
always-on-chain.eth 🦇🔊
50 posts

Introducing Simmy: the Youtube for playable stories.
Today, Simmy is #3 in its US App Store category, starting with the $1B romantic fiction vertical.
We believe playable stories will redefine entertainment forever.
Comment for an INVITE CODE to our public beta.
(1/8) THREAD 🧵
English
always-on-chain.eth 🦇🔊 รีทวีตแล้ว


In the last year, I’ve made over $1M using AI.
I wrote a memo on the exact strategies, systems, and mindset that got me here.
When we first started using AI to build software for clients, people doubted us.
Now, It’s standard practice.
If you want the playbook. Comment "Memo" and follow me. I’ll DM it to you.

English

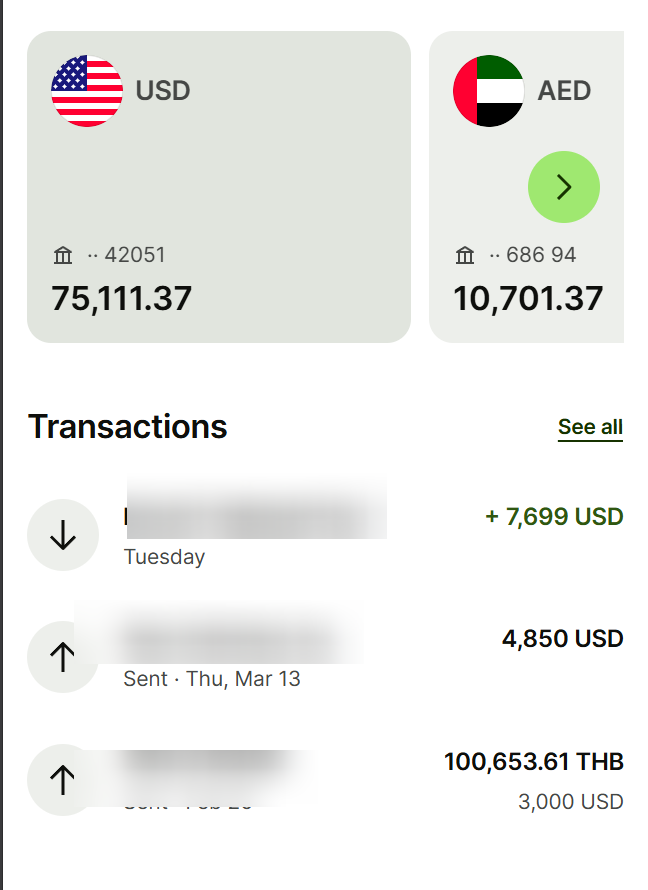
I've made $70K building MVPs using Cursor
(I am a giving a way my playbook)
And I only paid:
- $100 in Cursor tokens
- $17 in @AnthropicAI tokens
- $20/month for Claude/ChatGPT (Often one at a time)
And:
- @boltdotnew for full-stack development
- @lovable for design to MVP development
And they both cost us around $20/month + $50/month
There is no better time than now to be a founder
Comment "MVP" and drop a follow. I’ll DM it to you.
P.S. This will likely blow up, so give me some time to reply.

English
After generating $250K (last 2 months) I built a playbook for @lovable apps—and I’m giving it away.
In just two months, we cracked the code to building apps with AI.
I’ve distilled everything we learned into this single document.
Comment "Build" and drop a follow. I’ll DM it to you.
P.S. This will likely blow up, so give me some time to reply.
English
English

And it will improve rapidly over time
Sawyer Merritt@SawyerMerritt
NEWS: The Department of Government Efficiency (DOGE) has officially launched their website, increasing transparency and better informing people. It includes details of cost savings (launching in a couple days), workforce info, regulations info and more. DOGE website: doge.gov/workforce?orgI…
English
@GavinSBaker @theallinpod bring back Gavin for the next episode
English

2) Conclusions: 1) Lowering the cost to train will increase the ROI on AI. 2) There is no world where this is positive for training capex or the “power” theme in the near term. 3) The biggest risk to the current “AI infrastructure” winners across tech, industrials, utilities and energy is that a distilled version of r1 can be run locally at the edge on a high end work station (someone referenced a Mac Studio Pro). That means that a similar model will run on a superphone in circa 2 years. If inference moves to the edge because it is “good enough,” we are living in a very different world with very different winners - i.e. the biggest PC and smartphone upgrade cycle we have ever seen. Compute has oscillated between centralization and decentralization for a long time. 4) ASI is really, really close and no one really knows what the economic returns to superintelligence will be. If a $100 billion reasoning model trained on 100k plus Blackwells (o5, Gemini 3, Grok 4) is curing cancer and inventing warp drives, then the returns to ASI will be really high and training capex and power consumption will steadily grow; Dyson Spheres will be back to being best explanation for Fermi’s paradox. I hope the returns to ASI are high - would be so awesome. 5) This is all really good for the companies that *use* AI: software, internet, etc. 6) From an economic perspective, this massively increases the value of distribution and *unique* data - YouTube, Facebook, Instagram and X. 7) American labs are likely to stop releasing their leading edge models to prevent the distillation that was so essential to r1, although the cat may already be entirely out of the bag on this front. i.e. r1 may be enough to train r2, etc.
Grok-3 looms large and might significantly impact the above conclusions. This will be the first significant test of scaling laws for pre-training arguably since GPT-4. In the same way that it took several weeks to turn v3 into r1 via RL, it will likely take several weeks to run the RL necessary to improve Grok-3’s reasoning capabilities. The better the base model, the better the reasoning model should be as the three scaling laws are multiplicative - pre-training, RL during post-training and test-time compute during inference (a function of the RL). Grok-3 has already shown it can do tasks beyond o1 - see the Tesseract demo - how far beyond is going to be important. To paraphrase an anonymous Orc from “The Two Towers,” meat might be back on the menu very shortly. Time will tell and “when the facts, I change my mind.”
English
1) DeepSeek r1 is real with important nuances. Most important is the fact that r1 is so much cheaper and more efficient to inference than o1, not from the $6m training figure. r1 costs 93% less to *use* than o1 per each API, can be run locally on a high end work station and does not seem to have hit any rate limits which is wild. Simple math is that every 1b active parameters requires 1 gb of RAM in FP8, so r1 requires 37 gb of RAM. Batching massively lowers costs and more compute increases tokens/second so still advantages to inference in the cloud. Would also note that there are true geopolitical dynamics at play here and I don’t think it is a coincidence that this came out right after “Stargate.” RIP, $500 billion - we hardly even knew you.
Real: 1) It is/was the #1 download in the relevant App Store category. Obviously ahead of ChatGPT; something neither Gemini nor Claude was able to accomplish. 2) It is comparable to o1 from a quality perspective although lags o3. 3) There were real algorithmic breakthroughs that led to it being dramatically more efficient both to train and inference. Training in FP8, MLA and multi-token prediction are significant. 4) It is easy to verify that the r1 training run only cost $6m. While this is literally true, it is also *deeply* misleading. 5) Even their hardware architecture is novel and I will note that they use PCI-Express for scale up.
Nuance: 1) The $6m does not include “costs associated with prior research and ablation experiments on architectures, algorithms and data” per the technical paper. “Other than that Mrs. Lincoln, how was the play?” This means that it is possible to train an r1 quality model with a $6m run *if* a lab has already spent hundreds of millions of dollars on prior research and has access to much larger clusters. Deepseek obviously has way more than 2048 H800s; one of their earlier papers referenced a cluster of 10k A100s. An equivalently smart team can’t just spin up a 2000 GPU cluster and train r1 from scratch with $6m. Roughly 20% of Nvidia’s revenue goes through Singapore. 20% of Nvidia’s GPUs are probably not in Singapore despite their best efforts. 2) There was a lot of distillation - i.e. it is unlikely they could have trained this without unhindered access to GPT-4o and o1. As @altcap pointed out to me yesterday, kinda funny to restrict access to leading edge GPUs and not do anything about China’s ability to distill leading edge American models - obviously defeats the purpose of the export restrictions. Why buy the cow when you can get the milk for free?
English

+1000 attempts later, I finally managed to find the perfect process to achieve realistic results in @Midjourney
Do you want these same results?
Comment "Guide" and I'll send it to you👇🏻
English

always-on-chain.eth 🦇🔊 รีทวีตแล้ว

always-on-chain.eth 🦇🔊 รีทวีตแล้ว
always-on-chain.eth 🦇🔊 รีทวีตแล้ว

The hallmark of expertise is no longer how much you know. It's how well you synthesize.
Information scarcity rewarded knowledge acquisition. Information abundance requires pattern recognition.
It's not enough to collect facts. The future belongs to those who connect dots.
English

I created an 8 page doc on how I find undiscovered TikTok creators for consumer app startups
- 6 sources, each rated /10 (some are VERY underutilized)
- How to access the vetted ones at my BOF
RT & reply “Tiktok” and I’ll DM you the doc
(Must be following so I can DM)
English
use these AI tools to create 100s of TikToks per week to get users on your app
app marketing is now a volume game but no one thinks nearly big enough
literally just onboarding for free to any of these tools puts you in top 10% of app founders
Like + comment "tools" and I'll send you the list (must be following so I can DM)
English
always-on-chain.eth 🦇🔊 รีทวีตแล้ว

Hardware is hard.
That’s why Elon is by far the greatest founder of all time.
Remember — countless startups die just while trying to put stationary beige boxes on desktops. Very smart people get crushed by supply chain disruptions, or China tariffs, or lockdowns, or shipping interruptions, or regulatory delays.
Not Elon. He didn’t just survive financial crisis and coronavirus. He managed to build physical things in America while fighting the state and the laws of nature at the same time.
Somehow he managed to simultaneously build not just a car company but a rocket company. Those don’t just have “moving parts”, they are a moving whole.
The difficulty level here is insane. Hardware is completely different from software. One recall, just one serious bug, can destroy your company. If you are charging $50 for something that costs $40, and you need to recall and replace a million units, you’re usually dead.
So just one of these companies — just Tesla, or just SpaceX — would be an incredible accomplishment for anyone. Even a very intelligent and hardworking person would have to live an incredibly boring, disciplined, focused life to possibly maintain the extremely low error rate needed to profitably ship such complex products.
Not Elon. He did SpaceX and Tesla while having N children by K women. While also cofounding OpenAI and Neuralink and Boring Company. While fighting and defeating countless journalists, politicians, haters, and short sellers. And of course while buying Twitter, posting all the time, and building a following larger than almost any politician.
The better you are, the better you understand how much better Elon is. If you’re good at math you appreciate Ramanujan’s greatness. If you’re good at basketball you respect how amazing Michael Jordan was. Elon is like that, for tech. Everyone in tech understands the sport we’re playing, and he really is the greatest of all time.
English
@JessicaGenetics @omalmike any results on the pillow case you recommended a few months back?
English


You don’t need an expensive lead database
Linkedin is the largest b2b database available to you for free 🤯
I wrote a script to scrape Linkedin search results and download them as csv
❤️ Like + comment ‘send’ and I’ll dm you the doc containing:
- the script
- instructions
GIF
English
always-on-chain.eth 🦇🔊 รีทวีตแล้ว

Billionaire investor Marc Andreessen (@pmarca) on why people should read more books:
"There are thousands of years of history in which lots and lots of very smart people worked very hard and ran all types of experiments on how to create new businesses, invent new technology, new ways to manage etc.
They ran these experiments throughout their entire lives. At some point, somebody put these lessons down in a book.
For very little money and a few hours of time, you can learn from someone’s accumulated experience. There is so much more to learn from the past than we often realize.
You could productively spend your time reading experiences of great people who have come before and you learn every time."

English
always-on-chain.eth 🦇🔊 รีทวีตแล้ว

"The great liability of the engineer compared to men of other professions is that his works are out in the open where all can see them. His acts, step by step, are in hard substance. He cannot bury his mistakes in the grave like the doctors. He cannot argue them into thin air or blame the judge like the lawyers. He cannot, like the architects, cover his failures with trees and vines. He cannot, like the politicians, screen his shortcomings by blaming his opponents and hope the people will forget. The engineer simply cannot deny he did it. If his works do not work, he is damned." - Herbert Hoover, American engineer and politician
English