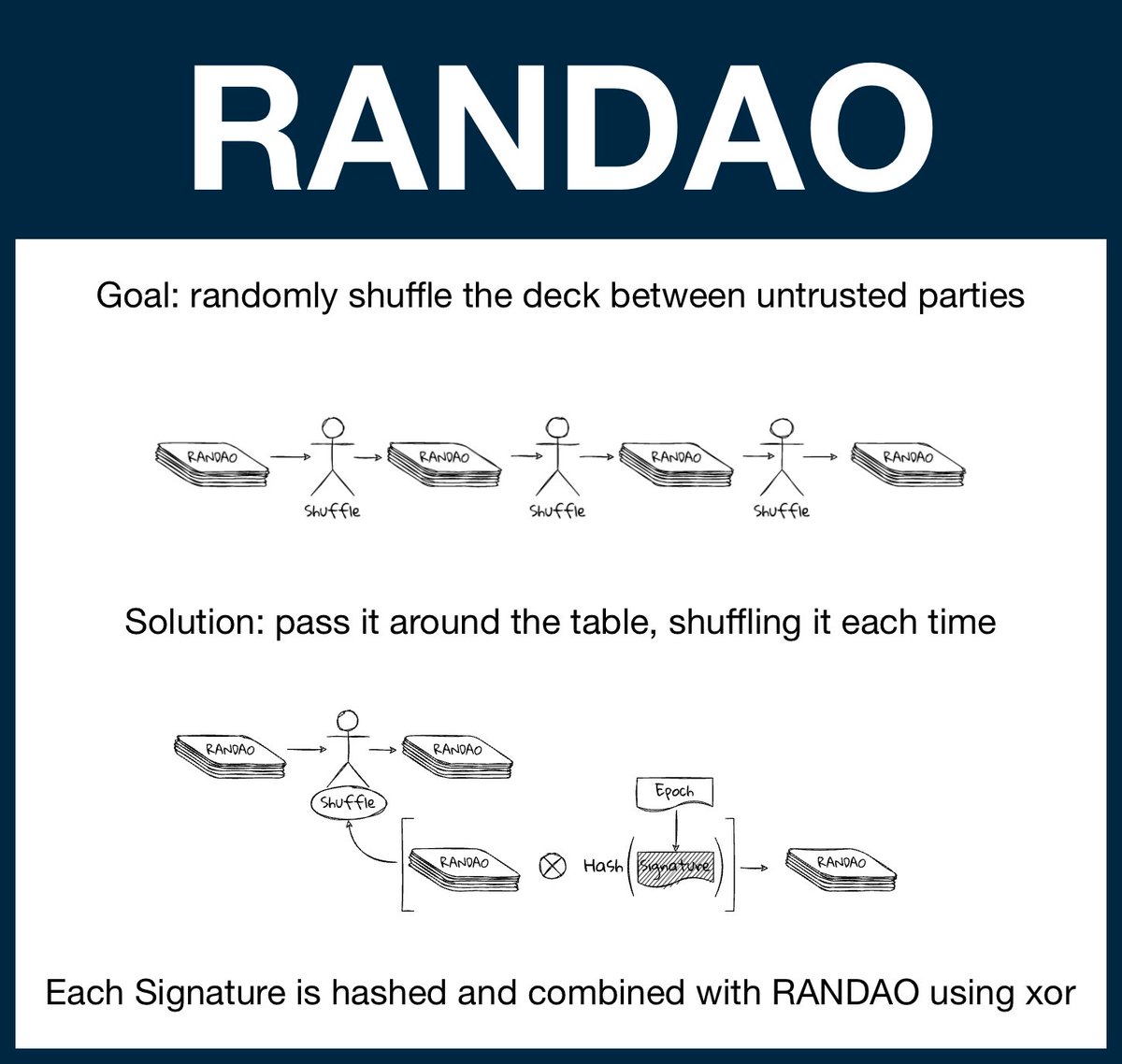
(1/20) @ethereum Fundamentals: Randomness and RANDAO
Randomness is critical property for crypto and the World Computer. Unfortunately, computers are terrible at generating randomness without external input... and the EVM has no external input.
A guide to untrusted randomness.
English
pawel รีทวีตแล้ว

The Hedge Fund Guide to Industry Analysis
100% of hedge funds, VCs, founders & strategy execs do market research.
95% do it wrong.
That's why they invest in, build & buy shitty companies.
Follow this blueprint from the top 5%:
A 9-Step Guide For Analyzing Any Industry
👇
🧵/
English
pawel รีทวีตแล้ว

Super proud of the latest and greatest in a long series of @a16z @a16zcrypto canons -- from the Crypto Canon to the NFTs Canon to DAOs, a Canon -- and now, one on *all things zero knowledge*, from theory to practice: the ZK Canon
a16zcrypto.com/zero-knowledge…
English
pawel รีทวีตแล้ว

Do you have any photographs of the Dún Laoghaire Baths that you would like to share?
We are planning an exhibition on the history of the Baths which will coincide with the opening this Autumn.
Please email your photographs to info@dlrcoco.ie by Monday, 19th September.


English

pawel รีทวีตแล้ว

And we finalized!
Happy merge all. This is a big moment for the Ethereum ecosystem. Everyone who helped make the merge happen should feel very proud today.
English