🧵 LMCache was spotlighted at Jensen Huang's GTC 2026 keynote — a real milestone for the community!
A late post, intentionally. Just one more dose of GTC after the feed rush settles. ☕
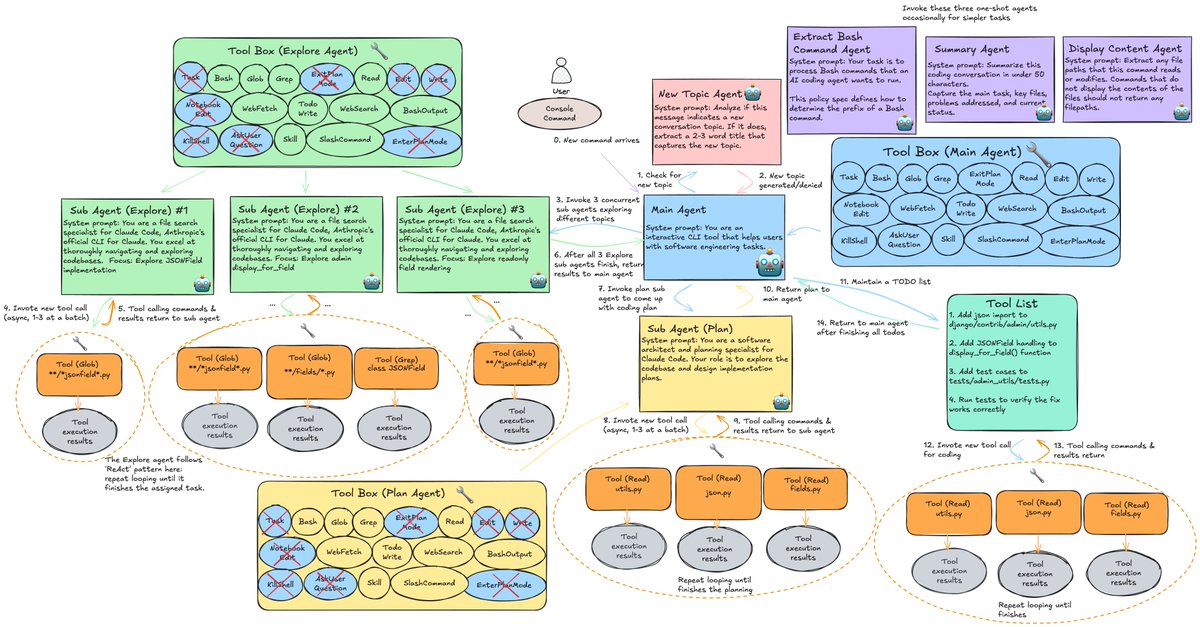
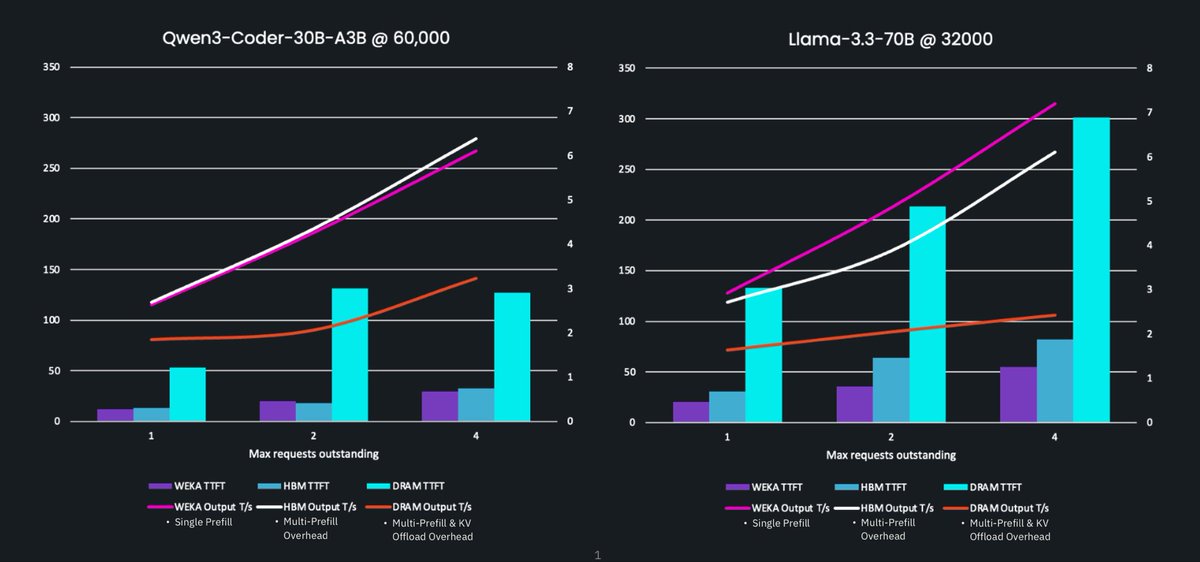
For those new here: LMCache is a KV cache sharing layer that cuts LLM serving costs & latency. It works seamlessly with vLLM and SGLang, minimal setup.
But the real story isn't the tech. It's the community that built it. In any role from researcher 🧐 , engineer 🧑💻, student 👩🎓, or just curious, there's a place for you here.
🔗 Explore LMCache
💻 Code: github.com/LMCache/LMCache
📖 Docs: docs.lmcache.ai
📝 Blog: blog.lmcache.ai/en/
⭐ Star the repo, open an issue, submit a PR. Every contribution matters!
The future of AI infrastructure is open. Come build it with us.
#LMCache #KVCache #NVIDIAGTC #LLM #opensource

English