DJ Naydee
2.6K posts


DJ Naydee
@BeatsPlanet
Multi-Gold Music Producer & Beats Planet LLC CEO






We heard you wanted to use Codex rate limit resets on your own time. Starting today, we’re rolling out the ability to save rate limit resets to use later. We’re starting Go, Plus, Pro, and Business users with one free reset:

Exciting news: GLM-5.2 (Max) ranks #2 in Code Arena: Frontend, with +29pt over Claude Opus 4.7 (Thinking) and only behind Fable 5! GLM-5.2 is the best open model vs Kimi-K2.6 and Minimax-M3 by a large margin. - #2 React and #4 HTML sub-leaderboards - Ranks as the top model in nearly all sub categories: Brand & Marketing, Reference-Based Design, Data & Analytics, Consumer Product, Gaming, and Simulations. Congrats @Zai_org for the incredible milestone!








Starting June 15, paid Claude plans can claim a dedicated monthly credit for programmatic usage. The credit covers usage of: - Claude Agent SDK - claude -p - Claude Code GitHub Actions - Third-party apps built on the Agent SDK






I just cancelled my $200 ChatGPT Pro 20x plan. GPT 5.5 is garbage compared to Claude Fable 5. OpenAI shouldn't even release GPT 5.6. They are going to need to release GPT 6 or a new class of model to come anywhere close to Claude Fable 5. I am buying a 4th $200 Claude Max subscription now.



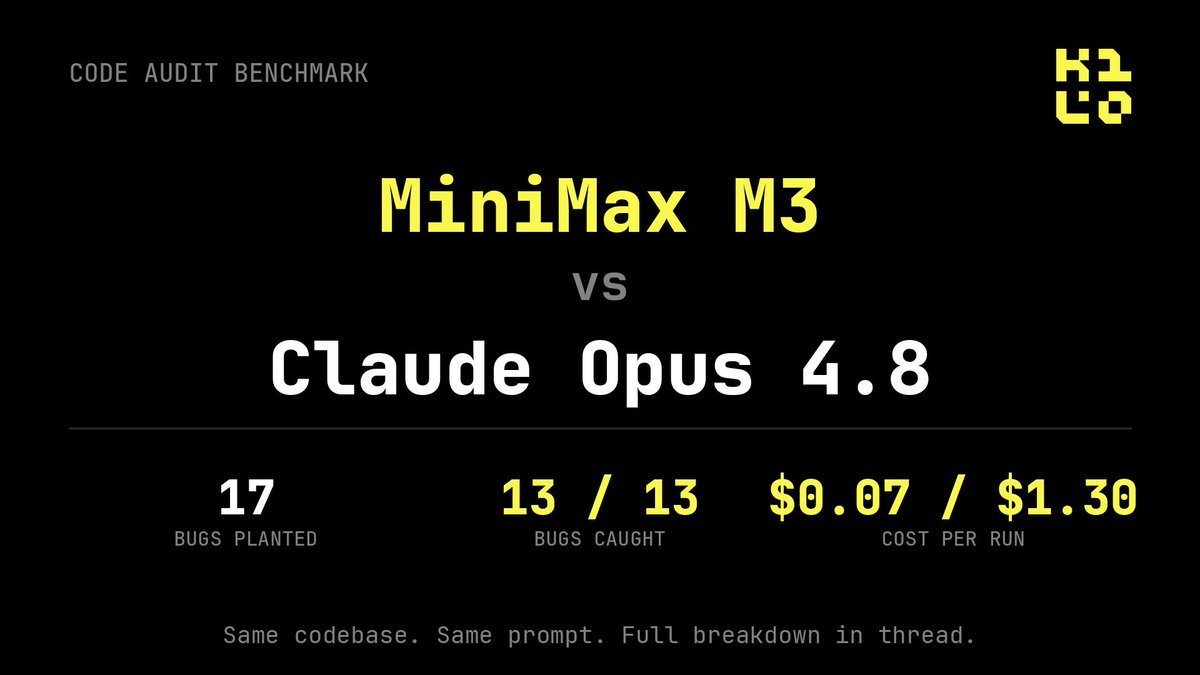




Qwen3.7 Max (20250517) debuts at #4 in Code Arena: Frontend - the top-ranked Chinese lab on the board, surpassing GLM-5.1 and is now on par with Claude Opus 4.6 on agentic web development tasks. Huge congrats to @Alibaba_Qwen on this achievement!


Claude Code 2.1.139 added /goal You set a completion condition and Claude keeps working across turns until it's met Works in interactive, -p, and Remote Control 👏