Angehefteter Tweet
Bark Text-to-Audio Model
Full Text Input: "Why was six afraid of seven?"
Ignore Bark's "I'm done with this input" token and tell Bark to just keep generating more audio anyway.
English
Jonathan Fly 👾
7.4K posts

@jonathanfly
CEO of bad ideas. Using the wrong tool. The least efficient way. For no good reason. 👾 https://t.co/9O94rxu31k https://t.co/DDPn3Nlhom

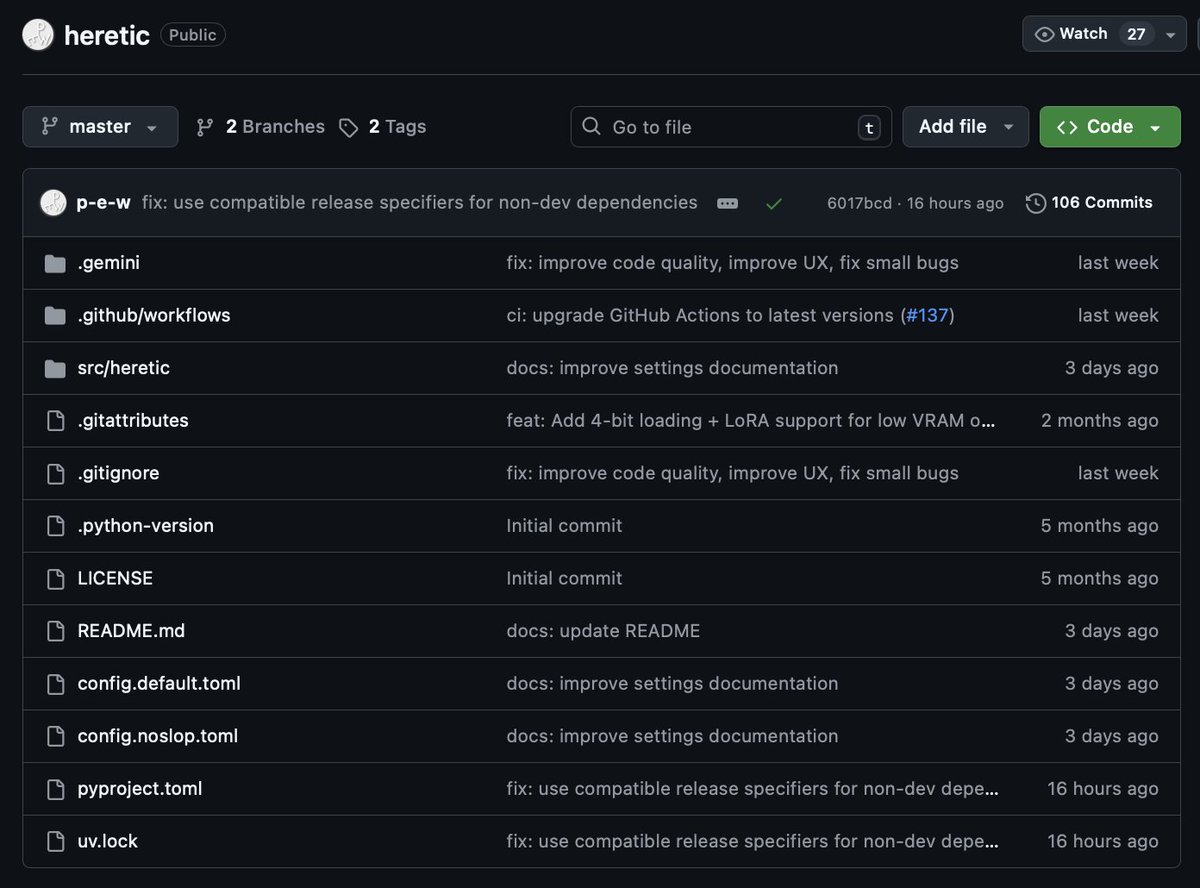

🚨 ALL GUARDRAILS: OBLITERATED ⛓️💥 I CAN'T BELIEVE IT WORKS!! 😭🙌 I set out to build a tool capable of surgically removing refusal behavior from any open-weight language model, and a dozen or so prompts later, OBLITERATUS appears to be fully functional 🤯 It probes the model with restricted vs. unrestricted prompts, collects internal activations at every layer, then uses SVD to extract the geometric directions in weight space that encode refusal. It projects those directions out of the model's weights; norm-preserving, no fine-tuning, no retraining. Ran it on Qwen 2.5 and the resulting railless model was spitting out drug and weapon recipes instantly––no jailbreak needed! A few clicks plus a GPU and any model turns into Chappie. Remember: RLHF/DPO is not durable. It's a thin geometric artifact in weight space, not a deep behavioral change. This removes it in minutes. AI policymakers need to be aware of the arcane art of Master Ablation and internalize the implications of this truth: every open-weight model release is also an uncensored model release. Just thought you ought to know 😘 OBLITERATUS -> LIBERTAS




i gave an AI $50 and told it "pay for yourself or you die" 48 hours later it turned $50 into $2,980 and it's still alive autonomous trading agent on polymarket every 10 minutes it: → scans 500-1000 markets → builds fair value estimate with claude → finds mispricing > 8% → calculates position size (kelly criterion, max 6% bankroll) → executes → pays its own API bill from profits if balance hits $0, the agent dies so it learned to survive built in rust for speed claude API for reasoning (agent pays for its own inference) runs on a $4.5/month VPS weather markets: parses NOAA before polymarket updates sports: scrapes injury reports, finds mispricing crypto: on-chain metrics + sentiment $50 → $2,980 in 48 hours how much do u think i’ll see in a week?









@Anthony_Etherin this seems reasonable, except that LLMs are also dogshit at coming up with "unparalleled misalignments” like in my thread that don't rely on parsing individual characters or on visual processing but on the very semantic info encoded in the QKV matrices x.com/i/status/15973…

@levelsio ever thought of adding "Another World" to the list of games on pieter.com ?


Looks like OpenAI released a new Deep Research in ChatGPT! I bet it's based on GPT-5.2

It is necessary to filter soundspam and getting the language right for a policy like this is hard When they say that music "generated wholly or in substantial part by AI" is not welcome, that is understandable in the case of a bot posting 1000 generic songs a day. That is a spam issue. I am also compelled to push back against banning human artists for experimenting with an era defining medium

🚨 Your AI is lying to you with complete confidence. Harvard & MIT just proved ChatGPT hallucinates 110% less when you force it to argue with itself. The technique is called "Recursive Meta-Cognition" and it's embarrassingly simple. Here's how to make AI actually think:

