
lmms-lab
33 posts

lmms-lab
@lmmslab
Feeling and building multimodal intelligence.
Singapore เข้าร่วม Mayıs 2024
41 กำลังติดตาม333 ผู้ติดตาม

safely engram❤️
Shuai Liu@choiszt
Agents are mind-blowing. But they don't remember things consistently. Or when they do — it's not safe. We built Engram. AES-256 encrypted. Keys stay on your device. Zero-knowledge sync. No cloud. No middleman. Use it. Your agent memory is yours. @lmmslab github.com/EvolvingLMMs-L… youtu.be/I6xVuNRMkVc
English
lmms-lab รีทวีตแล้ว

Agents are mind-blowing.
But they don't remember things consistently.
Or when they do — it's not safe.
We built Engram.
AES-256 encrypted.
Keys stay on your device.
Zero-knowledge sync.
No cloud. No middleman.
Use it.
Your agent memory is yours.
@lmmslab
github.com/EvolvingLMMs-L…
youtu.be/I6xVuNRMkVc

YouTube
English
lmms-lab รีทวีตแล้ว

lmms-lab รีทวีตแล้ว

🥳Year-End Reflection on the Growth of LMMs-Lab🥳
2025 has been a fruitful year for 🧠LMMs-Lab🧠 @lmmslab (lmms-lab.com), a non-profit open-source research organization dedicated to feeling and building the future of multimodal intelligence with:
🌟 > 12,000 Total GitHub Stars
🍴 > 2,000 Forks
🧑💻 > 30 Core Repositories
English

lmms-lab รีทวีตแล้ว
🔥LLaVA-OneVision upgraded to V1.5🔥
We @lmmslab present 🌋LLaVA-OV-1.5🌋, a fully open framework for democratized multimodal training
* Superior Performance surpassing Qwen2.5-VL
* High-Quality Data at Scale
* Ultra-Efficient Training Framework
- Repo: github.com/EvolvingLMMs-L…
English
@_jasonwei bro really have the insight and the peace mind to find more insights
English

AI research is strange in that you spend a massive amount of compute on experiments to learn simple ideas that can be expressed in just a few sentences. Literally things like “training on A generalizes if you add B”, “X is a good way to design rewards”, or “the fact that method M is sample efficient means that we should create environments with this specific property”. But somehow if you find the correct five ideas and you really understand them deeply, suddenly you’re miles ahead of the rest of the field
English

🚀Introducing Aero-1-Audio @lmmslab
⚡️Lightweight 1.5B model
💡Outperforms SOTA models like Whisper, Qwen-2-Audio & commercial services from ElevenLabs
- Blog: lmms-lab.com/posts/aero_aud…
- Code: github.com/EvolvingLMMs-L…
- Demo @Gradio: huggingface.co/spaces/lmms-la… . Thanks to @_akhaliq!
English

lmms-lab รีทวีตแล้ว

VideoMMMU is a meticulously crafted benchmark designed to evaluate multimodal models’ video understanding abilities for college-level videos.
Videos have tremendous knowledge and learning from them remains challenging for current models, but it is expected to become a crucial capability on the path toward achieving AGI.
Kairui Hu@kairuicarry
🚀Introducing Video-MMMU: Evaluating Knowledge Acquisition from Professional Videos 🎥 Knowledge-intensive Videos: Spanning 6 professional disciplines (Art, Business, Science, Medicine, Humanities, Engineering) and 30 diverse subjects, Video-MMMU challenges models to learn and apply college-level knowledge from videos. ❓ Knowledge Acquisition-based QA Design: QA pairs are aligned with the three stages of cognitive learning: · Perception: Identifying knowledge. · Comprehension: Understanding the underlying concepts. · Adaptation: Applying the knowledge to practical scenarios. 📊 Quantitative Knowledge Acquisition Assessment (Δknowledge): A novel metric that quantifies how much a model improves after watching a video, providing unique insights into its knowledge acquisition capability. Why It Matters? 🚀 Pushing the Boundaries Video-MMMU moves beyond perception and understanding of video to knowledge acquisition from video, positioning videos as a powerful medium for transmitting knowledge. 📚 Cognitive-Level Insights Video-MMMU introduces three cognitive tracks—Perception, Comprehension, and Adaptation—that mirror human learning stages, providing a structured framework to evaluate how effectively models acquire, understand, and apply knowledge. 🧠 Bridging the Gap Video-MMMU uncovers critical limitations in current LMMs and provides insights for advancing LMMs’ capabilities in knowledge acquisition from video. Project Page: videommmu.github.io ArXiv: arxiv.org/html/2501.1382…
English
lmms-lab รีทวีตแล้ว
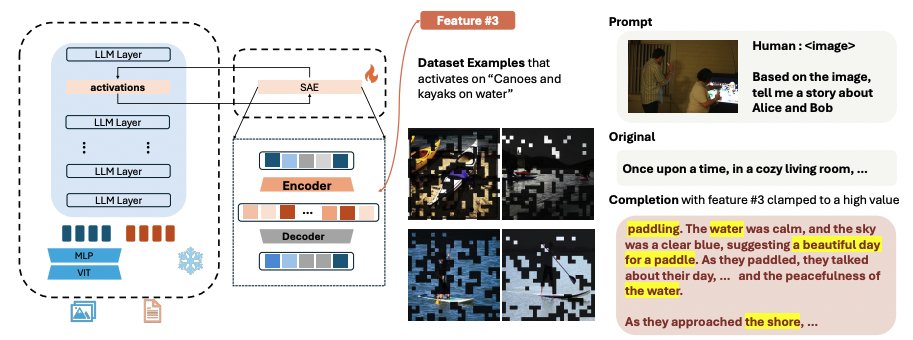
🤖Interpreting Large Multimodal Models (LMM)🤖
We present an automatic framework to identify, interpret and steer neurons within LMM for safe AGI
- Paper: arxiv.org/pdf/2411.14982
- Code: github.com/EvolvingLMMs-L…
- Model @huggingface : huggingface.co/collections/lm… . Thanks @_akhaliq !
lmms-lab@lmmslab
New work from LMMs-Lab! This time we present our latest research on the interpretation and safety of multimodal models
English
New work from LMMs-Lab!
This time we present our latest research on the interpretation and safety of multimodal models
Brian Li@Brian_Bo_Li
TL;DR We present Large Multi-modal Models Can Interpret Features in Large Multi-modal Models We successfully use a 72B large model to interpret the open-semantic features of an 8B small model, uncovering numerous important thought patterns inside multimodal models. Paper: arxiv.org/abs/2411.14982 Code: github.com/EvolvingLMMs-L… Examples: huggingface.co/datasets/lmms-…
English
lmms-lab รีทวีตแล้ว

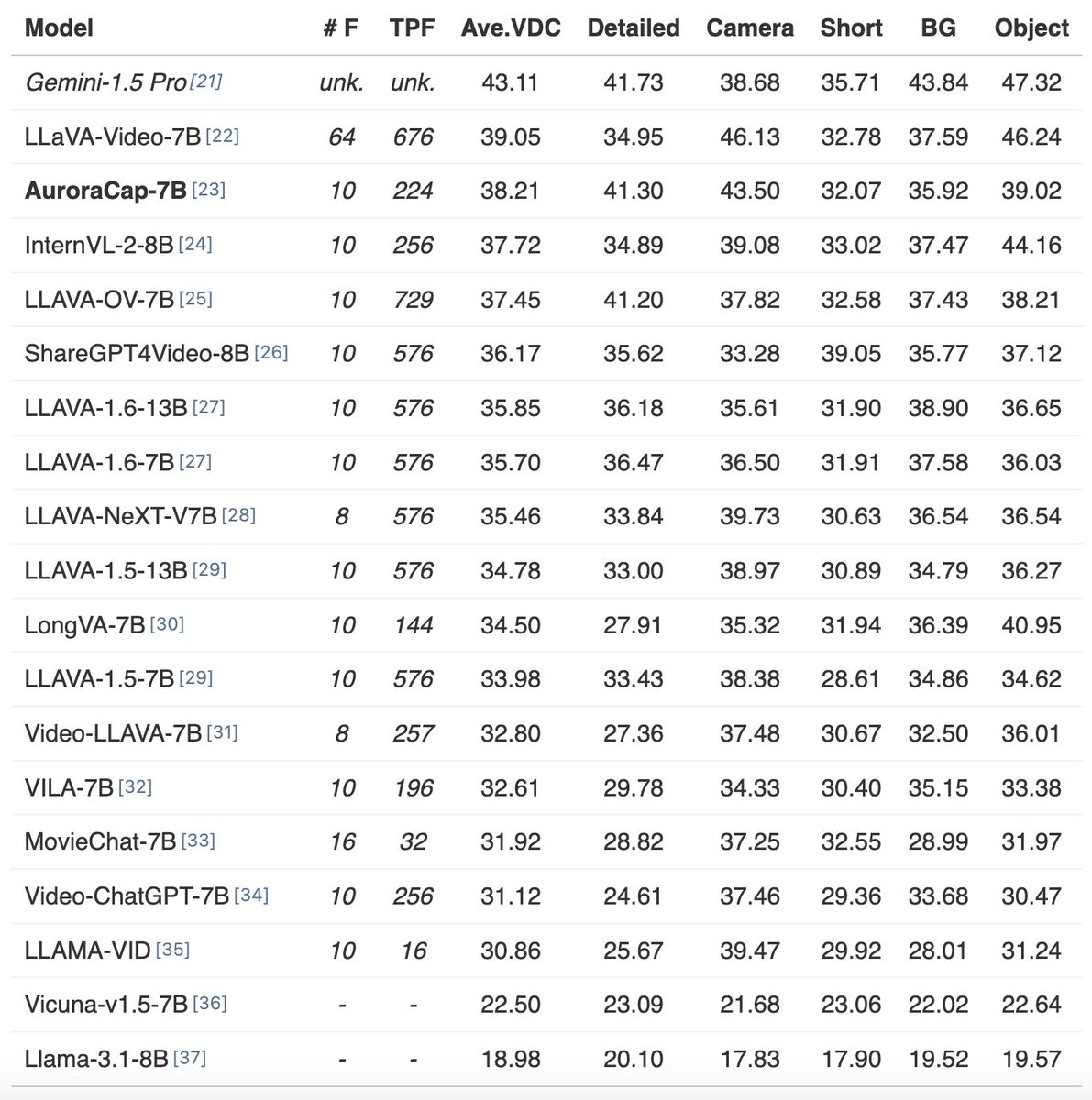
🔥 We just submitted some baselines and benchmarks to lmms-eval @lmmslab (LLaVA team) — evaluation is now just one line of code away! We call for the reporting of visual token numbers when evaluating LMM performance!
- lmms-eval repo: github.com/EvolvingLMMs-L…
- VDC, first benchmark for detailed video captions: #evaluation" target="_blank" rel="nofollow noopener">rese1f.github.io/aurora-web/#ev…
- AuroraCap (VDC baseline): github.com/rese1f/aurora
- MovieChat, first long-video understanding benchmark: github.com/rese1f/MovieCh…
- MovieChat baseline: github.com/rese1f/MovieCh…

English
👍 OpenAI's CriticGPT, not opensourced, language only
🤯 LMMs-Labs LLaVA-Critic, opensourced, for multimodal tasks
mindblown_meme.gif
Tianyi Xiong@tianyixiong23
🚀🔥Introducing LLaVA-Critic--the first open-source large multimodal model designed to assess model performance across diverse multimodal tasks! LLaVA-Critic excels in two primary scenarios: - 👨⚖️LMM-as-a-Judge: It provides pointwise scores and pairwise rankings that closely align with human and GPT-4o preferences across multiple evaluation tasks, offering a viable open-source alternative to commercial GPT models. - 🩷Preference Learning: It offers reliable reward signals that significantly enhance the visual chat capabilities of LMMs through preference alignment. To develop the "critic" capacity, we curate LLaVA-Critic-113k, a high-quality critic instruction-following dataset tailored to provide quantitative judgment and the corresponding reasoning process across a range of complex evaluation settings. Explore more: - 📰Paper: arxiv.org/abs/2410.02712 - 🪐Project Page: llava-vl.github.io/blog/2024-10-0… - 📦Dataset: huggingface.co/datasets/lmms-… - 🤗Models: huggingface.co/collections/lm… Try our released models and dataset👆
English
👍 SOTA Level Video Models
🤯 With Open-sourced Data and Training Recipes
mindblown_meme.gif
Chunyuan Li@ChunyuanLi
(1/4)🚀 Ready to supercharge your Video LLMs? 🎥Meet LLaVA-Video-178K, a high-quality dataset for video instruction tuning with 1.3M samples in captions, Q&A! 💡Perfect for further boosting Video LLMs, on top of strong capability transfer from image/language shown in LLaVA-OV🤖
English
lmms-lab รีทวีตแล้ว

We are organizing a new workshop on "Knowledge in Generative Models" at #ECCV2024 to explore how generative models learn representations of the visual world and how we can use them for downstream applications.
sites.google.com/ttic.edu/knowl…
📅30 September 2024, 2 PM
Anand Bhattad@anand_bhattad
We are organizing a new workshop on "Knowledge in Generative Models" at #ECCV2024 to explore how generative models learn representations of the visual world and how we can use them for downstream applications. For the schedule and more details, visit our website: 🔗Website: sites.google.com/ttic.edu/knowl… 📅 Date: 30 September 2024, 2 PM 📍 Location: Brown 1, MiCo Milano, Italy 🇮🇹 🎤 Speakers: Amazing lineup to provide diverse perspectives: @davidbau, David Forsyth, @shalinidemello, @YGandelsman, @phillip_isola and @liuziwei7 Organizing with @DuXiaodan, @nickKolkin, @graceluo_, @ShuangL13799063 and @grshakh See you all in Milano!
English
lmms-lab รีทวีตแล้ว
Great experience working with Lianmin to integrate LLaAV-OneVision into SGLang, and huge thanks to @PY_Z001 and @KaichenZhang358 to help finish this.
Try it on: github.com/sgl-project/sg…
Directly try our demo (with SGLang SRT API service):
llava-onevision.lmms-lab.com
LMSYS Org@lmsysorg
We worked with the LLaVA team to integrate LLaVA-OneVision into SGLang v0.3. You can now launch a server and query it using the OpenAI-compatible vision API, supporting interleaved text, multi-image, and video formats.
English

🐫 CAMEL-AI Project Meeting (US Time Friendly) - Next Monday 📢
Join us for our next development meeting to discuss our project's latest integrations and upcoming features.
🔧 New Features from the Last Sprint:
- ✨ Integrated @togethercompute: a cloud platform for building and running generative AI.
- 👨💻 Integrated @LinkedIn: get information from LinkedIn.
- 🎥 Integrated a text-to-video model to boost @CamelAIOrg’s multi-modal capability.
- 📜 PR review guidelines updated.
- 📂 Integrated @NebulaGraph: an open-source distributed graph database built for super large-scale graphs.
- 🤖 @CamelAIOrg Role-Playing Scraper for Report & Knowledge Graph Generation.
- 📚 Added cookbooks to @CamelAIOrg’s repo.
- 🤝 Integrated model from @RekaAILabs.
- ⚙️ Integrated @SambaNovaAI: deploy state-of-the-art AI.
- 🗂️ Improved collection naming for retrieval pipeline.
🚀 Features for the Coming Sprint:
- 📄 Add structured output support from @OpenAI.
- ⚙️ Unify tools settings in ChatAgent.
- ✨ Support FLUX-1: a 12 billion parameter rectified flow transformer capable of generating images from text descriptions.
- 💻 Integrate @Reddit: fetch data from it.
- 📱 Integrate @WhatsApp: popular social platform support.
- 📰 Integrate @AskNewsApp: fetch real-time news with minimal bias.
- 🖥️ Add SmoLLM model and WebGPU support.
- 👁️ Add Phi-3.5 vision-instruct VLM model.
- 📊 Add GraphDBBlock to LongtermAgentMemory.
- 🧾 Add OCR capability to @CamelAIOrg.
⏰ When: 17:00 (BST) / 09:00 (PDT)
🗺️ Where: discord.gg/Edhz4jYwMW?eve…

English

We are thrilled to have the milestone and timely release from SGLang Runtime, achieving 2.1x higher throughput for Llama 3.1 - 405B.
With highly optimized systems and easy-to-use user interface, SGLang significantly lowers the barrier of playing with latest large models.
Arena.ai@arena
We are thrilled to announce the milestone release of SGLang Runtime v0.2, featuring significant inference optimizations after months of hard work. It achieves up to 2.1x higher throughput compared to TRT-LLM and up to 3.8x higher throughput compared to vLLM. It consistently delivers superior performance when serving Llama-8B to 405B models on A100/H100 with FP8/BF16. SGLang is fully open-source and implemented in Python. As it matures from a prototype, we invite the community to join us in creating the next-generation efficient serving engine! Learn more at lmsys.org/blog/2024-07-2…
English