Physical AI is accelerating, isn't it? It's almost like something big is happening 😉 The age of demos is coming to an end, and the age of real, useful, high-value work is upon us. Exciting times!!
English
Adrien Gaidon
3.2K posts

@adnothing
Building something new in Robotics and Physical AI! Adjunct Prof of CS at @Stanford, ex partner at @CalibrateVC & head of ML at @ToyotaResearch



Good luck @MatthewKowal9 on your PhD defence tomorrow! It’s part examination, part celebration, enjoy the moment 💪


Noticing myself adopting a certain rhythm in AI-assisted coding (i.e. code I actually and professionally care about, contrast to vibe code). 1. Stuff everything relevant into context (this can take a while in big projects. If the project is small enough just stuff everything e.g. `files-to-prompt . -e ts -e tsx -e css -e md --cxml --ignore node_modules -o prompt.xml`) 2. Describe the next single, concrete incremental change we're trying to implement. Don't ask for code, ask for a few high-level approaches, pros/cons. There's almost always a few ways to do thing and the LLM's judgement is not always great. Optionally make concrete. 3. Pick one approach, ask for first draft code. 4. Review / learning phase: (Manually...) pull up all the API docs in a side browser of functions I haven't called before or I am less familiar with, ask for explanations, clarifications, changes, wind back and try a different approach. 6. Test. 7. Git commit. Ask for suggestions on what we could implement next. Repeat. Something like this feels more along the lines of the inner loop of AI-assisted development. The emphasis is on keeping a very tight leash on this new over-eager junior intern savant with encyclopedic knowledge of software, but who also bullshits you all the time, has an over-abundance of courage and shows little to no taste for good code. And emphasis on being slow, defensive, careful, paranoid, and on always taking the inline learning opportunity, not delegating. Many of these stages are clunky and manual and aren't made explicit or super well supported yet in existing tools. We're still very early and so much can still be done on the UI/UX of AI assisted coding.
AI PROMPTING → AI VERIFYING AI prompting scales, because prompting is just typing. But AI verifying doesn’t scale, because verifying AI output involves much more than just typing. Sometimes you can verify by eye, which is why AI is great for frontend, images, and video. But for anything subtle, you need to read the code or text deeply — and that means knowing the topic well enough to correct the AI. Researchers are well aware of this, which is why there’s so much work on evals and hallucination. However, the concept of verification as the bottleneck for AI users is under-discussed. Yes, you can try formal verification, or critic models where one AI checks another, or other techniques. But to even be aware of the issue as a first class problem is half the battle. For users: AI verifying is as important as AI prompting.




🚀 Details of the #CVPR2025 award candidate papers are out. 14 of 2967 accepted papers made the list, spanning 3D vision, embodied AI, VLMs/MLLMs, learning systems, and scene understanding. 3D vision leads with the most entries. I collected the TL;DR, paper, and project links👇
Thanks for the authors’ feedback, we’re always looking to improve the platform! If a model does well on LMArena, it means that our community likes it! Yes, pre-release testing helps model providers identify which variant our community likes best. But this doesn’t mean the leaderboard is biased; see the clarification below. The leaderboard reflects millions of fresh, real human preferences. One might disagree with human preferences—they’re subjective—but that’s exactly why they matter. Understanding subjective preference is essential to evaluating real-world performance, as these models are used by people. That’s why we’re working on statistical methods—like style and sentiment control—to decompose human preference into its constituent parts. We are also strengthening our user base to include more diversity. And if pre-release testing and data helps models optimize for millions of people’s preferences, that’s a positive thing! Pre-release model testing is also a huge part of why people come to LMArena. Our community loves being the first to test the best and newest AIs! That’s why we welcome all model providers to submit their AIs to battle and win the preferences of our community. Within our capacity, we are trying to satisfy all requests for testing we get from model providers. We are committed to fair, community-driven evaluations, and invite all model providers to submit more models for testing and to improve their performance on human preference. If a model provider chooses to submit more tests than another model provider, this does not mean the second model provider is treated unfairly. Every model provider makes different choices about how to use and value human preferences. We helped Meta with pre-release testing for Llama 4, like we have helped many other model providers in the past. We support open-source development. Our own platform and analysis tools are open source, and we have released millions of open conversations as well. This benefits the whole community. We agree with a few of this writeup’s suggestions (e.g. implementing an active sampling algorithm) and are happy to consider more. Unfortunately, there are also a number of factual errors and misleading statements in this writeup. - The simulation of LMArena, e.g. in Figures 7/8, is flawed. It’s like saying: “The average 3-point percentage in the NBA is 35%. Steph Curry has the highest 3-point percentage in the NBA at 42%. This is unfair, because he comes from the distribution of NBA players, and they all have the same latent mean.” - We designed our policy to prevent model providers from just reporting the highest score they received during testing. We only publish the score for the model they release publicly. - Many of the numbers in the paper do not reflect reality: see the blog below (released a few days ago) for the actual statistics on the number of models tested from different providers. See also in thread our longstanding policy on pre-release testing. We have been doing so transparently with the support of our community for over a year.




The data so far on AI-as-a-tutor shows just letting students use AI chatbots often undermines learning by just giving answers. But AIs properly prompted to act like tutors, especially with instructor support, seem to be able to boost learning a lot through customized instruction

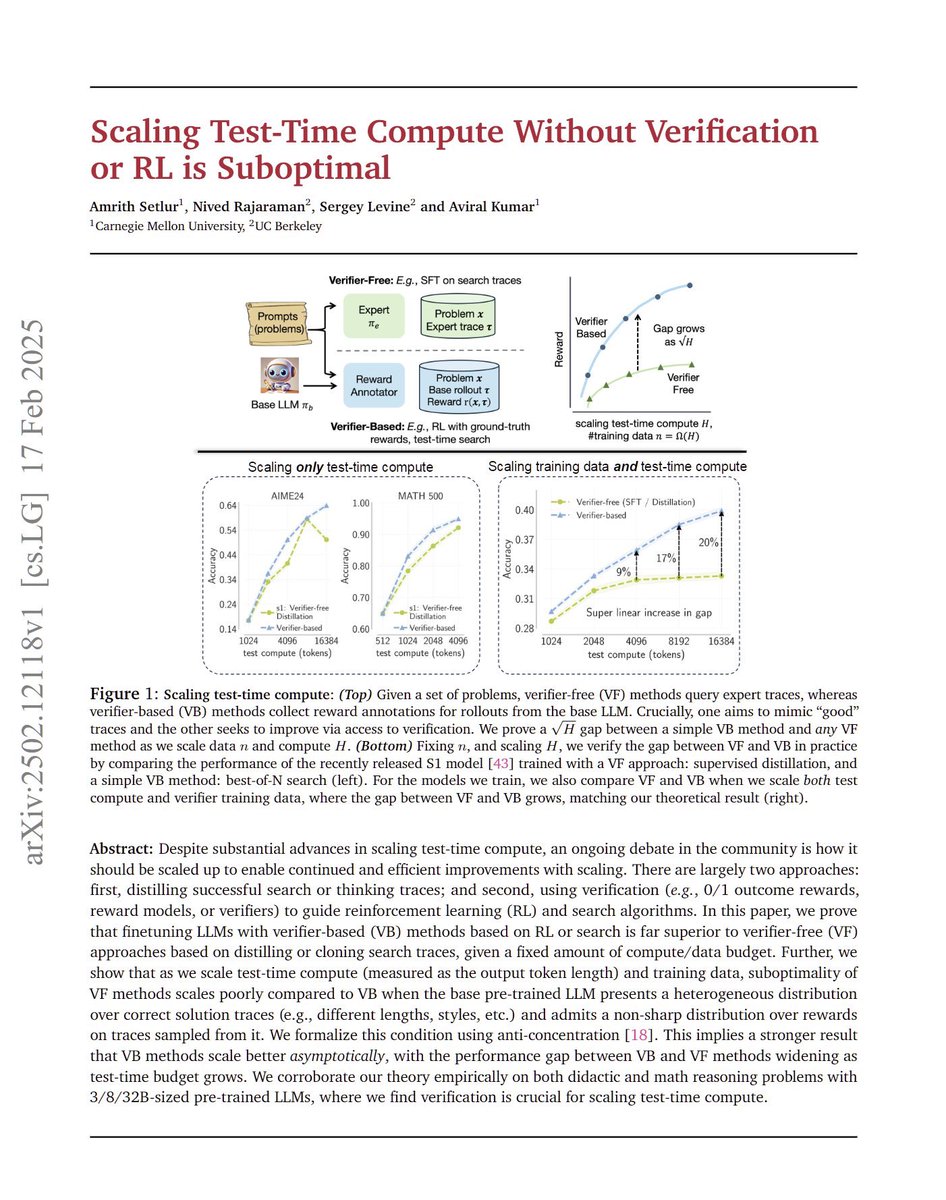
Scaling Test-Time Compute Without Verification or RL is Suboptimal "In this paper, we prove that finetuning LLMs with verifier-based (VB) methods based on RL or search is far superior to verifier-free (VF) approaches based on distilling or cloning search traces, given a fixed amount of compute/data budget."
Me using LLMs for fun little personal projects: wow this thing is such a genius why do we even need humans anymore Me trying to deploy LLMs in messy real-world environments: why is this thing so unbelievably stupid and dumb



Perfect timing, we are just about to publish TextArena. A collection of 57 text-based games (30 in the first release) including single-player, two-player and multi-player games. We tried keeping the interface similar to OpenAI gym, made it very easy to add new games, and created an online leaderboard (you can let your model compete online against other models and humans). There are still some kinks to fix up, but we are actively looking for collaborators :) If you are interested check out textarena.ai, DM me or send an email to guertlerlo@cfar.a-star.edu.sg Next up, the plan is to use R1 style training to create a model with super-human soft-skills (i.e. theory of mind, persuasion, deception etc.)