ทวีตที่ปักหมุด

Tensor Fiend
441 posts

@tensorfiend
life revolving around tensors





Simple Thought Experiments: A tiny dataset for end to end LLM training. First step of building a tiny LLM (inspired by @karpathy). Had many learnings in the process of creating synthetic data. Tried my best to make the data better in my budget. tensorwrites.com/posts/ste-data…
Working on some cool looking project.
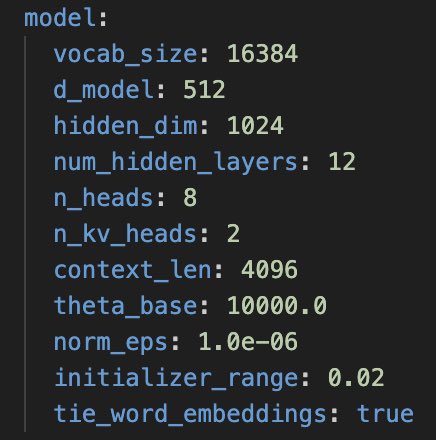
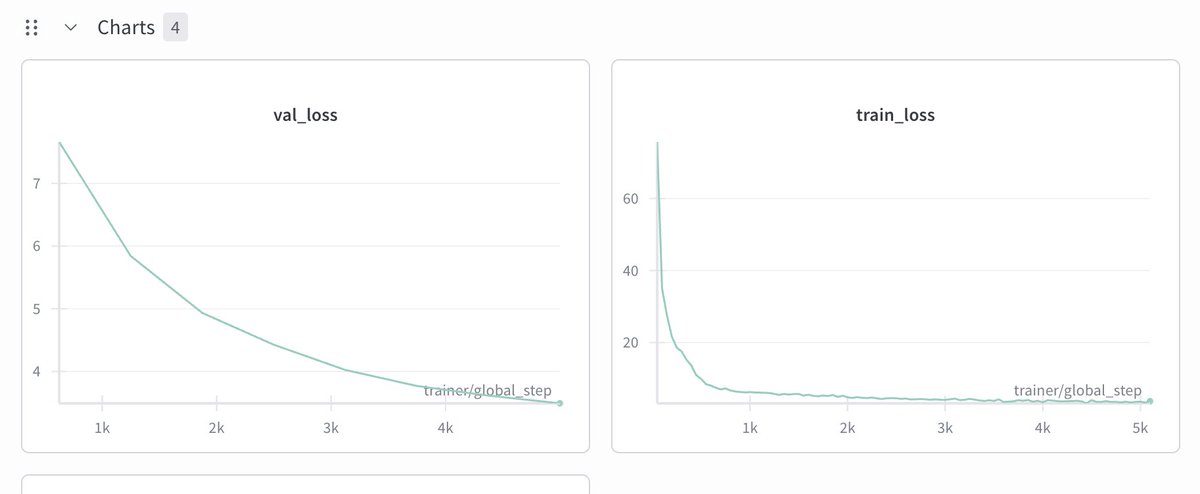
Generated samples after 5000 steps. Actually these are better than what my prev experiment generated

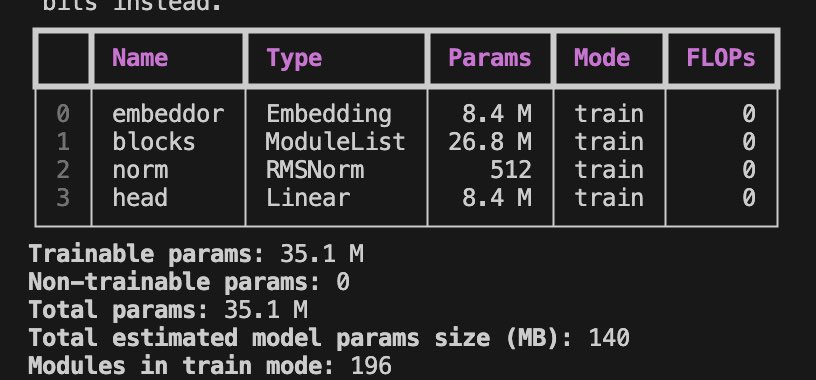
Training a Qwen 3 style 35M parameter model on @jarvislabsai . Training looks ok so far. @LightningAI makes everything super simple 🙇🏽♂️
Have been using Claude Code with Opus 4.6 for few days I am in fear of losing my job
Doomer post! It's over! It's JOE over! Last night I installed antigravity and simply asked it this: implement a mini transformer model optimized with kernels for my M4 MacBook. In 15 mins it gave me a fully tested, well optimized implementation. I saw the damn thing make mistakes, test, fix mistakes, log information, pull up system information, search online, think, on and on till it gave me exactly what I wanted. I spent 15 mins with my jaw wide open. It would have taken me at least a week 2 years ago. Now it's 15 mins. Now all you need is a verifiable idea. Don't even get me started on the internal version of Antigravity with internal models optimized for Googlers. It's a new era. Maybe I was too hard on openclaw.
@karpathy @JTMcG3 I was inspired by TinyStories and built one synthetic dataset myself (still not open sourced but will do it soon). Currently working on pretraining (this was inspired by nanochat 🫡)! tensorwrites.com/posts/ste-data…



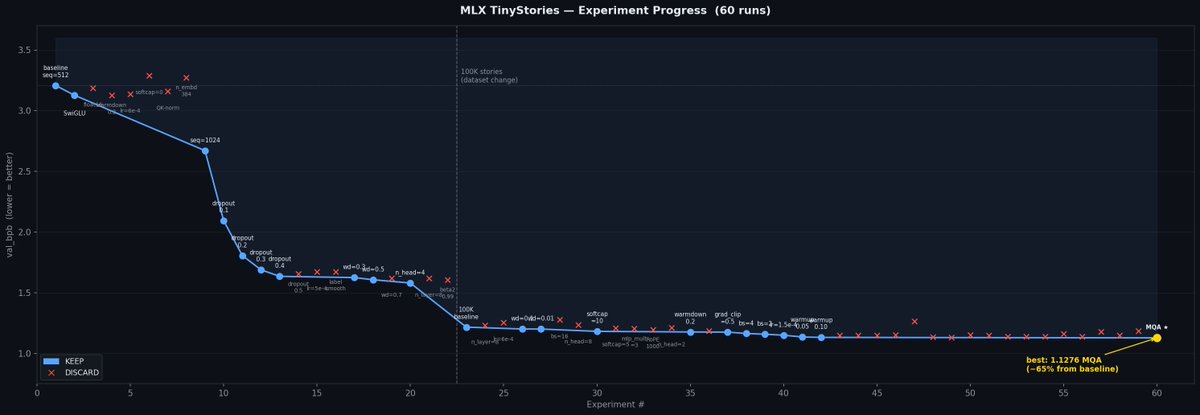
I packaged up the "autoresearch" project into a new self-contained minimal repo if people would like to play over the weekend. It's basically nanochat LLM training core stripped down to a single-GPU, one file version of ~630 lines of code, then: - the human iterates on the prompt (.md) - the AI agent iterates on the training code (.py) The goal is to engineer your agents to make the fastest research progress indefinitely and without any of your own involvement. In the image, every dot is a complete LLM training run that lasts exactly 5 minutes. The agent works in an autonomous loop on a git feature branch and accumulates git commits to the training script as it finds better settings (of lower validation loss by the end) of the neural network architecture, the optimizer, all the hyperparameters, etc. You can imagine comparing the research progress of different prompts, different agents, etc. github.com/karpathy/autor… Part code, part sci-fi, and a pinch of psychosis :)