Krishna Kaasyap@krishnakaasyap
From QT - //But if Anthropic found that training above a certain scale, or in a certain way at that scale, produces capabilities that sit far above the prior trendline, then that is an architectural breakthrough.//
I believe this is the case, not just because an architectural and algorithmic breakthrough at this scale cannot be achieved in isolation, but also because, even if it were, it would soon leak via employee turnover, corporate espionage, or many other means.
The moat of a frontier lab lies in enormously scaling an advancement, or simply in scaling a Transformer++ arch. I don't think any of the frontier lab would purely bet on an architectural or algorithmic breakthrough (that could be easily replicated like CoT reasoning/thinking was replicated by almost everyone) for them to be at the frontier!
In addition to this business logic, research from @EpochAIResearch supports the same conclusion.
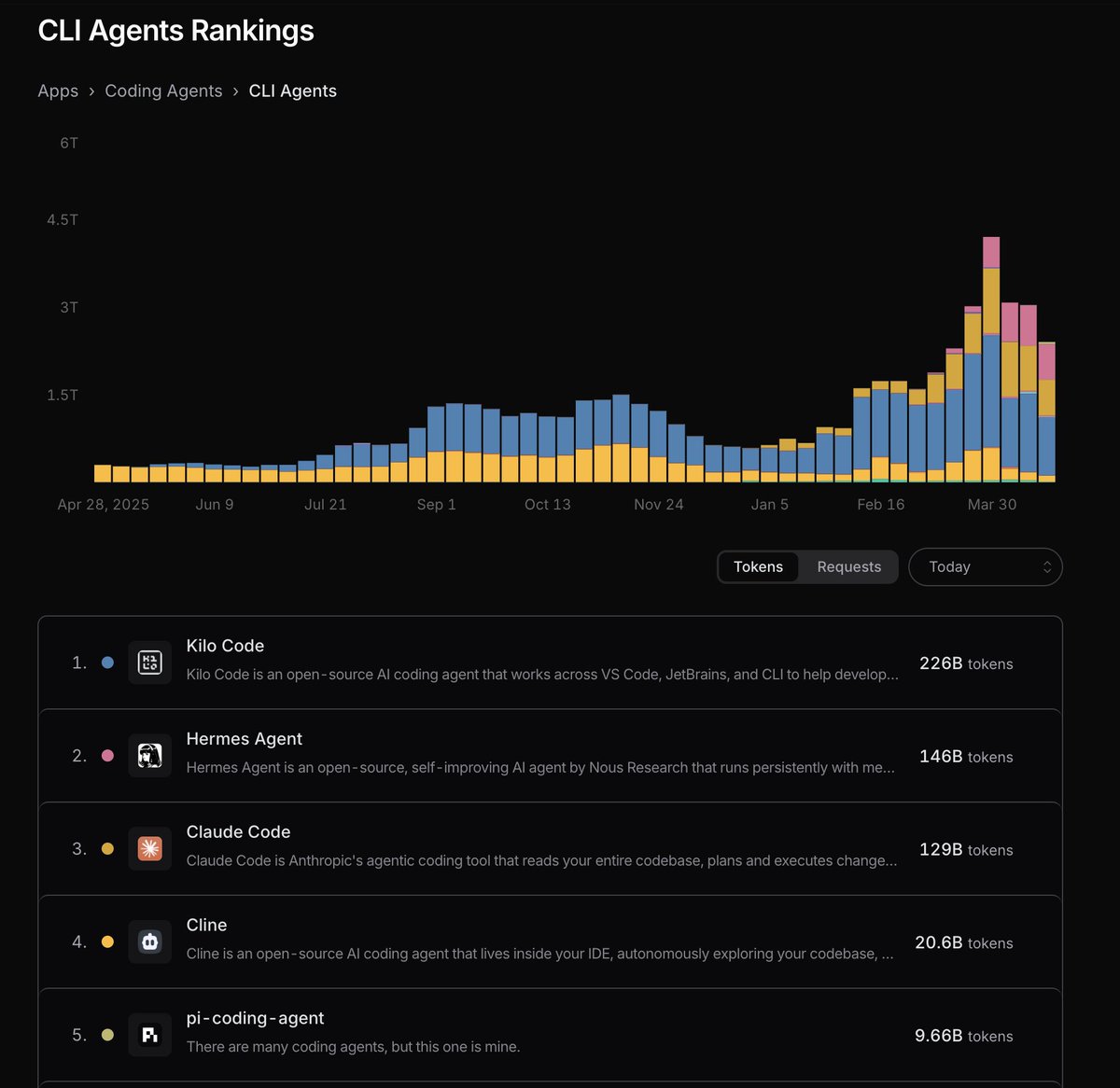
From @ansonwhho's research -
//For example, @MITFutureTech found that shifting from LSTMs (green) to Modern Transformers (purple) has an efficiency gain that depends on the compute scale:
- At 1e15 FLOP, the gain is 6.3×
- At 3e16 FLOP, the gain is 26×
Naively extrapolating to 1e23 FLOP, the gain is 20,000×!//
If Anthropic found that training above a certain scale... produces capabilities that sit far above the prior trendline... they would definitely attempt it, as it can be done by only two other labs in the world. This is especially relevant given that those two labs have their tentacles in everything from adult content slop to search engine & browser wars, thinning their available compute for a final training run of a single model.
Source - epoch.ai/gradient-updat…
Since past final training runs have typically accounted for <30% of total R&D compute, a significant amount of compute remains unused for these runs. It is possible that the compute allocated for final training runs has now been increased substantially.
The largest final training run known to humanity occurred in late 2024 for GPT-4.5, which OpenAI officially released on February 27, 2025. Not a single GB200 NVL72 was available at that time. However, by early 2026, we have access to thousands of GB200 and GB300 NVL72 racks, along with more diversified compute from AMD, Google (TPUs), AWS (Tranium), and many other providers.
All available evidence and reasonable inferences suggest that the observed step-change improvements are likely large primarily because Ant scaled final training run compute significantly, rather than due to a multitude of new innovations.
Source - epoch.ai/gradient-updat…
Total @EpochAIResearch victory - @datagenproc @cherylwoooo @Jsevillamol and the team!