
Harbor Framework
54 posts

Harbor Framework
@harborframework
San Francisco, CA Tham gia Ocak 2026
4 Đang theo dõi870 Người theo dõi


We've been using Harbor skills to build tasks and integrate new benchmarks way faster.
Now you can too:

Thariq@trq212
Using Skills well is a skill issue. I didn't quite realize how much until I wrote this, the best can completely transform how your team works.
English
Harbor Framework đã retweet

Such a cool benchmark using @harborframework !
max@maxbittker
RuneBench is out: measuring long horizon goal optimization across 14 AI coding models inside Runescape
English
English

Harbor (@harborframework) is great and it is amazing that the community is moving towards open standards! One ask: The lack of multi-user support is super limiting; it is super inconvenient that running tests requires uploads of often massive testing folders
English
Harbor Framework đã retweet

@harborframework Is 1000% going to be the agent standard. Not just for coding agents
English
Harbor Framework đã retweet

kind of a big deal but actual legend @ZitongYang0 has integrated @tinkerapi with @harborframework, so you can use Harbor on Tinker w ~no code change now 🤠🧡
Tinker@tinkerapi
New in the cookbook: Harbor RL trains models on real software engineering tasks inside sandboxed containers. The agent gets a bash shell, an instruction, and a test suite. If the tests pass, it gets the reward. github.com/thinking-machi…
English
Harbor Framework đã retweet

🚨 New: Integrating Harbor (@harborframework) for end-to-end Computer-Use evaluation(for Windows and Linux) at scale with @thinkymachines' Tinker, OSWorld, @daytonaio, and bare-metal servers.
We just added support for Computer Use, @tinkerapi, and OSWorld to Harbor - a framework for evaluating agents and generating RL training data by running large-scale rollouts across parallel sandboxed environments and collecting trajectories for SFT and RL.
Repo and blogpost below 👇
English
Harbor Framework đã retweet

Alex Shaw (@alexgshaw) is speaking at Compute Conference.
Co-creator of @terminalbench, the default coding agent benchmark, adopted by Anthropic and OpenAI. Built @harborframework for sandboxed agent evals.
Join us March 8–9 at Chase Center, SF. Tickets: go.daytona.io/9DmGPuN

English
Harbor Framework đã retweet

Excited to kick off this year’s Systems Reading Group series with @harborframework and @terminalbench!
Top frontier labs, data vendors, and AI cos are moving to Harbor for their RL infra and evals. Come by to learn why, and dive into key components of their architecture with creators @alexgshaw & @ryanmart3n!
Sign up below for the event on 3/10 👉
luma.com/wkdfbw17
English
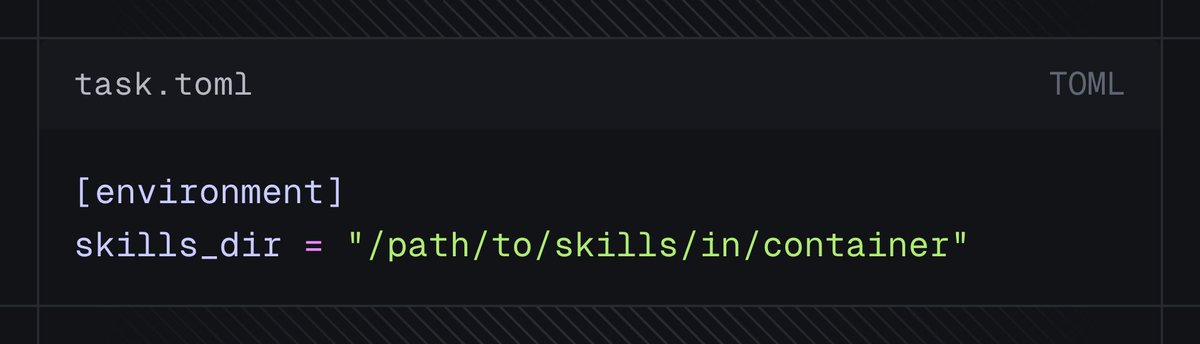
Benchmarking skills has been a common Harbor use case (e.g. skillsbench.ai). Harbor now has first-class support for skills.
Agents receive skills_dir in their __init__ method and can choose to register the skills in their setup or run methods. Typically, this means copying the skills directory to the expected location, e.g. ~/.claude/skills.
English
Harbor Framework đã retweet
All agents are becoming terminal/coding agents
"More agents are adopting the coding agent architecture... Even agents that aren't marketed as 'coding agents' use code generation as their most flexible tool." -- Vercel
vercel.com/blog/security-…
Harbor Framework@harborframework
“harbor is the correct way to express tasksets for terminal agents” - @willccbb
English
“my team at Cog has made it a top priority to migrate all evals to Harbor” - @swyx
swyx@swyx
if you’re not in the RLFT industry you do not understand how quickly @harborframework has come to completely dominate the landscape right now for RL infra and evals. it is standing room only at this @modal x @willccbb meetup where Harbor is basically required knowledge. my team at Cog has made it a top priority to migrate all evals to Harbor as well. it’s kinda unreal given that it was basically launched by a few guys in a discord needing something better for TerminalBench 2 (we posted the launch on @latentspacepod youtube look it up). not at all surprised this one got the @andykonwinski blessing and you should expect an entire mini industry of Harbor based evals and benchmarks and infra startups this year.
English
“harbor is the correct way to express tasksets for terminal agents” - @willccbb
will brown@willccbb
@markatgradient @swyx @harborframework @modal verifiers is focused on being a domain-agnostic layer for converting any eval into a trainable RL environment, including all of the token-level plumbing harbor is the correct way to express tasksets for terminal agents diff layers of the stack
English
Harbor Framework đã retweet
Nice to see tools used by millions of people being improved with Harbor & Terminal-Bench.
Cline@cline
A potential partner asked for our benchmark numbers. At the time, benchmarks had us behind other agents. We spent a weekend fixing that: ran Cline against Terminal Bench's 89 real-world tasks, diagnosed every failure, and shipped fixes. 47% → 57%.
English
We are excited to be part of Laude slingshots! Thank you for your support!
Laude Institute@LaudeInstitute
. @harborframework /@alexgshaw @ryanmart3n @lschmidt3 @andykonwinski (@LaudeInstitute) / Agent evaluation needs shared infrastructure. Harbor standardizes benchmarks through one interface: repeatable runs, standardized traces, production-grade practice. Born from @terminalbench (Batch 1).
English
Harbor Framework đã retweet
English