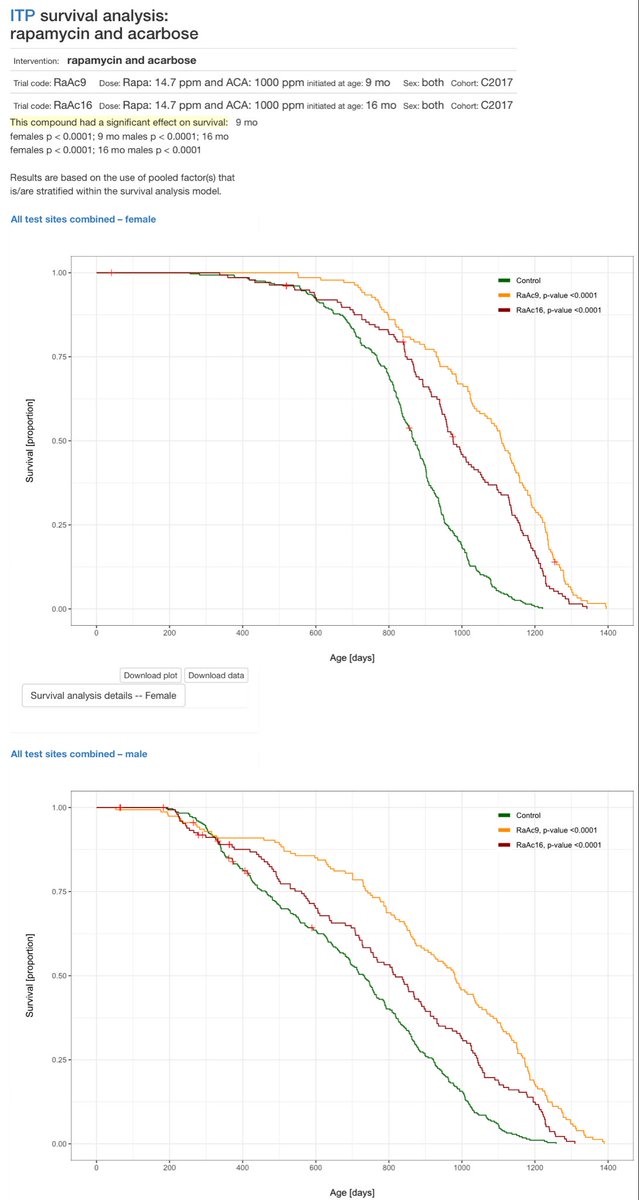
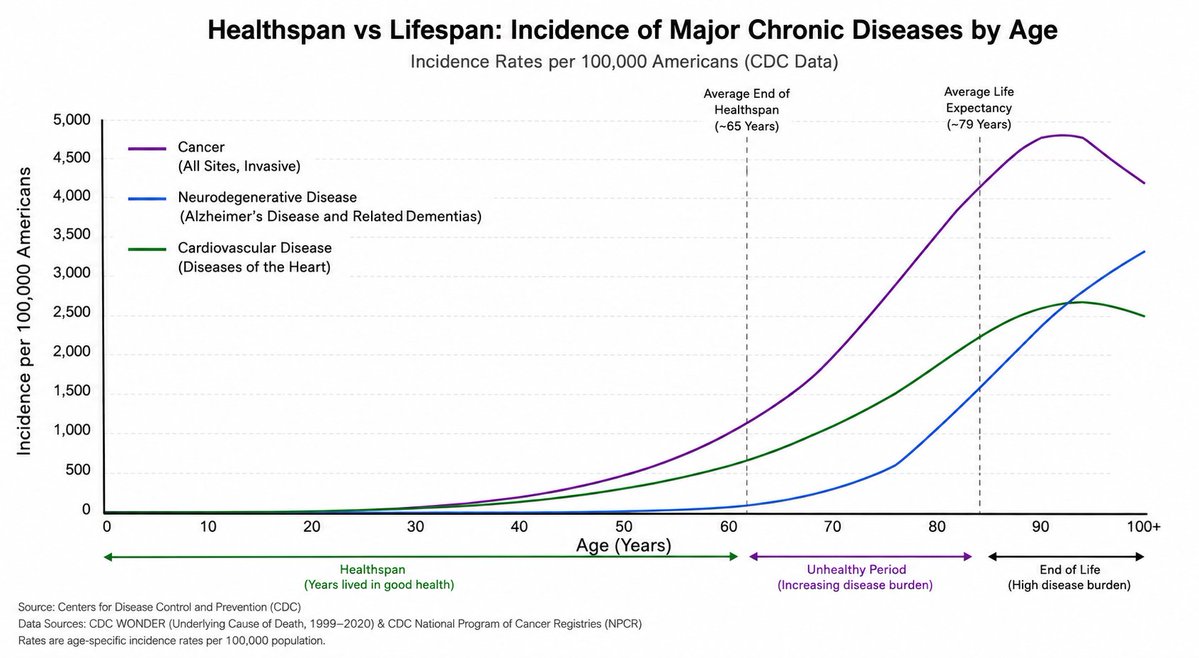
@EricTopol Because fixing the root cause of limited lifespan, aging, will obviously also extend healthspan. Such as in the super centenarians - why ignore them?
English
scikityearn
128 posts




1/ 🚀 We’re excited to share Tuna-2: Pixel Embeddings Beat Vision Encoders for Multimodal Understanding and Generation! Tuna-2 is a native unified multimodal model that supports visual understanding, text-to-image generation, and image editing directly from pixel embeddings. 🐟✨ 📄 Paper: arxiv.org/abs/2604.24763 🌐 Project: tuna-ai.org/tuna-2 💻 Code: github.com/facebookresear… Most unified multimodal models still rely on pretrained vision encoders, which add architectural complexity and can create representation mismatches between understanding and generation. Tuna-2 asks a simple question: Do we still need vision encoders? 👀 Our answer is No! Tuna-2 has a completely encoder-free architecture, where images are processed directly by a unified transformer together with text tokens. Take a glimpse at what our model can generate ↓ 🎨🖼️


One bearish sign of all the AI layoffs is that the companies couldn't figure out how to produce even more by keeping the people and adding AI. I'm not entirely sure how to think about this.


As of this morning, providers on our platform can now send prescriptions for Zepbound® vials and KwikPen®, as well as Foundayo™, to the LillyDirect® pharmacy and access self-pay pricing for our customers because of an expansion in our platform’s functionality. In many ways, today reminds me of Netflix’s early days, when everyone talked about whether they would have the latest blockbuster in their catalog. As if Netflix’s success depended on its ability to become the distribution channel for a single film. They were missing the forest for the trees: Netflix wasn’t just renting DVDs. It was changing consumer behavior by ruthlessly prioritizing choice and inventing new pathways to the things people wanted the most. By offering a full range of FDA-approved GLP-1s on our platform, we’re similarly giving our customers more choices through all the tools we have available – and we’ll continue to push here on behalf of everyone who depends on us for their care. Read more on how we’re making this possible, including important info, here: news.hims.com/newsroom/full-…

2 years from now: We will be routing between several cloud models and several local models based not only on application, but based on tasks within that application, and requirements for latency, performance, cost, and capabilities. So there will be a pressure on costs and also for providers to provide specialized models.


Michael Shermer, the founder of ’Skeptic’ magazine, makes the case for why President Trump’s promised disclosure of UFO files probably won’t amount to much. thefp.com/p/what-does-am…



If current demographic trends hold, Europe (the entire continent) may soon record more live births than all of China. That would probably be the first time since the Qing dynasty 300 years ago, possibly even the first time in history.

Apple Research just published something really interesting about post-training of coding models. You don't need a better teacher. You don't need a verifier. You don't need RL. A model can just… train on its own outputs. And get dramatically better. Simple Self-Distillation (SSD): sample solutions from your model, don't filter them for correctness at all, fine-tune on the raw outputs. That's it. Qwen3-30B-Instruct: 42.4% → 55.3% pass@1 on LiveCodeBench. +30% relative. On hard problems specifically, pass@5 goes from 31.1% → 54.1%. Works across Qwen and Llama, at 4B, 8B, and 30B. One sample per prompt is enough. No execution environment. No reward model. No labels. SSD sidesteps this by reshaping distributions in a context-dependent way — suppressing distractors at locks while keeping diversity alive at forks. The capability was already in the model. Fixed decoding just couldn't access it. The implication: a lot of coding models are underperforming their own weights. Post-training on self-generated data isn't just a cheap trick — it's recovering latent capacity that greedy decoding leaves on the table. paper: arxiv.org/abs/2604.01193 code: github.com/apple/ml-ssd

Yeah, I agree slowdowns/pauses on either hardware or frontier AI work or both are good. If "it's unrealistic because the other guy will move forward anyway", then the right solution is for the entities involved (corps and govs) to publicly say "I am willing to not do [X] if [entities A, B, C] also make a similar pledge", and move in good faith from there.

There are often posts mentioning that I donated a very large amount of funds to @FLI_org years ago and connecting me to various policy actions that they take. I thought I would make clear the record both on the nature of my connection to them, and on similarities and differences between my approach to the AI risk topic and theirs. First, what happened: * In 2021, I received a large amount of SHIB and other dog coins, seemingly because the creators wanted to use "Vitalik owns half our supply" as a marketing tactic and be "the next Dogecoin" * The tokens quickly rose in value, and at the peak the "book value" of those tokens was over a billion dollars * I felt that surely this was a bubble, it would pop quickly and the price would drop massively, and so I scrambled to retrieve the funds from my cold wallet (this included things like calling my stepmother in Canada and asking her to go into my closet and read out a 78-digit number, and then adding it to a different 78-digit number transcribed from a paper in my backpack). I sold what I could for ETH and donated to relatively more "normal" things (eg. $50m to GiveWell). But then I was still left with lots of SHIB * I sent half to @CryptoRelief_ (half of _those_ funds ended up supporting Balvi, and the other half is being spent by @sandeep and team on improving medical infrastructure in India). I sent the other half to FLI * At the time, they presented me with a comprehensive roadmap that focused on improving all major existential risks (bio, nuclear, AI...) as well as general pro-peace and pro-epistemics (ie. helping us know the truth in adversarial contexts) initiatives * I thought that surely they would cash out at most $10-25M, because there's no way the SHIB market is deep enough to cash out more * Instead, they managed to cash out ... something like $500M (same with cryptorelief) * Since then, FLI had an internal pivot by which they started focusing on cultural and political action as a primary method, quite different from the original approach. * Their justification is that the situation has changed greatly since 2021, AGI is coming very soon, and their pivot is needed to affect the world fast enough, and to counteract the lobbying warchests of large AI companies. * My worry is that large-scale coordinated political action with big money pools is a thing that can easily lead to unintended outcomes, cause backlashes, and solve problems in a way that is both authoritarian and fragile, even if it was not originally intended that way. * For example, their primary approach to biosafety has been "how do we put guards into bio-synthesis devices and AI models so that they refuse to create bad stuff?". I view this as a very fragile solution: there are many ways to jailbreak, fine-tune or otherwise get around such restrictions. Ultimately, putting all your eggs into this strategy can lead to very dark places like "let's ban open-source AI" and then "let's support one good-guy AI company to establish global dominance and don't let anyone else get to the same level". Approaches like this VERY EASILY backfire: they make the rest of the world your enemy. * More generally, historical experience tells us that when regulations are made on dangerous tech, "national security" orgs (today, realistically incl Palantir) inevitably get exempted, and in fact those very same orgs are a major source of risk (see: pandemic lab leaks typically coming from government programs). This is something I worry about. * My approach on these topics has been centered around d/acc: build the tech (eg. air filtering, early detection, continuous passive PCR-quality air testing, prophylactics etc for pandemics, greatly improving software and hardware verifiability for cybersecurity...) to help us survive a much higher-capability world safely, and open-source the tech so that the entire world can freely incorporate it. * This is the sort of thing that the ~$40m I recently allocated is for. A big part of that pot is for secure hardware, which is good both for Ethereum users who do not want to lose their coins, and for humanity if we want ubiquitous computer chips to not be hackable (incl by AI) and spy on us. If I had the FLI warchest and tweet-chest, I would use it to do more of those things. * I have shared my difference in perspective with them on several occasions. * At the same time, I've also been heartened by many of @FLI_org 's recent moves. I think the "pro-human AI declaration" ( humanstatement.org ) is a very good philosophical path forward. It unites conservatives, progressives and libertarians, America, Europe and China, people worried about unemployment, surveillance, psychosis and paperclip doom, atheists and the Pope. They have also been researching ways to avoid concentration of power resulting from AI. These things are all good. I wish them best of luck on these positive initiatives, and hope that they operate with the caution and wisdom that their task deserves.
My self-sovereign / local / private / secure LLM setup, April 2026 vitalik.eth.limo/general/2026/0…