hkey
332 posts



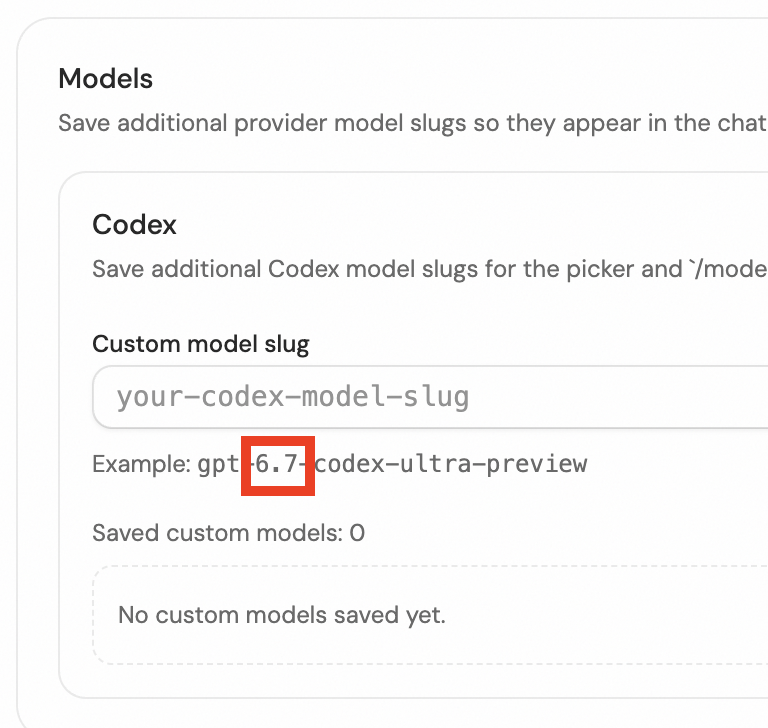


The $1 Billion Kalshi Perfect Bracket Challenge $1 Billion for a perfect bracket $1 Million guaranteed to the top scoring bracket $1 Million to charity and scholarships See the full rules and submit your bracket: kalshi.com/billion-dollar… No purchase or deposit required. SIG Parametrics, LLC, a member of the Susquehanna International Group of Companies, is financially backing this promotion.
if you have unused weekly limits the best way to burn them is just spamming fan-out deep research in cc/codex: - 0 review cycles needed - context-dense files you reuse forever - no slop generated (it's source material, not final output) - feeds into content, product, marketing or competitor intel later ran 22 parallel research agents to burn through ~15% of weekly usage in 20 minutes. tokens very well spent.


















pewdiepie just trained his own llm, and it beats gpt-4o on coding benchmarks. an apocalyptic, civilization-ending catastrophe of laughably, cosmically disproportionate magnitude for the entire ml research job category