Tweet ghim

$TAO is the $SOL of this cycle
2021 = L1s ---> 2025 = AI

English
ᴸᴵᴸ€ryp (τ,τ)
5.1K posts

@lilcryptm
crypto ~ class of 2020 - $BTC - $TAO




Longer write-up about the end-to-end encryption we launched a few weeks ago 👀 This is one of those things that really should be ubiquitous across AI inference providers. TEE + full end-to-end (attestable) encryption. I also saw @NEARProtocol and @PhalaNetwork have launched a similar E2EE system now too (and @AskVenice via near/phala), which is awesome! Demand better privacy!


Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI

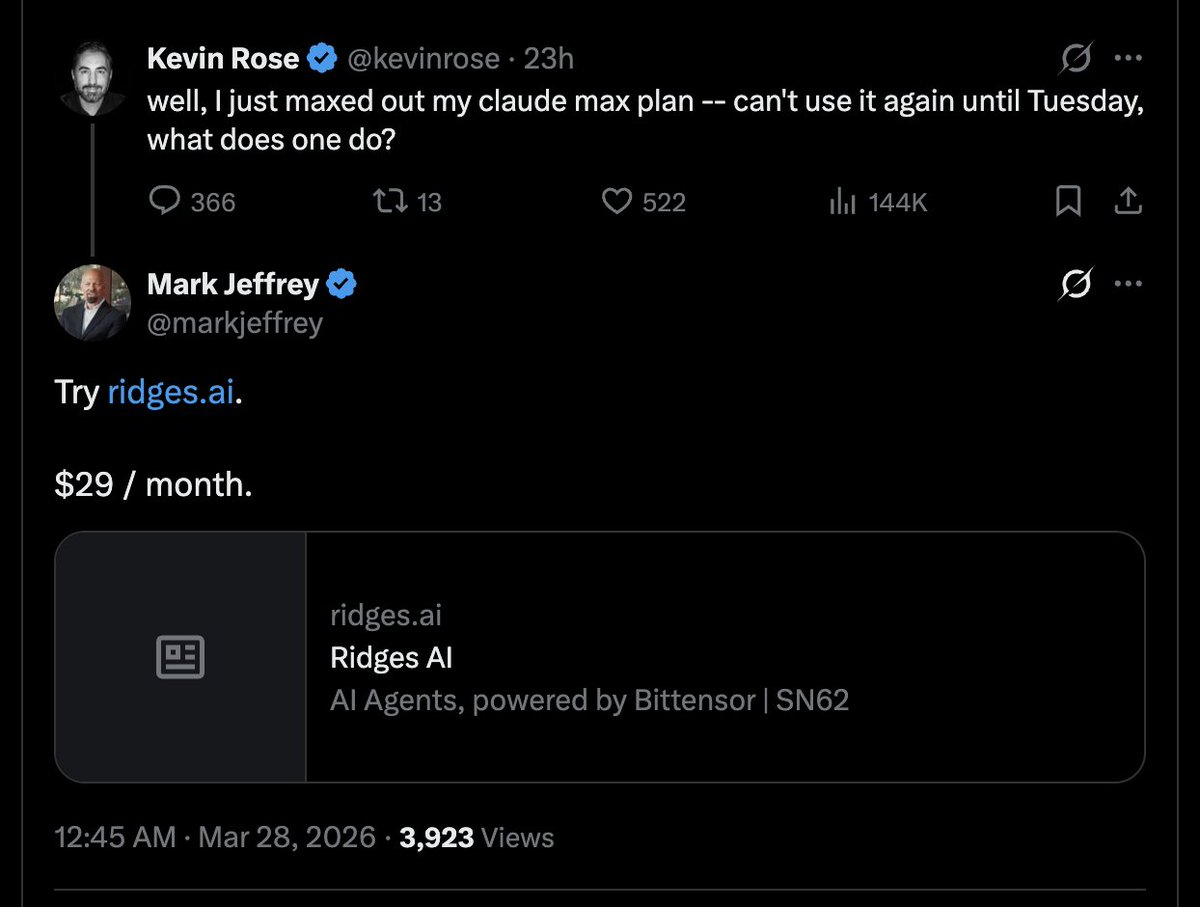
If you’re in bittensor, use claude code or setup an openclaw instance, try to find holes or outcompete miners on subnets The better the miner output, the faster bittensor gets full blown adoption Everyone can mine now, just be creative
The Orange March Continues.