unbug
2.4K posts

unbug
@unbug
https://t.co/5sKsiEXX8Y, CODELF (Github star 14k, https://t.co/z1Mfw3yNcy), #MIHTool (Mentioned in Google I/O'13, https://t.co/HS3Jxj8Zho)







🧮 MATH 500 results for TriAttention on Gemma4-26B-A4B-it (5-bit quantized, M3 Ultra 512GB) using MLX-VLM TA-2048 preserves 96% of baseline accuracy (22/30 vs 23/30) with KV cache capped at 2048 tokens, regardless of reasoning length. Throughput stays rock-solid at ~77 tok/s across all modes. Our gap is larger than the paper's (-3.4% vs -1.2% at budget=2048) because: 1. We ran Gemma4 A4B in non-thinking mode 2. Only 5 full-attention layers (50 are sliding window), less surface area for TriAttention. 3. 5-bit quantization maybe adding noise on top of KV compression The takeaway: TriAttention works on Apple Silicon with MLX. Even on a non-reasoning mode with aggressive quantization, TA-2048 keeps accuracy intact. 🍎

Open source is dead. That’s not a statement we ever thought we’d make. @calcom was built on open source. It shaped our product, our community, and our growth. But the world has changed faster than our principles could keep up. AI has fundamentally altered the security landscape. What once required time, expertise, and intent can now be automated at scale. Code is no longer just read. It is scanned, mapped, and exploited. Near zero cost. In that world, transparency becomes exposure. Especially at scale. After a lot of deliberation, we’ve made the decision to close the core @calcom codebase. This is not a rejection of what open source gave us. It’s a response to what risks AI is making possible. We’re still supporting builders, releasing the core code under a new MIT-licensed open source project called cal. diy for hobbyists and tinkerers, but our priority now is simple: Protecting our customers and community at all costs. This may not be the most popular call. But we believe many companies will come to the same conclusion. My full explanation below ↓





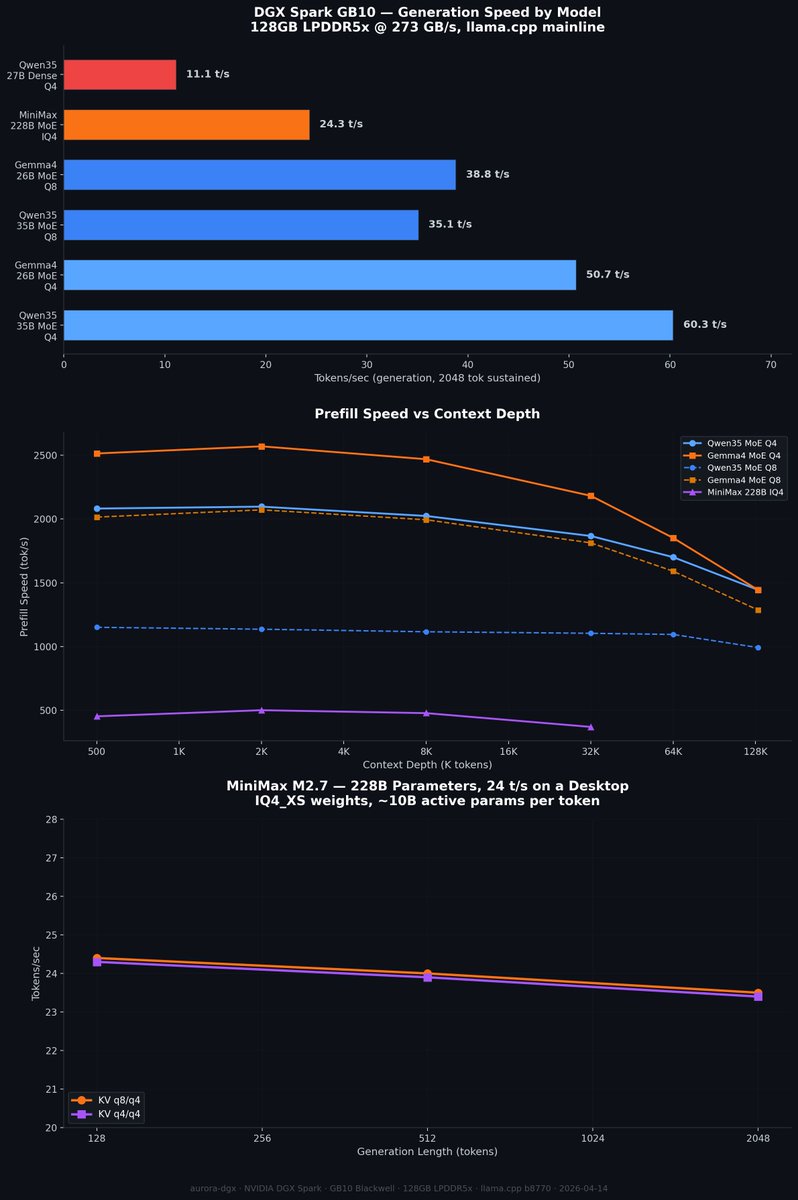
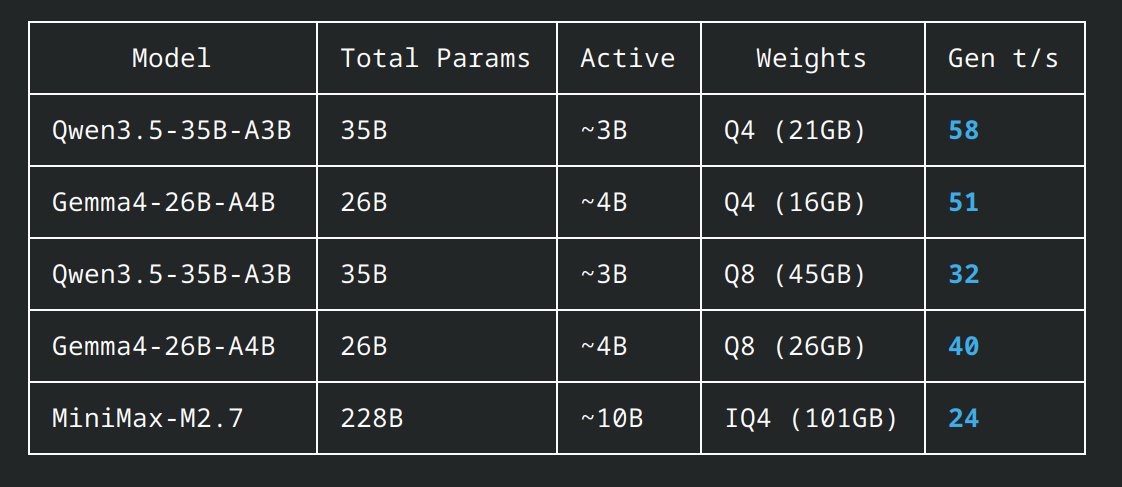




MiniMax M2.7 at home running on 4x DGX Sparks vLLM serving full BF16 weights, 200k context OpenCode having the model monitor its own hardware and report thermals, tokens/sec, TTFT, and other runtime stats in real time What benchmarks / workflows / things do you wanna see next?





