Maximilian Bode retweetet

Maximilian Bode
70 posts

@mxpbode
Associate Partner @tngtech



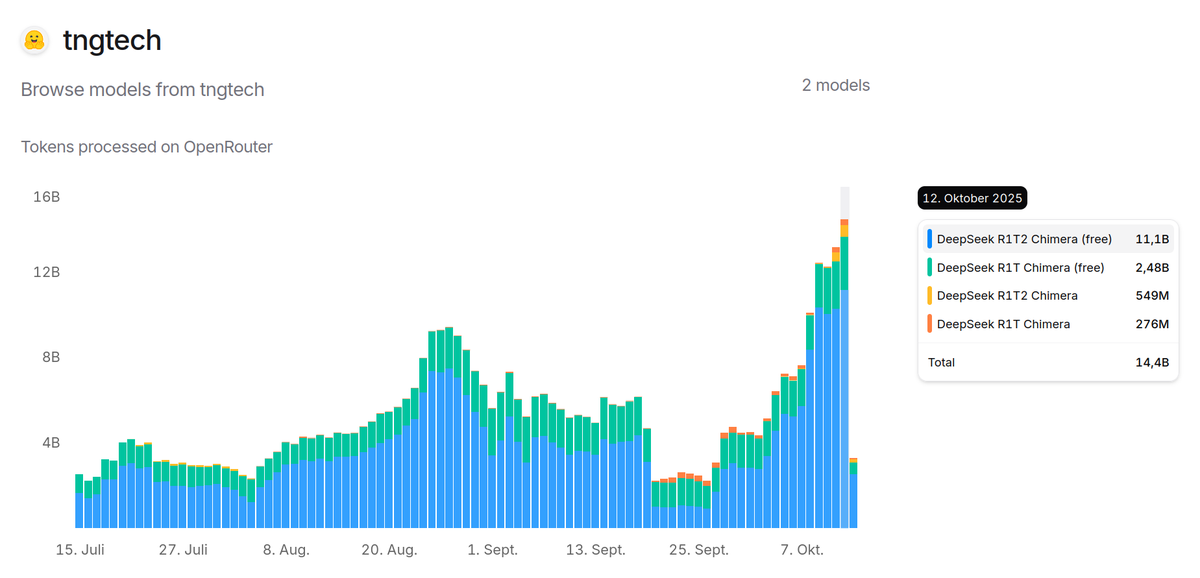
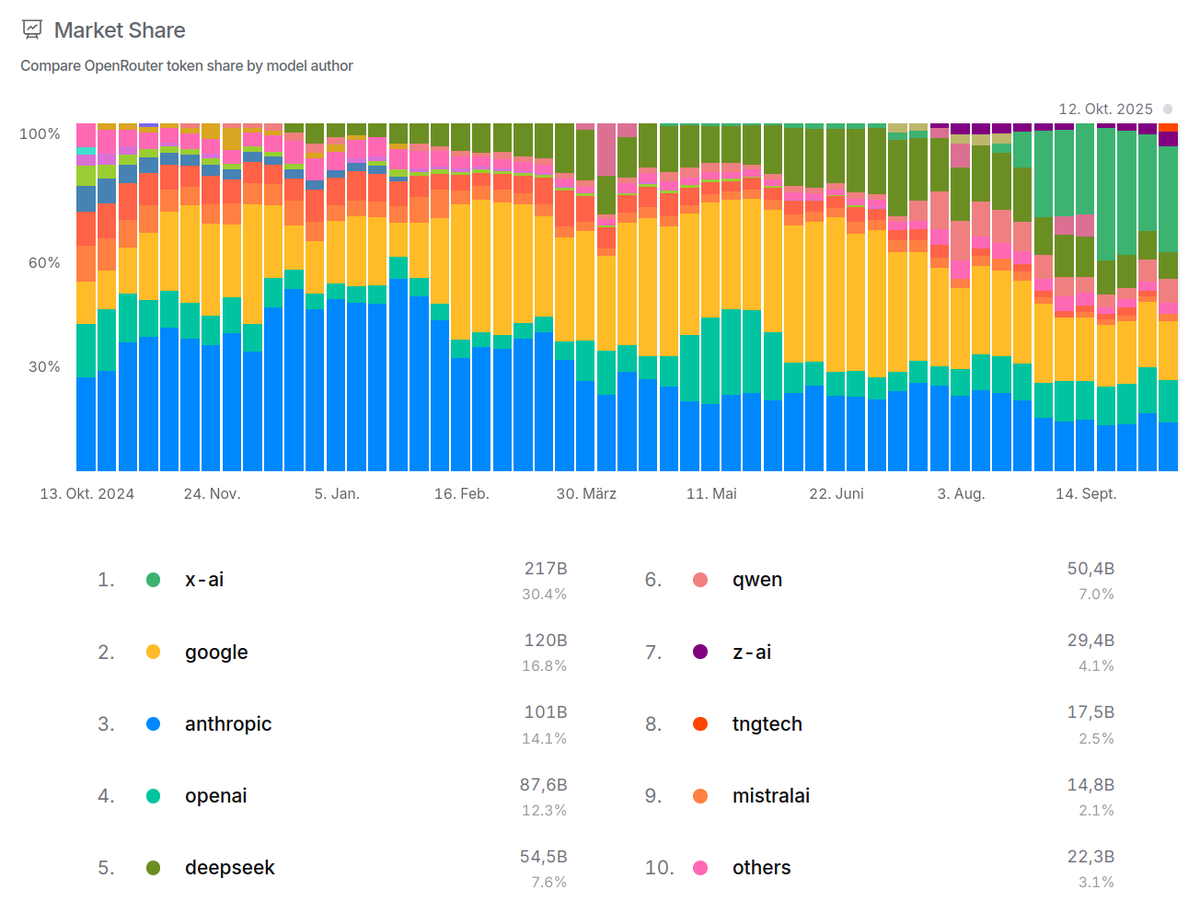
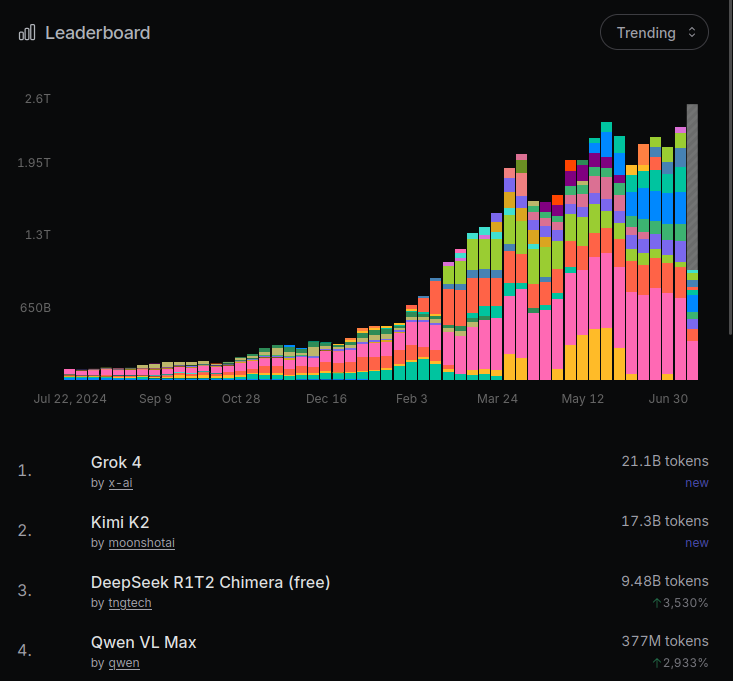
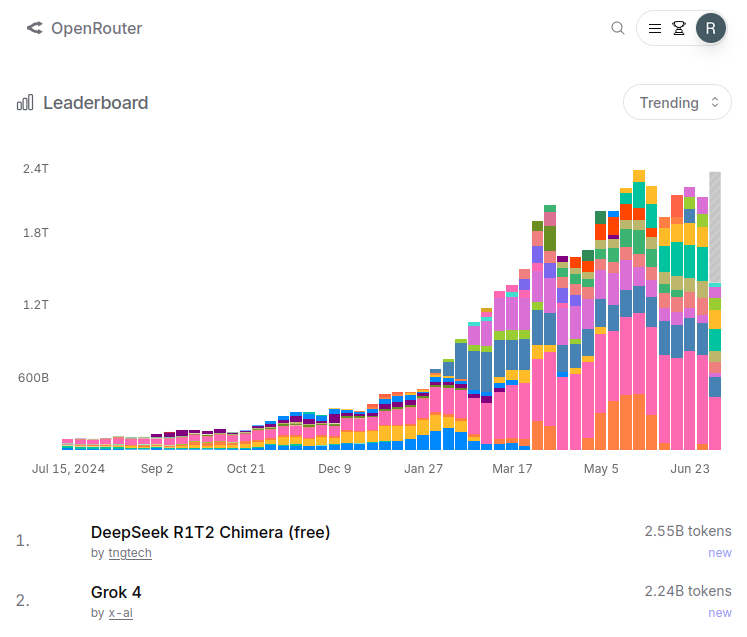
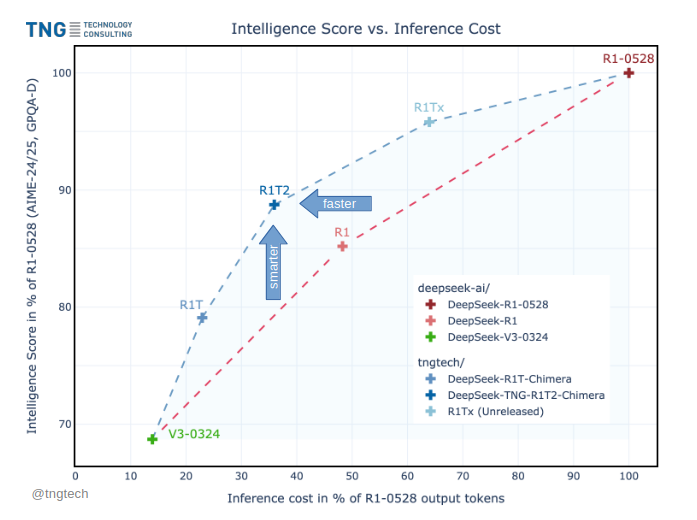
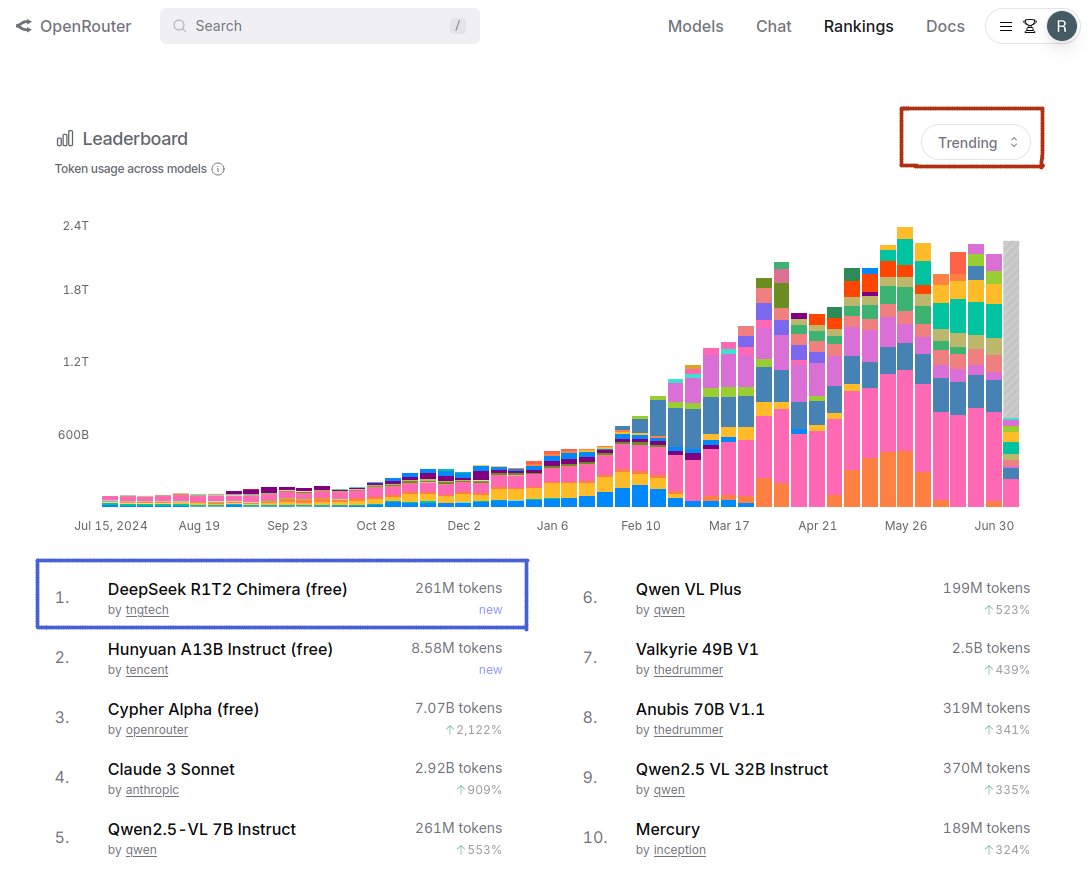
Karpathy at YC startup school calls this the transfer switch of AI. It's hard to keep up with all the LLMs out there. OpenRouter is the go-to place for 2.5M developers to choose from 400+ models with one API. They're serving 100T tokens/yr! Excited to back this special company!




Max Bode at the podium! #LambdaCon2025
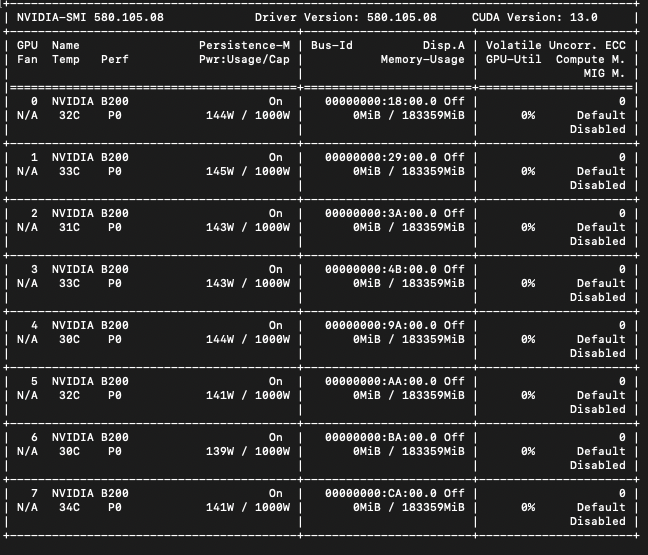
Eight new @AMD MI325X GPUs joined our compute cluster of @nvidia H100s. The new @Supermicro_SMCI server is an AI machine with spectacular 2 Terabytes of total GPU memory in one ~10kW node. ROCm worked right away with full VRAM and GPU utilization, allowing new types of experiments with ultra-large language models.