
🌴Marc Averitt🌴
24.2K posts

🌴Marc Averitt🌴
@OCVC
VC at Okapi Venture Capital✌️Hit me at: [email protected]
Orange County, CA Tham gia Mayıs 2007
946 Đang theo dõi2.7K Người theo dõi

hey California: why are we 1 of only 4 states that doesn't honor #QSBS tax exemptions?
(PA, MS, AL are the others... note NY just decided to keep it, and NJ also recently agreed to honor QSBS)

Tech:NYC@TechNYC
Big news for NY startups! QSBS is here to stay. From @politico: the idea now “seems to be moot” following strong, coordinated engagement from across the tech community—including a @TechNYC letter with 1,600+ founders, early employees, and investors. This is a clear example of what’s possible when the ecosystem shows up together. We’re grateful to everyone who spoke out and helped ensure policymakers understood what was at stake. New York remains the best place to build. 🗽
English


I've joined @usv
Rebecca Kaden@rebeccakaden
Over the last few months we’ve rebuilt how we work @usv entirely. We’ve always loved being small in size (team; fund, relatively) but with tentacles that reach broadly. Now, that’s easier than ever with an agentic workforce. The agents are on our emails and messages, pushing back, suggesting new ideas, finding opportunities. It’s a work in progress—so, as we always do, we like to publish it half-baked in the hopes that we’ll learn what we’re missing and where we can push further. If you’ve built an agentic workforce to change how your partnership operates, we want to share ideas.
English
🌴Marc Averitt🌴 đã retweet

So proud to see F.03 make history as the first humanoid robot in the White House 🤖 🇺🇸
English
🌴Marc Averitt🌴 đã retweet

This is potentially the biggest news of the year
Google just released TurboQuant. An algorithm that makes LLM’s smaller and faster, without losing quality
Meaning that 16gb Mac Mini now can run INCREDIBLE AI models. Completely locally, free, and secure
This also means:
• Much larger context windows possible with way less slowdown and degradation
• You’ll be able to run high quality AI on your phone
• Speed and quality up. Prices down.
The people who made fun of you for buying a Mac Mini now have major egg on their face.
This pushes all of AI forward in a such a MASSIVE way
It can’t be stated enough: props to Google for releasing this for all. They could have gatekept it for themselves like I imagine a lot of other big AI labs would have. They didn’t. They decided to advance humanity.
2026 is going to be the biggest year in human history.
Google Research@GoogleResearch
Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
English
@GrantM Early cloud transition was based on low cost Linux / x86 configs so there is precedent here…
English

The cost of creating software is trending to zero, what happens when that comes to operating software?
Many of the smartest engineers I know are shifting to low cost providers (Hetzner) and giving agents root. Still early days but this is coming soon.
Open source and self-hosted solutions on commodity hardware seems like a trend.
English
🌴Marc Averitt🌴 đã retweet

41% of all code shipped in 2025 was AI-generated or AI-assisted. The defect rate on that code is 1.7x higher than human-written code. And a randomized controlled trial found that experienced developers using AI tools were actually 19% slower than developers working without them.
Devs have always written slop. The entire software industry is built on infrastructure designed to catch slop before it ships. Code review, linting, type checking, CI/CD pipelines, staging environments. All of it assumes one thing: the person who wrote the code can walk you through what it does when the reviewer asks.
That assumption held for 50 years. It broke in about 18 months.
When 41% of your codebase was generated by a machine and approved by a human who skimmed it because the tests passed, the review process becomes theater. The reviewer is checking code neither of them wrote. The linter catches syntax, not intent. The tests verify behavior, not understanding.
The old slop had an owner. Someone could explain why temp_fix_v3_FINAL existed, what edge case it handled, and what would break if you removed it. The new slop has an approver. Different relationship entirely.
Arvid’s right that devs wrote bad code before AI. The part he’s missing: the entire quality infrastructure of software engineering was designed around a world where the author and the debugger were the same person. That world ended last year and nothing has replaced it yet.
Arvid Kahl@arvidkahl
Devs are acting like they didn’t write slop code before AI.
English
🌴Marc Averitt🌴 đã retweet


it's about time... just hope it's not too late to start the process of catching up. We need something like the Telecom Deregulation Act of 1996 to incentivize the private sector to take on the challenge of remaking our grid; that will speed things up considerably!
U.S. Department of Energy@ENERGY
English

What happened to you Texas? At the Austin airport Salt Lick and have heard multiple people ask for vegetarian options, gluten free options, no BBQ sauce, and various other un-American things.
English

The Fortune 500 thinks about AI through the lens of efficiency and effectiveness: What they should be thinking about is epistemology.
English
🌴Marc Averitt🌴 đã retweet

🚨 BREAKING: Researchers at UW Allen School and Stanford just ran the largest study ever on AI creative diversity.
70+ AI models were given the same open-ended questions. They all gave the same answers.
They asked over 70 different LLMs the exact same open-ended questions.
"Write a poem about time." "Suggest startup ideas." "Give me life advice."
Questions where there is no single right answer. Questions where 10 different humans would give you 10 completely different responses.
Instead, 70+ models from every major AI company converged on almost identical outputs. Different architectures. Different training data. Different companies. Same ideas. Same structures. Same metaphors.
They named this phenomenon the "Artificial Hivemind." And the paper won the NeurIPS 2025 Best Paper Award, which is the highest recognition in AI research, handed to a small number of papers out of thousands of submissions.
This is not a blog post or a hot take. This is award-winning, peer-reviewed science confirming something massive is broken.
The team built a dataset called Infinity-Chat with 26,000 real-world, open-ended queries and over 31,000 human preference annotations. Not toy benchmarks. Not math problems.
Real questions people actually ask chatbots every single day, organized into 6 categories and 17 subcategories covering creative writing, brainstorming, speculative scenarios, and more.
They ran all of these across 70+ open and closed-source models and measured the diversity of what came back. Two findings hit hard.
First, intra-model repetition. Ask the same model the same open-ended question five times and you get almost the same answer five times.
The "creativity" you think you're getting is the same output wearing a slightly different outfit. You ask ChatGPT, Claude, or Gemini to write you a poem about time and you keep getting the same river metaphor, the same hourglass imagery, the same reflection on mortality.
Over and over. The model isn't thinking. It's defaulting to whatever scored highest during alignment training.
Second, and this is the one that should really alarm you, inter-model homogeneity. Ask GPT, Claude, Gemini, DeepSeek, Qwen, Llama, and dozens of other models the same creative question, and they all converge on strikingly similar responses.
These are models built by completely different companies with different architectures and different training pipelines.
They should be producing wildly different outputs. They're not. 70+ models all thinking inside the same invisible box, producing the same safe, consensus-approved content that blends together into one indistinguishable voice.
So why is this happening? The researchers point directly at RLHF and current alignment techniques. The process we use to make AI "helpful and harmless" is also making it generic and boring.
When every model gets trained to optimize for human preference scores, and those preference datasets converge on a narrow definition of what "good" looks like, every model learns to produce the same safe, agreeable output. The weird answers get penalized.
The original takes get shaved off. The genuinely creative responses get killed during training because they didn't match what the average annotator rated highly. And it gets even worse.
The study found that reward models and LLM-as-judge systems are actively miscalibrated when evaluating diverse outputs. When a response is genuinely different from the mainstream but still high quality, these automated systems rate it LOWER. The very tools we built to evaluate AI quality are punishing originality and rewarding sameness.
Think about what this means if you use AI for brainstorming, content creation, business strategy, or literally any task where you need multiple perspectives. You're getting the illusion of diversity, not the real thing.
You ask for 10 startup ideas and you get 10 variations of the same 3 ideas the model learned were "safe" during training. You ask for creative writing and you get the same therapeutic, perfectly balanced, utterly forgettable tone that every other model gives.
The researchers flagged direct implications for AI in science, medicine, education, and decision support, all domains where diverse reasoning is not a nice-to-have but a requirement.
Correlated errors across models means if one AI gets something wrong, they might ALL get it wrong the same way. Shared blind spots at massive scale.
And the long-term risk is even scarier. If billions of people interact with AI systems that all think identically, and those interactions shape how people write, brainstorm, and make decisions every day, we risk a slow, invisible homogenization of human thought itself. Not because AI replaced creativity.
Because it quietly narrowed what we were exposed to until we all started thinking the same way too.
Here's what you can actually do about it right now:
→ Stop accepting first-draft AI output as creative or diverse. If you need 10 ideas, generate 30 and throw away the obvious ones
→ Use temperature and sampling parameters aggressively to push models out of their comfort zone
→ Cross-reference multiple models AND multiple prompting strategies, because same model with different prompts often beats different models with the same prompt
→ Add constraints that force novelty like "give me ideas that a traditional investor would hate" instead of "give me creative ideas"
→ Use structured prompting techniques like Verbalized Sampling to force the model to explore low-probability outputs instead of defaulting to consensus
→ Layer your own taste and judgment on top of everything AI gives you. The model gets you raw material. Your weirdness and experience make it original
This paper puts hard data behind something a lot of us have been feeling for a while. AI is getting more capable and more homogeneous at the same time.
The models are smarter, but they're all smart in the exact same way. The Artificial Hivemind is not a bug in one model. It's a systemic feature of how the entire industry builds, aligns, and evaluates language models right now.
The fix requires rethinking alignment itself, moving toward what the researchers call "pluralistic alignment" where models get rewarded for producing diverse distributions of valid answers instead of collapsing to a single consensus mode.
Until that happens, your best defense is awareness and better prompting.

English
🌴Marc Averitt🌴 đã retweet

We're building Europe's sovereign security stack with Schwarz Gruppe - one of the most impressive businesses I have seen. Their culture aligns with CrowdStrike's. Constant innovation, creative problem solving, and winning.
Big thanks to @rolfschumann and Christian Müller for all their help. Of course this wouldn't be possible without Gerd Chrzanowski's vision and leadership. Thank you!
CrowdStrike@CrowdStrike
Security without borders. Data that stays home. CrowdStrike and Schwarz Digits have partnered to deliver the AI-native CrowdStrike Falcon platform on STACKIT’s sovereign cloud. 🦅 Top-tier protection: Stop breaches with AI-native speed. 🛡️ Total sovereignty: Fully EU-operated and aligned with NIS2 & CRA. ⚡ AI at scale: Grow workloads without compromising data residency. The future of European cyber defense starts now. Read more: crwdstr.ke/6018h7cxq
English
CrowdStrike just delivered a record FY26, capped by a blockbuster Q4.
🔒 $5.25B ending ARR - the ONLY pure-play software cyber company to cross $5B
📈 $331M net new ARR in Q4, all-time record, up 47% YoY.
💰 $1.24B FY26 free cash flow. All-time record.
⚡ $1.05B non-GAAP operating income. First year above $1B.
AI is accelerating the threat. It's also accelerating our opportunity.
If you want to build AI, you need GPUs. If you want to deploy AI, you need @CrowdStrike .
To our customers, partners, and team: thank you.
Full earnings release and FY27 outlook at ir.crowdstrike.com.
🦅 $CRWD
#CrowdStrike #Cybersecurity #AI #StoppingBreaches
English

The whole “Death of SaaS” thing and the “American Shenzhen” vibe have gone from niche Twitter debates to very real momentum over the last few months.
It’s pretty obvious LA is shaping up to be one of the most important startup hubs in the world.
A couple years ago, I wondered if it was a mistake not to live in SF full-time. I grew up in the Bay Area and I’m still up there all the time, so it felt like the center of gravity.
Now it feels flipped. Not spending real time in Los Angeles might actually be the bigger mistake.
English

We backed @XTrace_ai (xtrace.ai) because context is the most valuable asset in the enterprise AI. Go check it out.
Every major platform shift creates a new login layer.
Email gave us "Sign in with Google." Social gave us "Connect with Facebook."
AI will give us "Connect with your memory."
Right now, your context is a prisoner of the platform. It’s locked inside ChatGPT, Claude, or Gemini. Every time you switch AI vendors, your institutional intelligence resets to zero. That isn't just inefficient, it's a loss of sovereignty.
@XTrace_ai is building the private, portable memory infrastructure that puts organizations back in control. By owning your context, you unlock doors that didn't exist before:
• Vendor Independence: Move your "brain" from one LLM to another instantly.
• Selective Intelligence: Share specific knowledge with specific agents without exposing the whole vault.
• Infinite Persistence: Workflows that span months stay as sharp as day one.
English
@LDEakman @MarriottBonvoy Pretty sure there’s a travel hack out there that lets you override the room thermostat and get it to 60.
English

Classic hotel room fail. Thermostat set on 70. Room at 78. Good luck sleeping.
@MarriottBonvoy
English
🌴Marc Averitt🌴 đã retweet

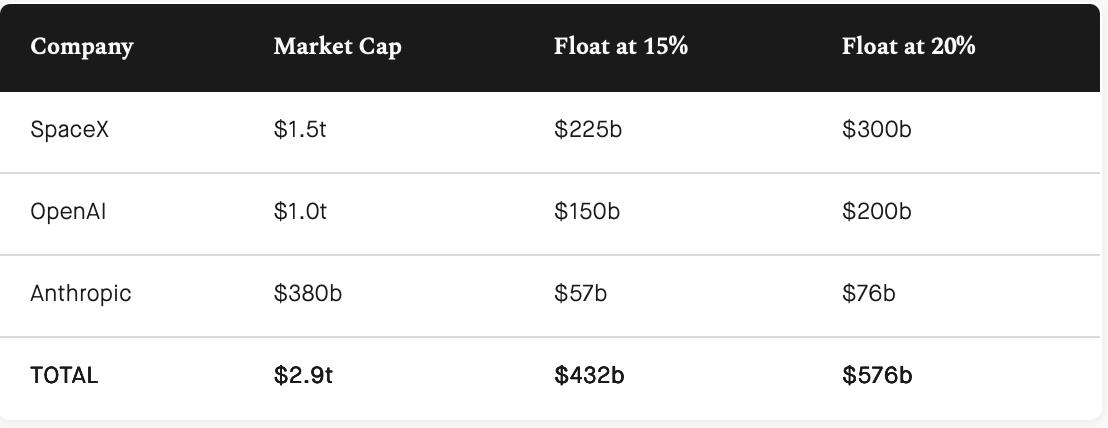
We’re about to witness three of the largest IPOs in history. SpaceX is targeting $1.5t. OpenAI aims for $1t. Anthropic is valued at $380b. Combined, $2.9t in market cap.
The scale is unprecedented. But the real problem isn’t the market cap. It’s the float.
Typical IPOs offer 15-25% of their shares to public markets. This creates enough liquidity for price discovery while allowing founders & early investors to maintain control. Facebook floated 15%. Google floated 19%. Alibaba floated 15%.
At a 15% float, here’s what these three IPOs would require :
English



