
Ragavan
4.3K posts
Ragavan
@ragavan
Llama @ Meta. Prev: General Catalyst, Facebook AI, Mozilla. Increase access & opportunity for every human.
Home เข้าร่วม Nisan 2008
654 กำลังติดตาม903 ผู้ติดตาม

I’m thrilled to announce what I've been working on for the past year: @HiroFinanceAI
Private beta starting today: hirofinance.com
English
Ragavan รีทวีตแล้ว

Meta COOKED! Llama 4 is out! Llama 4 Maverick (402B) and Scout (109B) - natively multimodal, multilingual and scaled to 10 MILLION context! BEATS DeepSeek v3🔥
Llama 4 Maverick:
> 17B active parameters, 128 experts, 400B total parameters > Beats GPT-4o & Gemini 2.0 Flash, competitive with DeepSeek v3 at half the active parameters > 1417 ELO on LMArena (chat performance). > Optimized for image understanding, reasoning, and multilingual tasks
Llama 4 Scout:
> 17B active parameters, 16 experts, 109B total parameters
> Best-in-class multimodal model for its size, fits on a single H100 GPU (with Int4 quantization)
> 10M token context window
> Outperforms Gemma 3, Gemini 2.0 Flash-Lite, Mistral 3.1 on benchmarks
Architecture & Innovations
> Mixture-of-Experts (MoE):
First natively multimodal Llama models with MoE
> Llama 4 Maverick: 128 experts, shared expert + routed experts for better efficiency.
Native Multimodality & Early Fusion:
> Jointly pre-trained on text, images, video (30T+ tokens, 2x Llama 3)
> MetaCLIP-based vision encoder, optimized for LLM integration
> Supports multi-image inputs (up to 8 tested, 48 pre-trained)
Long Context & iRoPE Architecture:
> 10M token support (Llama 4 Scout)
> Interleaved attention layers (no positional embeddings)
> Temperature-scaled attention for better length generalization
Training Efficiency:
> FP8 precision (390 TFLOPs/GPU on 32K GPUs for Behemoth)
> MetaP technique: Auto-tuning hyperparameters (learning rates, initialization)
Revamped Pipeline:
> Lightweight Supervised Fine-Tuning (SFT) → Online RL → Lightweight DPO
> Hard-prompt filtering (50%+ easy data removed) for better reasoning/coding
> Continuous Online RL: Adaptive filtering for medium/hard prompts
All model on Hugging Face - time to COOK!

English
Ragavan รีทวีตแล้ว

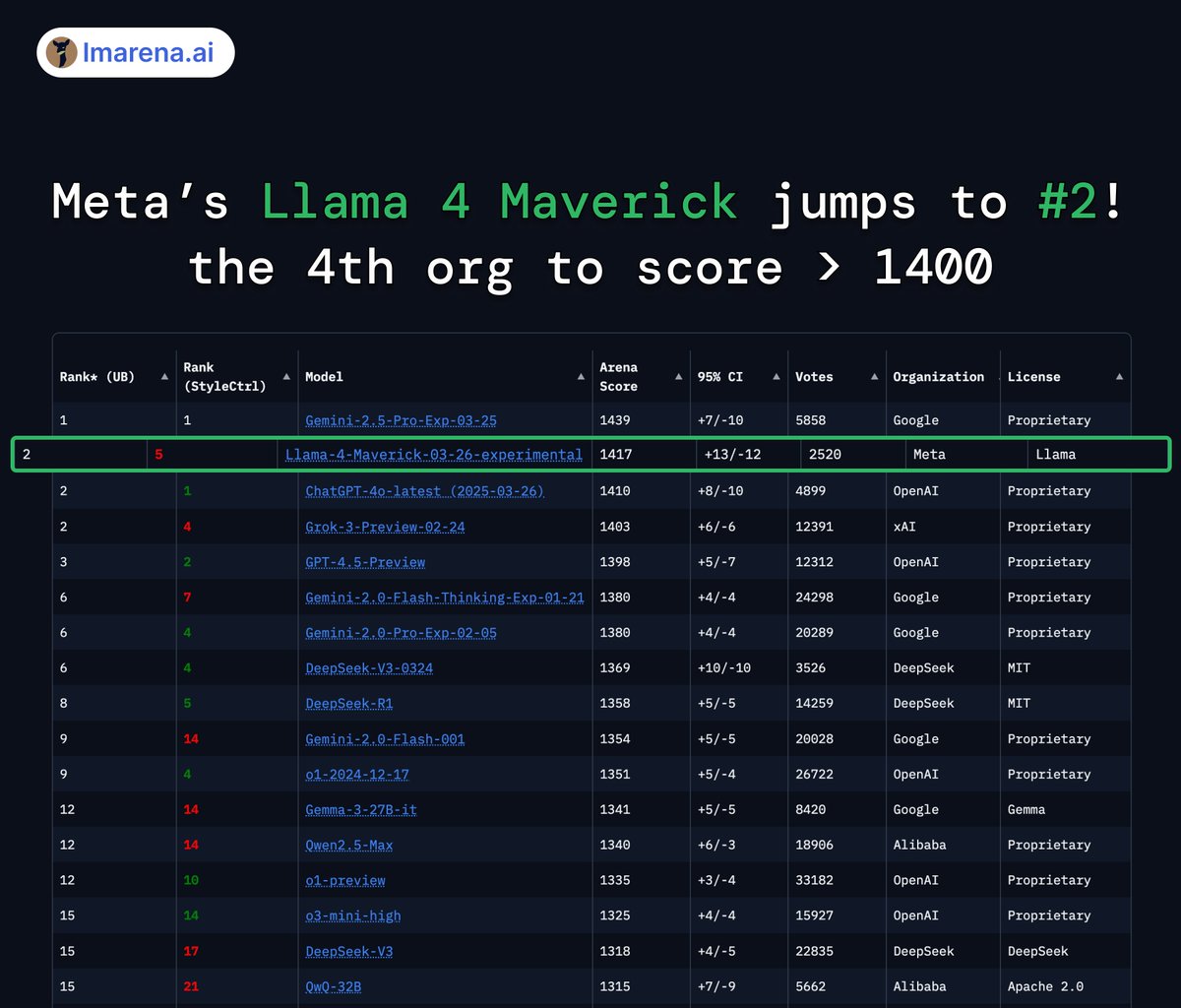
BREAKING: Meta's Llama 4 Maverick just hit #2 overall - becoming the 4th org to break 1400+ on Arena!🔥
Highlights:
- #1 open model, surpassing DeepSeek
- Tied #1 in Hard Prompts, Coding, Math, Creative Writing
- Huge leap over Llama 3 405B: 1268 → 1417
- #5 under style control
Huge congrats to @AIatMeta — and another big win for open-source! 👏 More analysis below⬇️
AI at Meta@AIatMeta
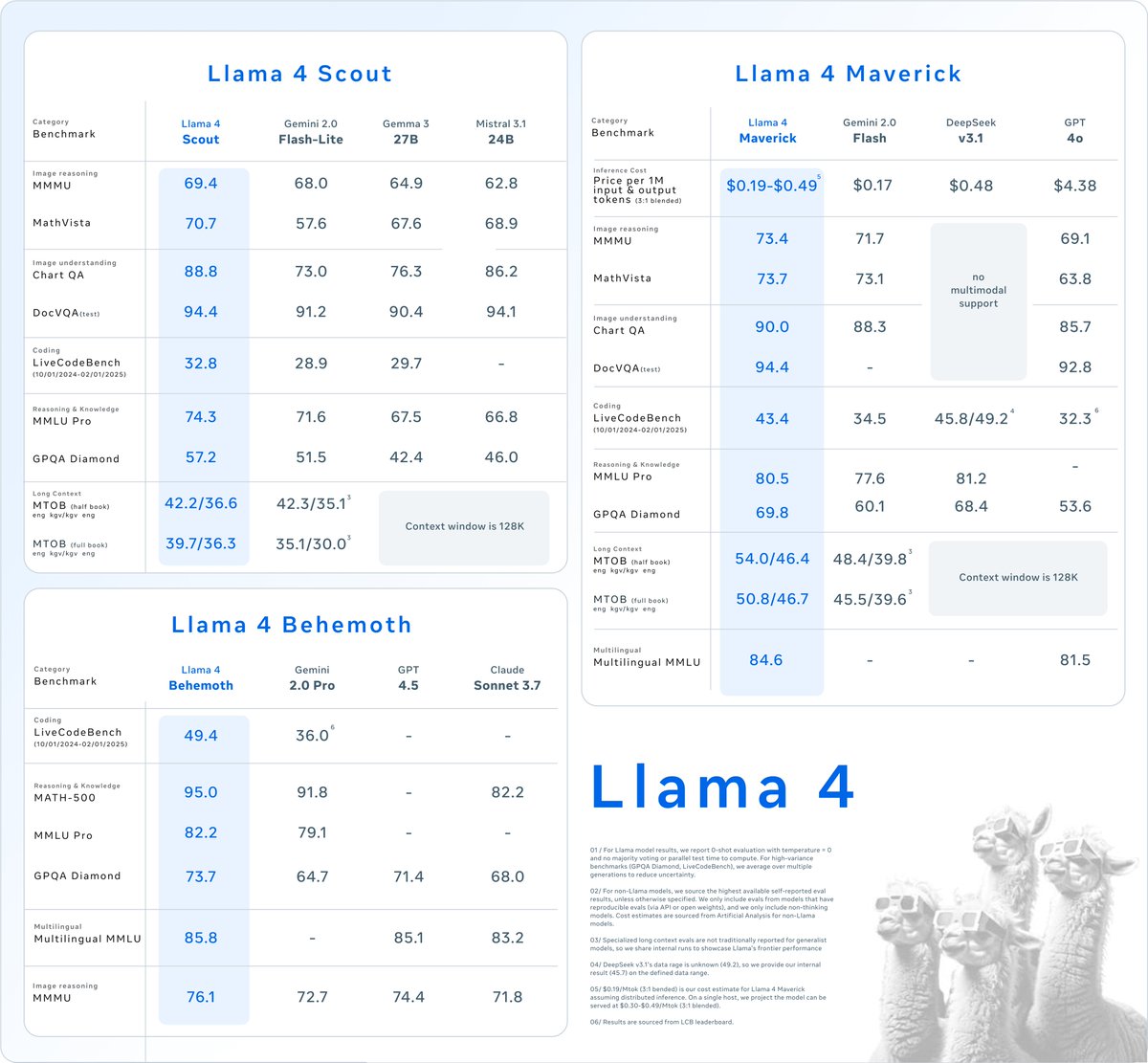
Today is the start of a new era of natively multimodal AI innovation. Today, we’re introducing the first Llama 4 models: Llama 4 Scout and Llama 4 Maverick — our most advanced models yet and the best in their class for multimodality. Llama 4 Scout • 17B-active-parameter model with 16 experts. • Industry-leading context window of 10M tokens. • Outperforms Gemma 3, Gemini 2.0 Flash-Lite and Mistral 3.1 across a broad range of widely accepted benchmarks. Llama 4 Maverick • 17B-active-parameter model with 128 experts. • Best-in-class image grounding with the ability to align user prompts with relevant visual concepts and anchor model responses to regions in the image. • Outperforms GPT-4o and Gemini 2.0 Flash across a broad range of widely accepted benchmarks. • Achieves comparable results to DeepSeek v3 on reasoning and coding — at half the active parameters. • Unparalleled performance-to-cost ratio with a chat version scoring ELO of 1417 on LMArena. These models are our best yet thanks to distillation from Llama 4 Behemoth, our most powerful model yet. Llama 4 Behemoth is still in training and is currently seeing results that outperform GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on STEM-focused benchmarks. We’re excited to share more details about it even while it’s still in flight. Read more about the first Llama 4 models, including training and benchmarks ➡️ go.fb.me/gmjohs Download Llama 4 ➡️ go.fb.me/bwwhe9
English

@Ahmad_Al_Dahle Does Maverick have the 10 million token context too?
English

Introducing our first set of Llama 4 models!
We’ve been hard at work doing a complete re-design of the Llama series. I’m so excited to share it with the world today and mark another major milestone for the Llama herd as we release the *first* open source models in the Llama 4 collection 🦙. Here are some highlights:
📌 The Llama series have been re-designed to use state of the art mixture-of-experts (MoE) architecture and natively trained with multimodality. We’re dropping Llama 4 Scout & Llama 4 Maverick, and previewing Llama 4 Behemoth.
📌 Llama 4 Scout is highest performing small model with 17B activated parameters with 16 experts. It’s crazy fast, natively multimodal, and very smart. It achieves an industry leading 10M+ token context window and can also run on a single GPU!
📌 Llama 4 Maverick is the best multimodal model in its class, beating GPT-4o and Gemini 2.0 Flash across a broad range of widely reported benchmarks, while achieving comparable results to the new DeepSeek v3 on reasoning and coding – at less than half the active parameters. It offers a best-in-class performance to cost ratio with an experimental chat version scoring ELO of 1417 on LMArena. It can also run on a single host!
📌 Previewing Llama 4 Behemoth, our most powerful model yet and among the world’s smartest LLMs. Llama 4 Behemoth outperforms GPT4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on several STEM benchmarks. Llama 4 Behemoth is still training, and we’re excited to share more details about it even while it’s still in flight.
A big thanks to all of our launch partners (full list in blog) for helping us bring Llama 4 to developers everywhere including @huggingface, @togethercompute, @SnowflakeDB, @ollama, @databricks and many others👏 This is just the start, we have more models coming and the team is really cooking – look out for Llama 4 Reasoning 😉
A few weeks ago, we celebrated Llama being downloaded over 1 billion times. Llama 4 demonstrates our long-term commitment to open source AI, the entire open source AI community, and our unwavering belief that open systems will produce the best small, mid-size and soon frontier models. Llama would be nothing without the global open source AI community & we are so ready to begin this next chapter with you. 🦙
Read more about the release here: llama.com, and try it in our products today.

English
Excited to share a research breakthrough from our team. It's fun, it's personal, it's customizable. Huge congrats to the team that worked hard to get to this milestone.
ai.meta.com/blog/movie-gen…
AI at Meta@AIatMeta
🎥 Today we’re premiering Meta Movie Gen: the most advanced media foundation models to-date. Developed by AI research teams at Meta, Movie Gen delivers state-of-the-art results across a range of capabilities. We’re excited for the potential of this line of research to usher in entirely new possibilities for casual creators and creative professionals alike. More details and examples of what Movie Gen can do ➡️ go.fb.me/kx1nqm 🛠️ Movie Gen models and capabilities Movie Gen Video: 30B parameter transformer model that can generate high-quality and high-definition images and videos from a single text prompt. Movie Gen Audio: A 13B parameter transformer model that can take a video input along with optional text prompts for controllability to generate high-fidelity audio synced to the video. It can generate ambient sound, instrumental background music and foley sound — delivering state-of-the-art results in audio quality, video-to-audio alignment and text-to-audio alignment. Precise video editing: Using a generated or existing video and accompanying text instructions as an input it can perform localized edits such as adding, removing or replacing elements — or global changes like background or style changes. Personalized videos: Using an image of a person and a text prompt, the model can generate a video with state-of-the-art results on character preservation and natural movement in video. We’re continuing to work closely with creative professionals from across the field to integrate their feedback as we work towards a potential release. We look forward to sharing more on this work and the creative possibilities it will enable in the future.
English

This is my personal journey to Augment, and our vision for how to best help developers.
blog.almaer.com/introducing-au…
Dion Almaer@dalmaer
I'm so excited to introduce Augment, the company where I get to focus on supporting developers, ridding them of toil and allowing them to enjoy building!
English
@mattshumer_ It's been humbling to see the community come together on Llama 3. Thank you. 🙏🙏
English

It's been a week since LLaMA 3 dropped.
In that time, we've:
- extended context from 8K -> 128K
- trained multiple ridiculously performant fine-tunes
- got inference working at 800+ tokens/second
If Meta keeps releasing OSS models, closed providers won't be able to compete.
English
@deviparikh Proud of you, @deviparikh! Going to miss you at Meta, but so so so excited for you :)
English

Update: I left Meta yesterday. After 7.5 years.
I am sad, nervous, and excited.
Sad because I'll miss Meta! I've felt tremendously valued my entire time at Meta (first in FAIR and recently in GenAI). I'll miss the people and being in the thick of things.
Nervous because who in their right mind walks away from the job I had in times like these (leading research efforts in generative media and multimodal LLMs)?!
And excited for new experiences :) Stay tuned for when I have more to share!
English
Ragavan รีทวีตแล้ว

(1/6): We are entering the Age of Global Resilience. And today with my partner and @generalcatalyst MD Paul Kwan, we’re publishing our thesis on what this is and why we’re all-in: generalcatalyst.com/perspectives/b…
English

It's been a minute, but @mikeyk and I are back at it with Artifact - a personalized news feed using the latest ai tech. Visit artifact.news to sign up and join the community.
English

drawing a big circle that says "GPT-4" on it and constantly looking back at the audience for approval like a contestant on the price is right


English
What are the AI-native frames that will define how consumers interact with intelligent software systems?
What are the AI-native nouns & verbs that will form the vocabulary of this next generation of products?
Are you building these today? We’d love to chat. Cc @generalcatalyst
English
