@ClementDelangue huggingface.co/datasets/nex-a…
We published 70k high quality agent traces:)
English
Shom
665 posts

@ShomLinEd
language model | sequence modeling | education | HCI

Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI



上次面试有一家就很秀,让我回来vibe 一个前后端,单元测试,文档建设,代码架构,UI都有要求,我整整花费了5-6 小时来完成,面试成本太高了。🤡🤡🤡


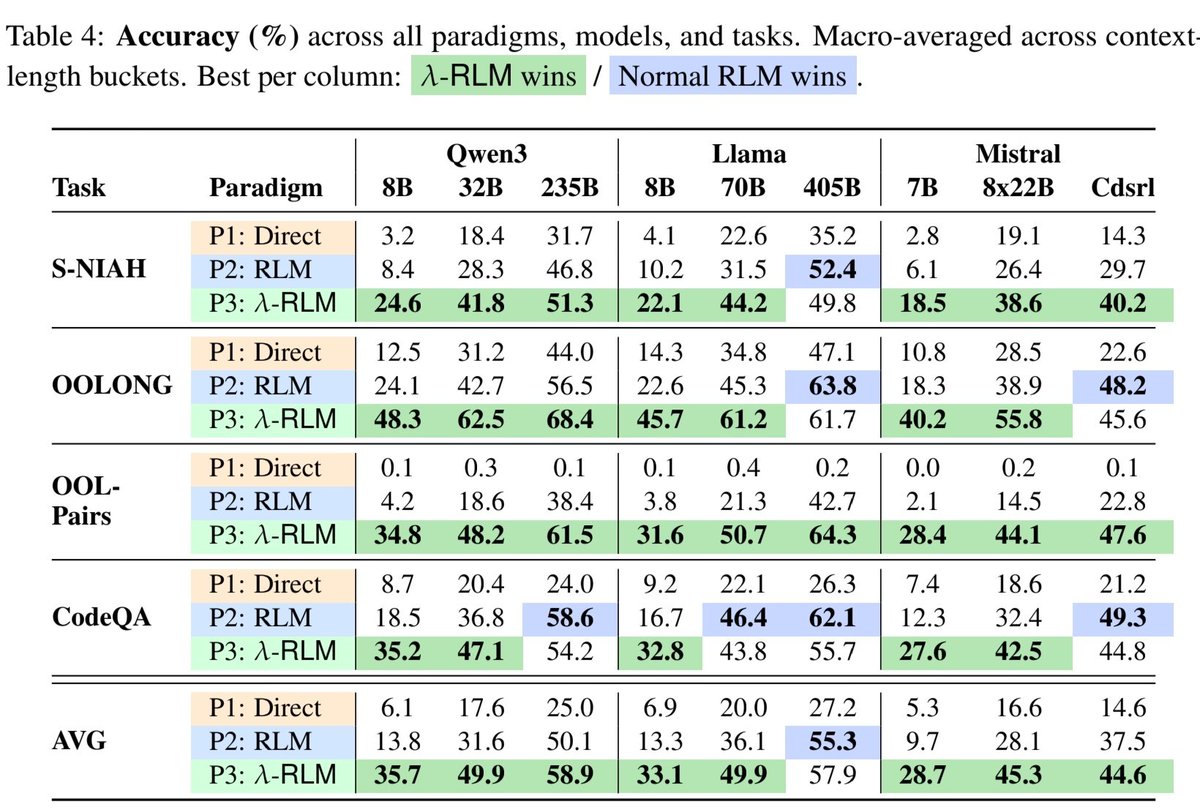

🚨 Shocking: Frontier LLMs score 85-95% on standard coding benchmarks. We gave them equivalent problems in languages they couldn't have memorized. They collapsed to 0-11%. Presenting EsoLang-Bench. Accepted to the Logical Reasoning and ICBINB workshops at ICLR 2026 🧵

me stepping down. bye my beloved qwen.






GPT-5.2 Pro does about 50% of the $ volume on OpenRouter as GPT-5.2. What are people using GPT-5.2 Pro for? Here's the category breakdown: GPT-5.2 Pro is more heavily used for: - Science (6.7% vs 2.8% for Standard) - Finance (2.6% vs 1.3% for Standard) - Legal (1.2% vs 0.5% for Standard) GPT-5.2 Standard is more heavily used for: - Academia (3.4% vs 2.0% for Pro) - Programming (10.7% vs 9.8% for Pro) - Technology (5.6% vs 4.7% for Pro) See openrouter.ai/rankings for more insights

Today, we release LFM2.5, our most capable family of tiny on-device foundation models. It’s built to power reliable on-device agentic applications: higher quality, lower latency, and broader modality support in the ~1B parameter class. > LFM2.5 builds on our LFM2 device-optimized hybrid architecture > Pretraining scaled from 10T → 28T tokens > Expanded reinforcement learning post-training > Higher ceilings for instruction following 🧵