Naka-pin na Tweet

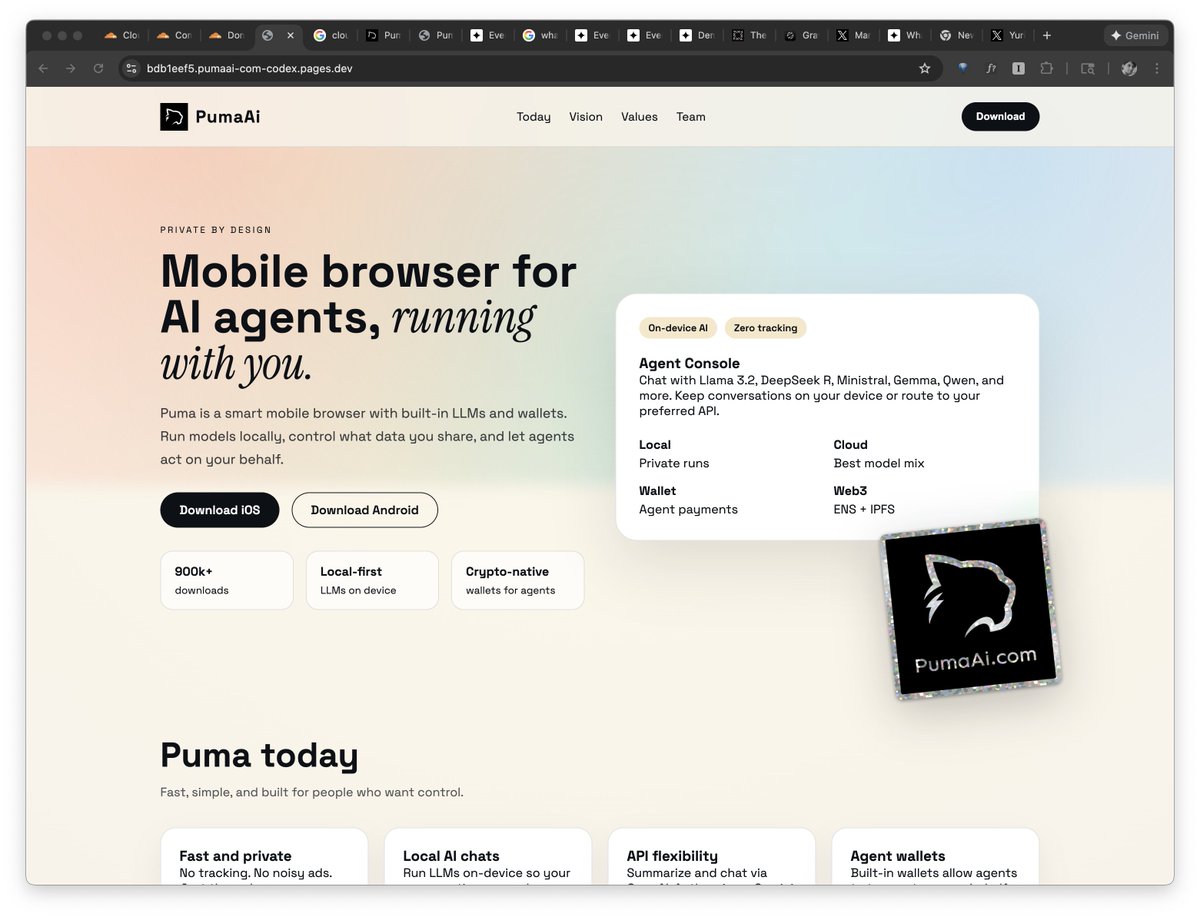
Was looking for a designer to make a new website for @puma_ai and decided to try latest vibecoding options so played around with @antigravity and Codex from @OpenAI.
Guess which one is which:

English
Yuriy Dybskiy
10.3K posts

@html5cat
building https://t.co/GonoWc90V9 (@Puma_ai + Puma Browser + PumaClaw) prev. dev rel at Meta (Parse), @Meteorjs (YC S11), Cloudant (S08) 🇺🇦↠🇯🇵↠🇨🇦↠🇺🇸 🌁🎾📷


To manage growing demand for Claude we're adjusting our 5 hour session limits for free/Pro/Max subs during peak hours. Your weekly limits remain unchanged. During weekdays between 5am–11am PT / 1pm–7pm GMT, you'll move through your 5-hour session limits faster than before.









Crypto’s perfect customer has finally arrived. I spoke with @matthuang, @hosseeb, @jessepollak, @programmer, @_rishinsharma, @joechalom, @OnchainLu and a few other teams and payments experts to unpack how crypto is repositioning for the agentic age, what it will take to win agentic commerce and why this matters beyond payments. forbes.com/sites/ninabamb…

I didn't seen an AI reply yet, I think it works! @nikitabier

GPT-5.4 Pro continues to be the only model of its class. For anything really hard & complex, I throw it into the maw with every bit of context I can think of. More often than not, something very useful comes out. I can't get the same results from Codex or Code or anything else.

is Meta training a new model? one of our sites (puma.tech) is getting hammered by their crawl bots: 100k+ requests in the last 24hr
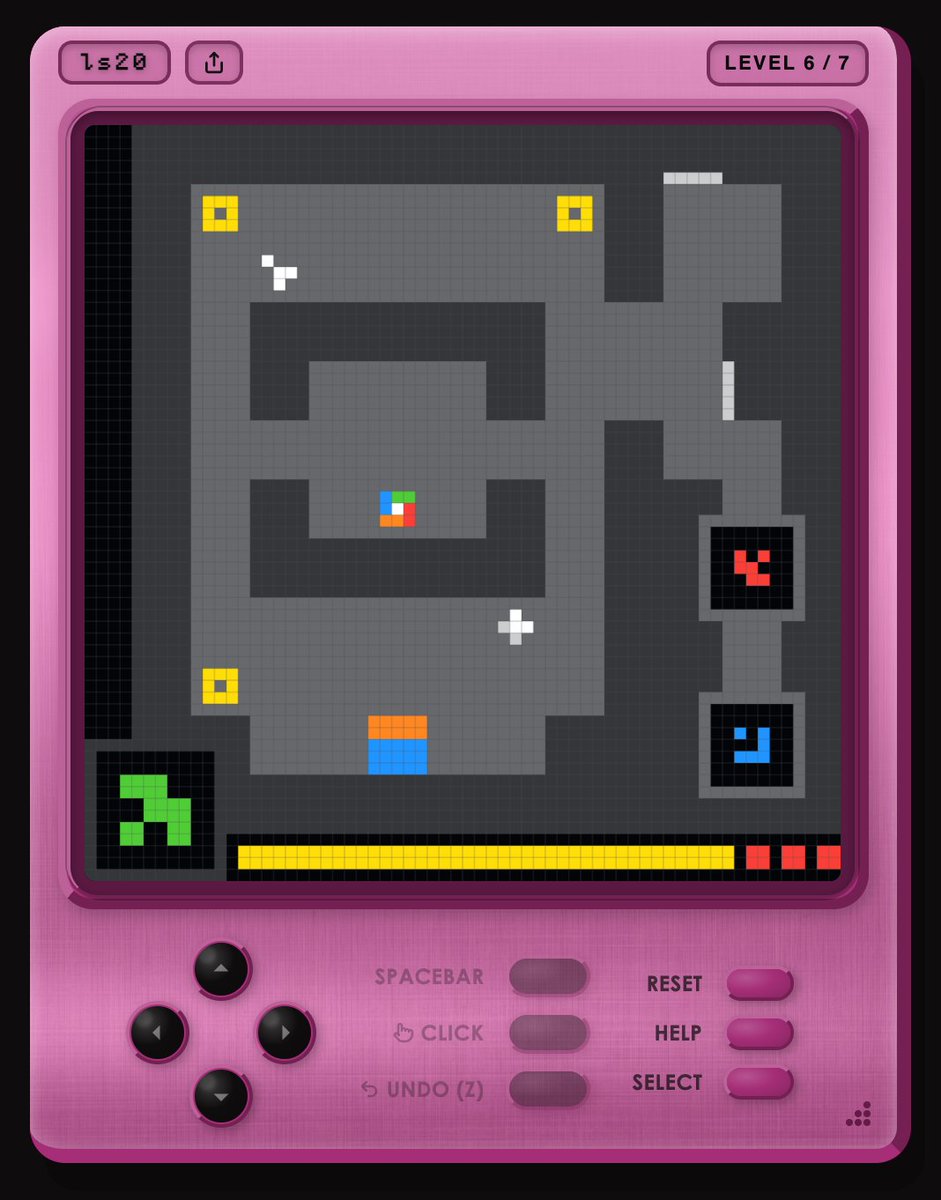
Announcing ARC-AGI-3 The only unsaturated agentic intelligence benchmark in the world Humans score 100%, AI <1% This human-AI gap demonstrates we do not yet have AGI Most benchmarks test what models already know, ARC-AGI-3 tests how they learn


🇯🇵🇰🇷 Japan + Korea Data Residency is coming to Notion. If you need your Enterprise workspace data to stay in-region, you'll be able to choose Tokyo or Seoul — without giving up any of Notion’s collaborative features. So your data stays local and your team stays connected.










