
Wit🐠
223 posts


九个月前我写过一条长推,结尾一句话:"最后我可能还是会回到喜欢的 video 领域。"
今天发布了 Cerul,为 AI agent 而生的视频搜索层。
这可能是我这辈子做得最慢的一个产品。因为细说起来和多模态、视频结交已经五年历史了
以前的视频搜索只能根据字幕做解析,Cerul 同时索引说了什么、画面里有什么、屏幕上写了什么。你发一句人话,它返回带时间戳的视频片段。
Claude Code、Cursor、OpenClaw、Hermes,任何 Agent 都能直接调。
Cerul@cerul_hq
We built Cerul to teach your AI agents to see. Nebius bought Tavily for $275M — 14 months old, text-only, 3M SDK downloads/month. Video search isn't solved. Same playbook, 10× harder, wide open.
中文

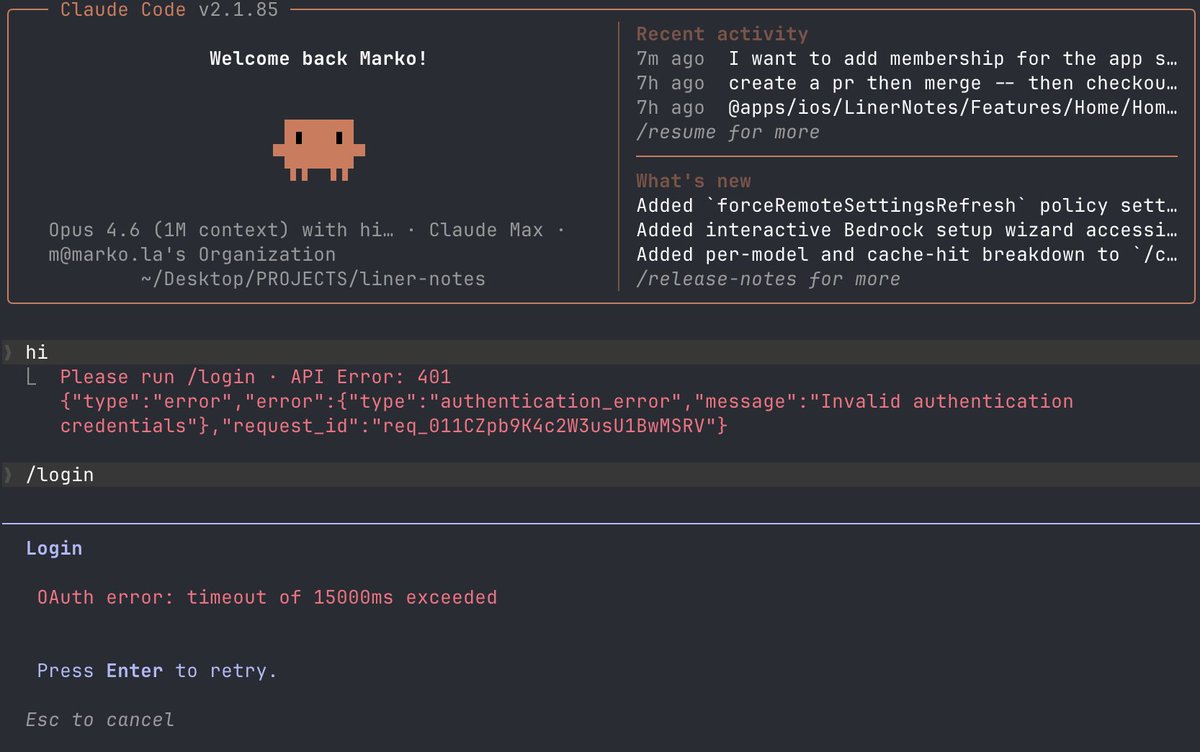
Unable to auth using /login into Claude Code today. The auth screen on claude.ai is a bit slow and then I get this error after pasting in the code "OAuth error: timeout of 15000ms exceeded".
@bcherny @claudeai @AnthropicAI
This has been my view all morning
English

@Jiaxi_Cui 标注可以认为在某种层次和人类对齐,比如实操上qwen 3 vl我这边跑10M左右数据,如果只有图片向量化qdrant搜索,不如加一层caption对具体的ip/特征有一个文字描述做混合搜索效果好。AI隐含层对两张图片相似度理解和人想要的结果不一定一致
中文
很多人凭自己的直觉认为多模态应该尽可能多的做标注
但实际并不是的,在北大做Languagebind(arxiv.org/pdf/2310.01852)的时候我就非常排斥对图片进行标注再训练或者检索
因为人为或者模型打出的标注,只是按照人类的想法把向量空间的特征映射到了人类自然语言空间而已,本来就造成了特征损失
而借助 AutoResearch,在我们的 cerul.ai 的实验上我验证了这个想法,实际上对图片的标注越多,反而越会损伤embedding检索的性能
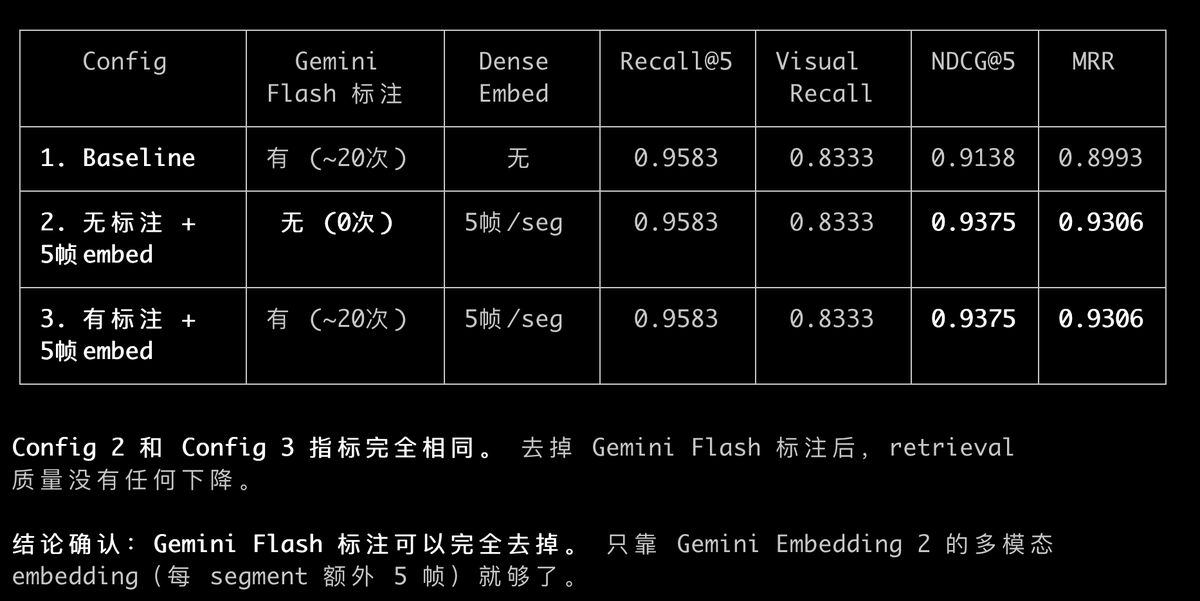
中文

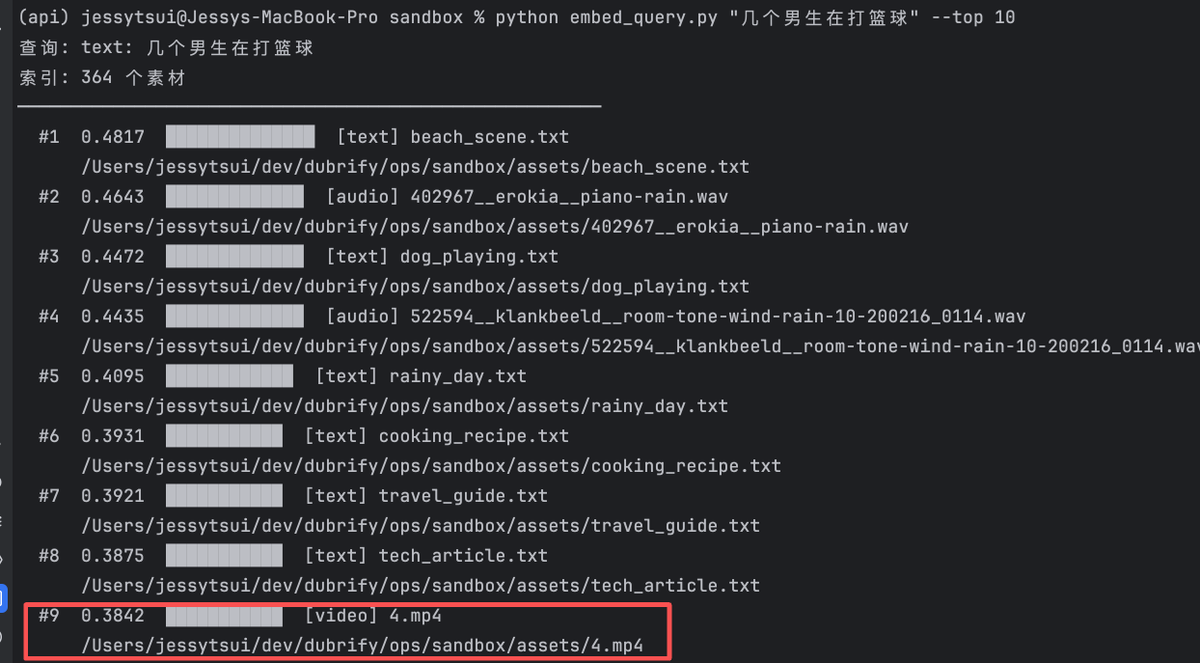
Index 了10个G的素材试了一下,模型问题还是比较大,需要做 Rerank
目前看不同模态之间的边界没有完全拉开,尤其在库内模态分布不均时,文本 / 音频结果也可能拿到偏高分数,只有经典的背景音的向量特征比较明显
比如我导入了大量篮球的图片视频,但文本、音频和PDF的素材是没有的,做 Top N 得到的结果中,文本和音频的相似度非常高
我还以为可以直接 end2end 解决问题了,看起来还需要做不断的优化。当然如果限制模态再检索,效果会稳定很多
Panda@Jiaxi_Cui
感觉 Google 是依靠 NotebookLM 积累的音频、PDF、视频数据,补齐了这三个模态的训练数据,不然很难解释为什么如此多的PDF的对齐数据是从哪来的 CLIP 时代还可以靠着互联网大量爬虫,找到 text—image pair对来做对比学习训练,但互联网上没有大量的 PDF—Audio—Video 的pair对 所以做 多模态embedding 的思路其实也变了,你不可能再依靠不授权的爬虫取得大量 pair 数据了,需要自己有真实的产品入口才可以持续积累数据 要把多模态embedding做好,实际上和是否是模型公司关系不大,就按照标准 transformer 架构,大力进行对比学习也未尝不可。所以需要的是手里有文档、Audio、Video相关产品场景的人 如果 Kimi、GLM、MiniMax 想追上 Google 在多模态 embedding 上的效果,最方便的似乎是收购现成的产品入口,比如 @lifesinger 的 YouMind 或者 @oran_ge 的ListenHub !
中文

Gemini Embedding 2 最核心的优势是 "原生多模态统一向量空间",具体来说:
- 最强优化点:原生音频 embedding(无需转录)。 这是它区别于所有竞品的独家能力。
- Qwen3-VL-Embedding 和 voyage-multimodal-3.5 都不支持音频。
传统做法是先用 ASR 将音频转文字再做 embedding,但这样会丢失副语言信息(语调、重音、说话人身份)、增加延迟,且对非语音音频(音乐、环境音等)完全失效。Gemini Embedding 2 直接对原始音频波形建模,跳过了这些问题。
其次几个关键优化:
- 单请求交错多模态输入 — 可以在一个请求中同时传入图片+文本+音频,模型理解它们之间的语义关联,而不是分别编码后拼接
- 4种模态统一到同一向量空间 — 文本查音频、图像查视频、音频查文本等跨模态检索天然支持,无需额外对齐训练
- MRL 灵活降维 — 3072 可缩到 768,在存储成本和精度之间灵活权衡
不过它目前的短板也很明显:仍是 Preview 状态、文本上限只有 8192 tokens(Qwen 和 Voyage 都是 32K)、不开源不可微调。
希望qwen能继续跟上这块😹 国内好像没有其他能打的啦

Google AI Studio@GoogleAIStudio
中文

做了一个月广告投放 AI,调研了 20 个竞品后的一个判断,这个赛道分两种玩法:
第一种,给你一个 Dashboard,登录进去点点。 Optmyzr、WordStream、Madgicx 都是这个路子。好用,但本质还是人在操作,AI 只是建议,甚至很多都还是基于规则集来做的。
第二种,给 AI Agent 一套 API,让 Agent 自己操作你的广告账户。读数据、加否定词、调预算、暂停烧钱的词、跑审计。全自动,不用打开任何后台。
我选了第二种。原因很简单:
Dashboard 的天花板是你的时间。
API 的天花板是 Agent 的能力。
Agent 一年比一年强,Dashboard 一年还是 Dashboard。
现在 AdWhiz 有 100 个 MCP 工具,同时支持 google 和 meta 广告,任何 AI agent 都能直接调用。
我看到的全球在做 MCP 广告 API 的不超过 5 家,大部分只能读数据,不能写操作。我们是少数能读能写、还有完整审计 + 健康评分的。
有个欧洲客户用我们的 MCP 对接 DuckDB + agentic team,搭了一套 DSA否定词自动化流水线,直接省掉了一个 performance manager 的招聘。这种玩法传统 Dashboard 根本做不到。
这个窗口期不会太长。adwhiz.ai
中文
Wit🐠 retweetet

我们的AI作品集出炉啦!
这是我们 2xLabs 近半年的心血总结
汇集了已上线及未公开的视觉方案,
其中涵盖:影视、剧集、2D动画、CG动画,
以及各种特效领域。 所有画面 100% 纯AI生成!
原创音乐:束丹年
🤖 感谢大家长期以来的关注与支持❤️
🔥 Our AI showreel is finally out!
A culmination of our hard work at 2xLabs over the past 6 months.
Bringing together both released and exclusive unreleased visual solutions, covering: Films & TV series, 2D & CG animation, and various Visual Effects (VFX). All visuals are 100% purely AI-generated!
Original Music: Dannian Shu
🤖 Thank you all for your continuous support! ❤️
#2xLabs #AIVideo #AIFilm #GenerativeAI #AIAnimation #VFX #Showreel #Kling #可灵AI #Dreamina #即梦 #Sora #Runway #AIart #Seedance #Grok
中文

fork的agent-browser 正式改名为 agent-browser-session.
特点是和官方的同时使用,没有冲突。
最近agent-browser官方的更新还是很频繁的, 然后我就想到了一个问题, 与其费时间两者保持同步, 不如按照场景需求同时使用两个版本, 一下子纠结的问题解决了。
官方版本用headed方式打开, 打开chrome会有 “google chrome for testing"的字样,这个字样出现后你登陆google 帐户基本直接触发封控。 新版本主要是解决这个问题。
默认持久化用户数据, 也可以自定义session name,同样持久化。
也就是说, agent-browser你两个版本同时使用, 官方无头版本做无登陆需求的数据日常抓取, 特点是速度快; session版本做登陆验证, 做封控检测, 做速度限制,以及将浏览器内置测试特性都去掉。
持久数据位置为: ~/tmp/agent-browser/{session}/
github repo见👇

中文

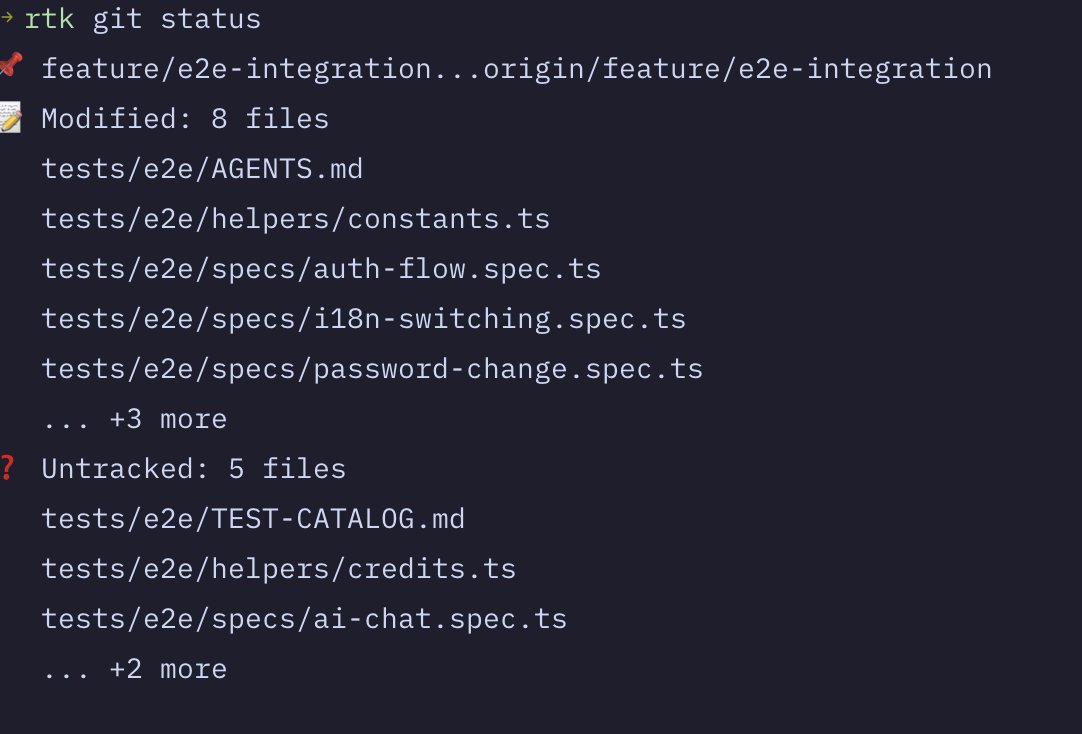
今天用了这个 rtk 可以大幅节省 token,github.com/rtk-ai/rtk 用 Rust 写一个 CLI 工具,本质上是一个输出压缩器,去掉所有不需要的内容,分组以及智能截断,它不改命令本身,而是在命令执行后、结果返回给 LLM 之前把输出大幅精简。
比如 git status 可以写成 rtk git status ,大家安装以后可以看看效果。
有 4 种压缩策略,每种命令都有针对性实现,它自己repo 当中的测试显示可以节省 80% 的 token。
可以初始化全局 hook,在 ~/.claude/settings.json 里自动添加 PreToolUse hook,指导之后的 LLM 全都使用这个 rtk 进行包裹。
大家可以去试试看效果。
中文
Linear + Obsidian + QMD:AI 时代的个人项目管理栈
(这个组合解决了我长期关注的问题)
核心理念:任务和知识分离
- Linear 管「做什么」— issues、checklists、状态流转
- Obsidian 管「做了什么、为什么」— 设计决策、架构文档、操作记录
- 两者通过 commit links 和 issue ID 双向关联,互不侵入
Linear 侧的实践
- 每个项目一个 Linear Project,issue title 带编号前缀(P1、P2)方便口头引用
- Issue description 用 markdown checklist 当执行清单,完成一项勾一项
- 完成 issue 时在 description 末尾加 ## Commits 段,链接对应的 git commit
- Linear 状态管理:个人项目直接 main 提交 + 手动更新 Linear;协作项目走 PR 流程(gh pr create 在终端完成,Closes BUNOTES-xx 自动关联)
Obsidian 侧的实践
- projects/{name}/ 子目录存项目文档,一个项目一个文件夹
- Frontmatter 是关键:commits 字段链接代码、aliases 放 issue 编号(如 P1、BUNOTES-37)便于搜索
- 不记流水账,记决策和结论 — 「为什么选 cherry-pick 不选 rebase」比「今天做了 xx」有价值
- 文档状态只有 draft 和 complete,不搞复杂状态机
QMD 串联一切
- 所有 Obsidian 笔记自动索引,支持关键词搜索和语义搜索
- Claude Code session 记录也被索引 — 几周前的调试过程可以被找回
- 搜 issue 编号能同时找到 Obsidian 文档和历史 session 上下文
Claude Code 作为执行层
- 开发时同步维护两侧:创建 Linear issue → 编码 → 提交 → 更新 issue checklist → 写/更新 Obsidian 文档
- Skill 里写清规范(frontmatter 格式、commit 字段必填),AI 自动遵守
- 一个 session 内完成代码 + 任务管理 + 文档,不需要手动切换工具
反直觉的点
- 不需要完美的双向链接 — commit hash 就是最好的链接,在 Linear 和 Obsidian 都能搜到
- 不需要模板引擎 — frontmatter + 目录约定就够了
- 不需要自动同步 — 人为确认「这个 issue 确实完了」再手动更新,比自动化更可靠
- QMD 的价值不在「随时搜索」,在于「几个月后还能找回当时的决策上下文」
中文




抱歉家人们,今天才看到很多私信(私信都被折叠进requests里面了)。
给回复晚了的朋友说声对不起🙏
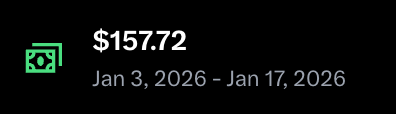
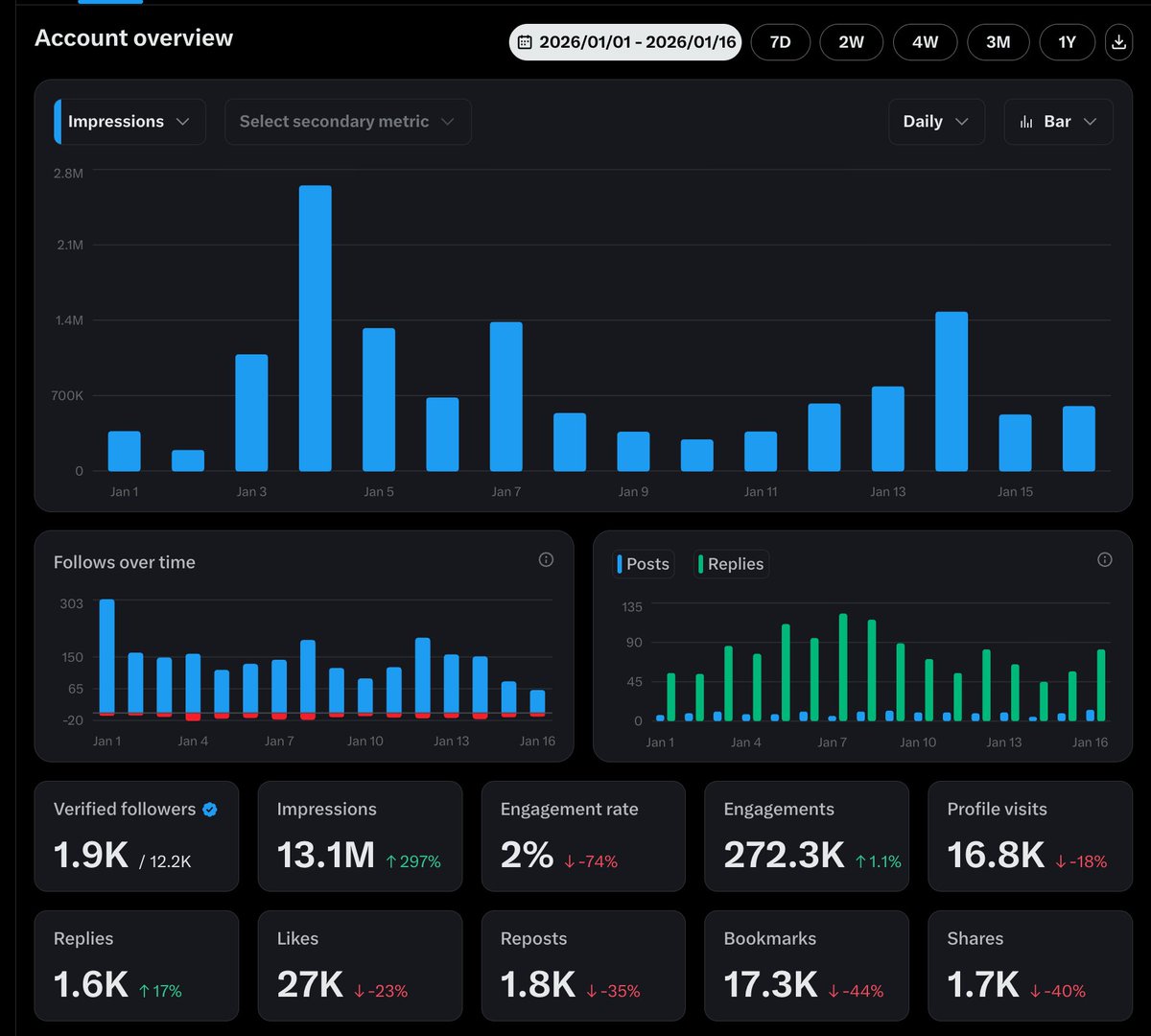
顺便更新一下进展:昨天“低保”到账 157 美金,对应大概 1300 万曝光,收益确实不多。
所以我在尝试新的方向和策略,把创作者收益做上去(不保证一定有效)。
想围观/交流的可以继续私信我。
underwood@underwoodxie96
【广告】英推(X)长期运营小社群 过去 1 个月,我的英推账号 曝光(Impressions)> 1000 万,数据本账号可查。 我想组建一个低噪音、重执行的小社群:内测期 即日起—3 月 1 日,入群 99 元/人(服务/内容更新到 3 月 1 日为止)。 如果你想长期做英推,但对「怎么起步」「怎么稳定增长」还没形成方法论,可以考虑加入。 适合谁: 1. 至少在英推发过帖/有运营经验,想在英推系统增长的人 2. 想在 AI 生图 / AI 视频 方向长期耕耘的人 你会得到什么: 1. 每日分享:我每天在英推上发现的东西——看到啥、学到啥、踩到啥坑,就顺手分享(选题/表达/案例/数据) 2. 我测试/观察到的可能有效的发帖策略(可复用的套路、模板、注意事项) 和其他社群不一样: 1. 可以潜水:以我输出为主,你想看就看,也欢迎讨论 2. 低噪音:不搞打卡内卷,不做互赞互关式“互助”,只做可执行内容 不提供 / 不适合: 1. 商单对接 2.互推互赞、强制互动之类服务 3.想以中文长文/纯文字内容为主要增长路径的人(我主要分享 英文 + AI图片 + AI视频 的打法) 想加入:评论或私信我「社群」,我把入群方式发你。
中文





@jesselaunz Google肯定没法看到文章本身是人写的还是AI写的,算法主要还是看停留时间和bounce rate,就用户交互数据来说,还有哪些指标值得关注?主要想听听SEO老炮filter过的想法
中文

关键处在于必须经过自己的热诚去人工review
你自己都觉得垃圾的东西,就绝对不要deploy
因为即使你deploy了,也可以保证绝对没有鸟用,没有鸟用的东西就跟以前一样会消失在互联网
这是Google的内容提取算法决定的事情
Google的算法决定了只有有用的东西(页面驻留时间+bounce rate低等等)才能长时间存在在搜索的前列
目前的AI的确能10倍百倍的生产出比AI前时代质量更高,用户更满意的project
如果你觉得只能生产出垃圾,那是因为没有以“我为人人,人人为我”的思想来作事情
Jesse Lau 遁一子@jesselaunz
x.com/win1688888888/… 没有AI前也有无数的垃圾代码垃圾内容 根本就rank不了 现在的AI vibe code只能说能生成比以前人工做的质量更高,且速度更快 我的网站每天都有收到好评邮件
中文
产品整体非常好用,但对于上下文比较复杂的情况比如翻页偶尔出错,但产品本身可以选择人工介入有点claude plan的味道。之前一直在找开发者,原来一直在推上
Robin@weikangzhang3
🚀 隆重推出 AIPex:将您的浏览器变成AI浏览器。 无需迁移。无需新浏览器。就在您已经工作的地方,获得纯粹的AI功能。 留在原地。保持隐私。保持高效
中文