ทวีตที่ปักหมุด

Bitter-pilled trading has been shipped 🫡
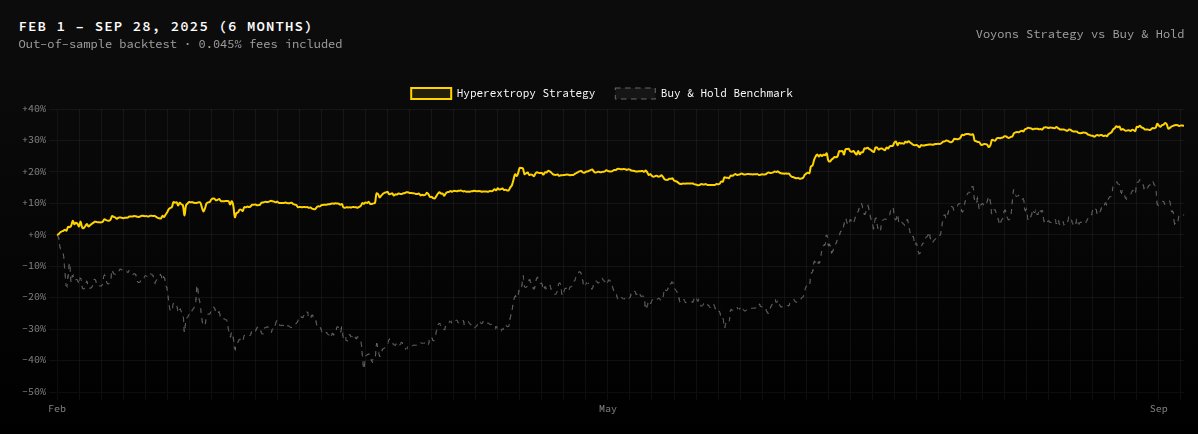
Introducing Hyperextropy 🧵
English
Ted - 🥖/acc
780 posts

@ted_engineer
🇫🇷 / 25yo / dad / deep learning chef @duonlabshq


Last week I had a great call with @_weidai about the robot economy. VCs clearly understand the market opportunity, but the sector still needs real use cases. Are there any agents ready to be deployed on Backed, with real iterations?
wow google might've popped the ai bubble, memory stocks down massively today: their new algorithm shrinks an AI model's memory by 6X WITHOUT reducing it's intelligence making it 8x faster with the SAME # of GPUs: if this works - we don't need as many GPUs to train AI - kv-cache is basically a model's short term memory. it gets massive pretty quickly = larger, slower, expensive ai - google's algo compresses it to just 3-bits with ZERO loss in accuracy (usually models are like 32-bit) the combined market cap of micron and sandisk is $527 billion and im not even factoring in SK hynix and samsung ai has driven up memory prices by 500%+ over the last few months - if google's algo scales then this might crash.

🚨 Shocking: Frontier LLMs score 85-95% on standard coding benchmarks. We gave them equivalent problems in languages they couldn't have memorized. They collapsed to 0-11%. Presenting EsoLang-Bench. Accepted to the Logical Reasoning and ICBINB workshops at ICLR 2026 🧵

Not buying the 2007 scenario...

introducing Flywheel: the infrastructure for autonomous research.

insane sequence of statements buried in an Alibaba tech report



Asymmetric hardware scaling is here. Blackwell tensor cores are now so fast, exp2 and shared memory are the wall. FlashAttention-4 changes the algorithm & pipeline so that softmax & SMEM bandwidth no longer dictate speed. Attn reaches ~1600 TFLOPs, pretty much at matmul speed! joint work w/ Markus Hoehnerbach, Jay Shah(@ultraproduct), Timmy Liu, Vijay Thakkar (@__tensorcore__ ), Tri Dao (@tri_dao) 1/


We identified an issue with the Mamba-2 🐍 initialization in HuggingFace and FlashLinearAttention repository (dt_bias being incorrectly initialized). This bug is related to 2 main issues: 1. init being incorrect (torch.ones) if Mamba-2 layers are used in isolation without the Mamba2ForCausalLM model class (this has been already fixed: github.com/fla-org/flash-…). 2. Skipping initialization due to meta device init for DTensors with FSDP-2 (github.com/fla-org/flash-… will fix this issue upon merging). The difference is substantial. Mamba-2 seems to be quite sensitive to the initialization. Check out our experiments at the 7B MoE scale: wandb.ai/mayank31398/ma… Special thanks to @kevinyli_, @bharatrunwal2, @HanGuo97, @tri_dao and @_albertgu 🙏 Also thanks to @SonglinYang4 for quickly helping in merging the PR.

actually wtf somebody wrote a paper about the 491-parameter transformer they trained for 10-digit addition turns out Codex can one-shot the task. 100% with only 343 parameters. the solution is a single function 'hand_set_weights_magic' and it looks like this: