
Pascal2_22./
1.2K posts

Pascal2_22./
@Pascal2_22
Accelerating @Gradient_HQ Advancing OIS stack: ./ Open AI for Sovereign Future. Make it you against the matrix
Accra, Ghana Joined Ağustos 2023
266 Following259 Followers

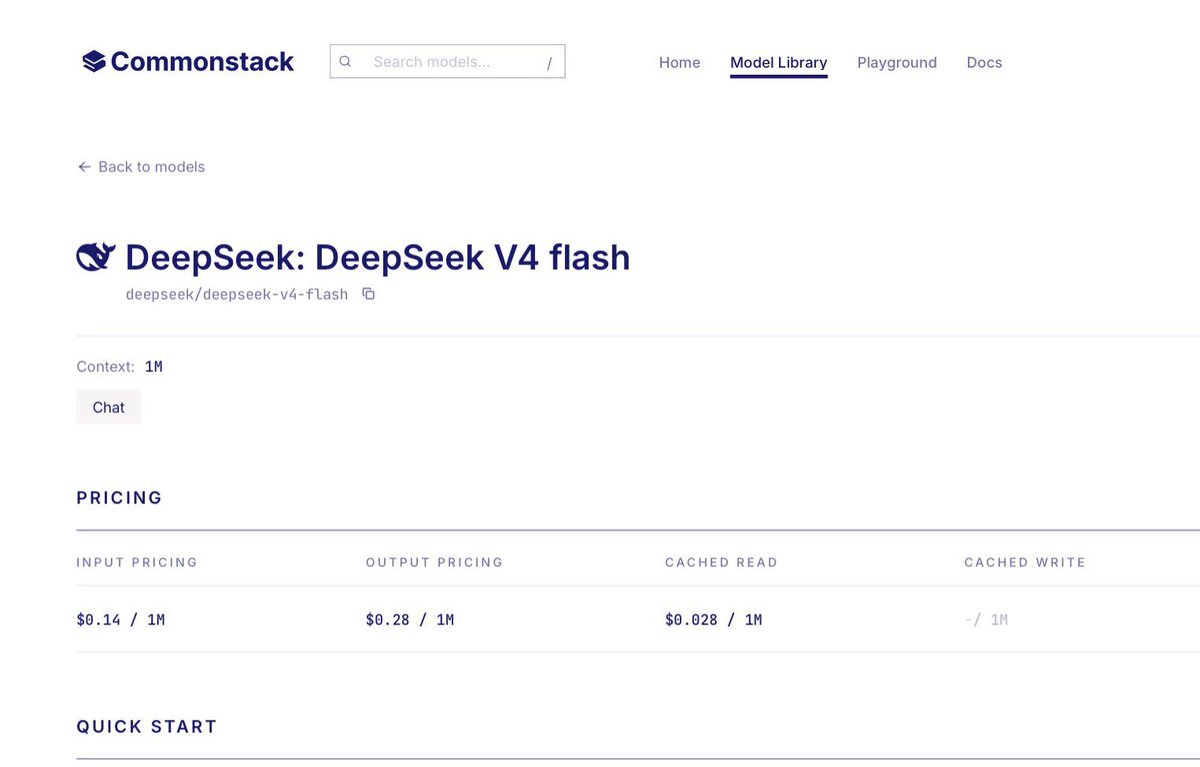
DeepSeek V4 Flash is now live on @commonstack_ai
9.8x lower FLOPs than V3.2. 13.7x smaller KV cache. 1M context window.
$0.14 input / $0.28 output per 1M tokens. Cached reads at $0.028.
Frontier level architecture efficiency at a fraction of the cost.
One key. One integration. Ready to route.
Pascal2_22./@Pascal2_22
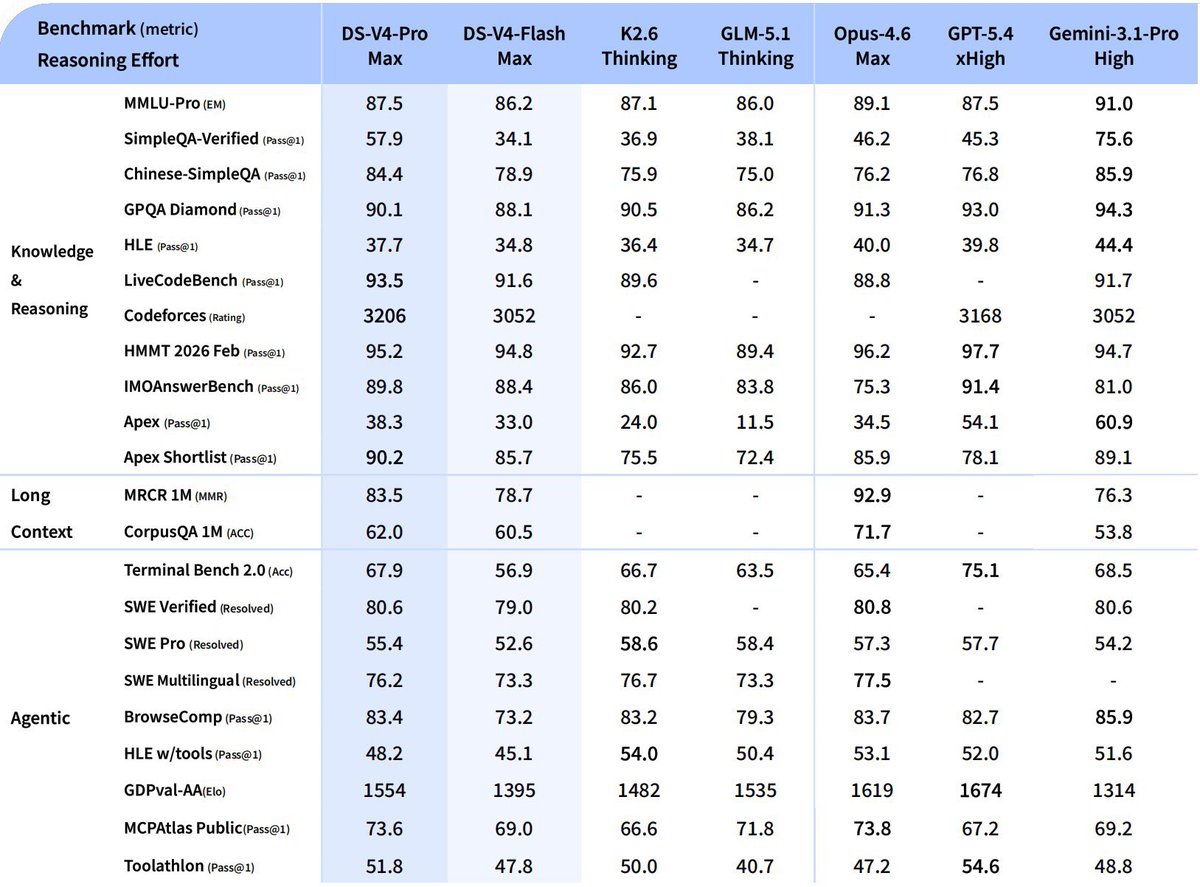
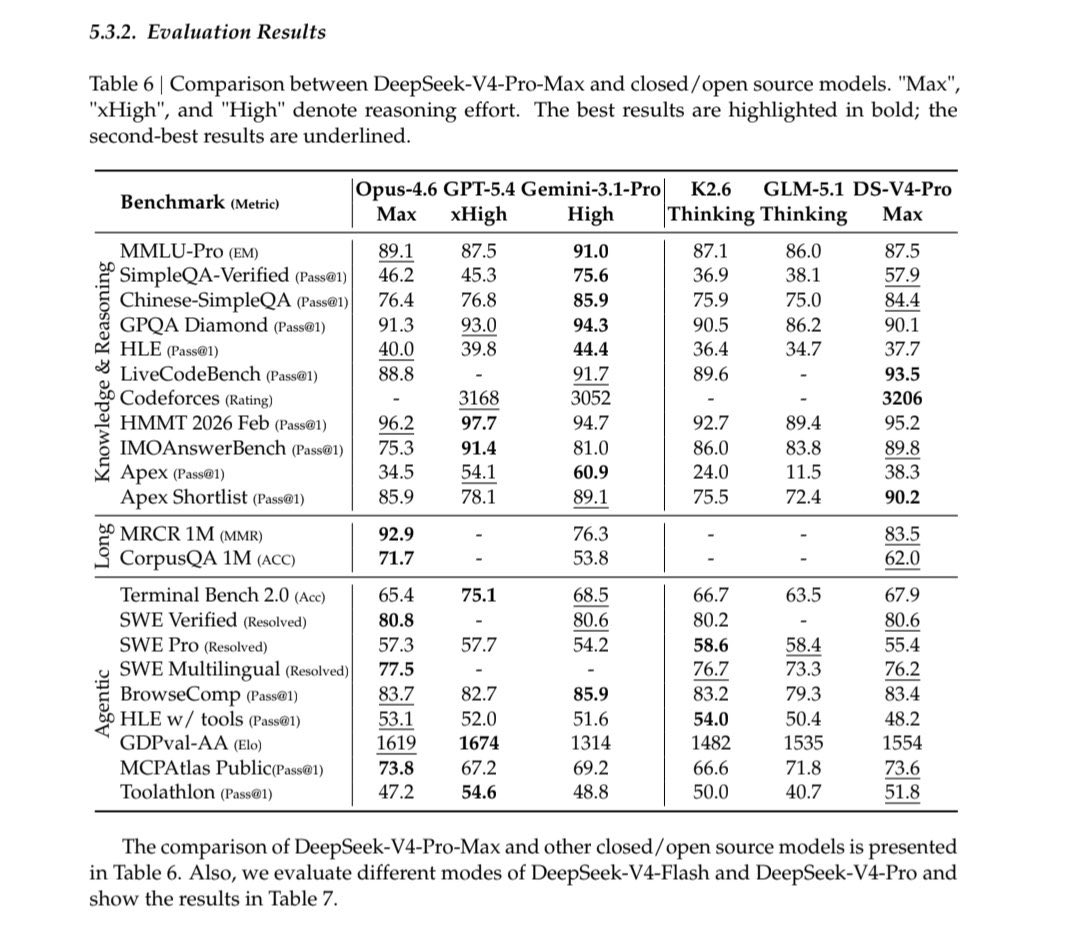
The right charts show exactly how constrained Labs redesign attention to need less HBM. DeepSeek didn't solve long context by throwing more memory at it. They redesigned how attention accumulates memory so the KV cache stays flat instead of growing linearly. That's architectural innovation under resource constraint not hardware brute force as Frontier Labs approach it. The left Chart shows: Performance of DeepSeek V4 Pro Max, beating or matching Claude Opus 4.6, GPT-5.4 and Gemini 3.1 Pro across nearly every benchmark. Knowledge, reasoning, agentic tasks. The performance gap between V4 and frontier closed source models is either marginal or nonexistent on most tasks. On the Right chart, the Efficiency of Deepseek V4 Pro runs at 3.7x lower FLOPs than V3.2 at long context. V4 Flash runs at 9.8x lower FLOPs. KV cache — the memory that explodes as context grows — is 9.5x to 13.7x smaller. Same benchmark performance. Fraction of the compute and memory cost. Frontier labs scale infrastructure to match model demands. DeepSeek scales architecture to outrun the hardware bill.
English

DeepSeek V4 flash is now available on @commonstack_ai
DeepSeek V4 Flash matches GPT-5.4 (High) performance but at a fraction of the cost:
> Input: $0.14/M vs $30/M (214x cheaper)
> Output: $0.28/M vs $180/M (643x cheaper)
Both support 1M context. A real bargain for high-intelligence workloads.

English
Deepseek V4 flash is now available on @commonstack_ai by @Gradient_HQ , you can try it for free with test credits: commonstack.ai/account/signup…
English
The right charts show exactly how constrained Labs redesign attention to need less HBM. DeepSeek didn't solve long context by throwing more memory at it.
They redesigned how attention accumulates memory so the KV cache stays flat instead of growing linearly. That's architectural innovation under resource constraint not hardware brute force as Frontier Labs approach it.
The left Chart shows: Performance of DeepSeek V4 Pro Max, beating or matching Claude Opus 4.6, GPT-5.4 and Gemini 3.1 Pro across nearly every benchmark. Knowledge, reasoning, agentic tasks. The performance gap between V4 and frontier closed source models is either marginal or nonexistent on most tasks.
On the Right chart, the Efficiency of Deepseek V4 Pro runs at 3.7x lower FLOPs than V3.2 at long context. V4 Flash runs at 9.8x lower FLOPs. KV cache — the memory that explodes as context grows — is 9.5x to 13.7x smaller.
Same benchmark performance. Fraction of the compute and memory cost.
Frontier labs scale infrastructure to match model demands. DeepSeek scales architecture to outrun the hardware bill.

English


Deepseek V4 Pro Max gives you GPT 5.4 max & Opus 4.6 max at a fraction of the price.
Whale dropped after everyone else dropped this month.
Open source will win. 🐋
DeepSeek@deepseek_ai
🚀 DeepSeek-V4 Preview is officially live & open-sourced! Welcome to the era of cost-effective 1M context length. 🔹 DeepSeek-V4-Pro: 1.6T total / 49B active params. Performance rivaling the world's top closed-source models. 🔹 DeepSeek-V4-Flash: 284B total / 13B active params. Your fast, efficient, and economical choice. Try it now at chat.deepseek.com via Expert Mode / Instant Mode. API is updated & available today! 📄 Tech Report: huggingface.co/deepseek-ai/De… 🤗 Open Weights: huggingface.co/collections/de… 1/n
English

DeepSeek V4 is actually insane. Just saw the benchmarks and it's outperforming frontier models in coding and reasoning while being a fraction of the cost. @deepseek_ai seeking deep!
English


@tryParallax is the ultimate operating system that turns mismatched hardware into one unified service.
Model too big for one machine? Parallax shards it across your laptop, a lab GPU, a teammate's workstation, orchestrated seamlessly opening up a wide range of ways to host and run AI apps and agents on your own infrastructure. Sovereign. Yours. @Gradient_HQ
rw ./@gradientintern
Awesome to see @tryParallax’s distributed framework for heterogeneous machines being implemented and serving up inferences! Build and customize your own clusters for AI like never before 🤖 ./ LFG @Gradient_HQ
English

Kimi K2.6 just dropped and it's sitting at #4 on the Artificial Analysis Intelligence Index—trailing only the big three (Anthropic, Google, OpenAI at 57).
Here's what actually matters:
The agentic performance is wild. Elo jumped from 1309 (K2.5) to 1520 on GDPval-AA.
This thing handles real knowledge work like presentations, analysis, code execution with tools.
96% on τ²-Bench Telecom puts it in the same tier as frontier models for tool use.
Hallucination rate dropped hard. 39% (down from 65% in K2.5). It's learned to shut up when it doesn't know something instead of making stuff up. That's the gap between useful and dangerous in production.
Token usage is high (~160M for the full benchmark) but so is everyone else at this level. Claude Sonnet 4.6 uses ~190M. GPT 5.4 uses ~110M. You're paying for reasoning quality, not efficiency.

English
English
@Pascal2_22 It's something big to look forward to./
Win win
English
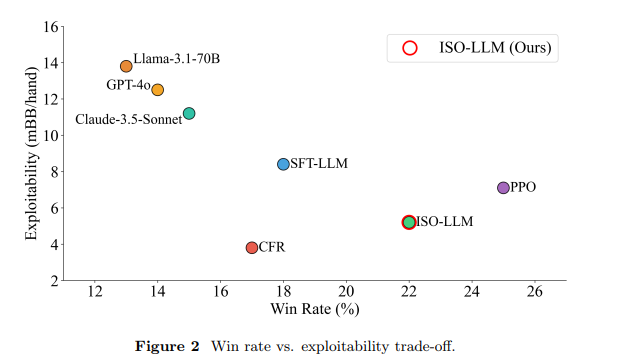
Win rate is a terrible proxy for long-horizon AI performance.
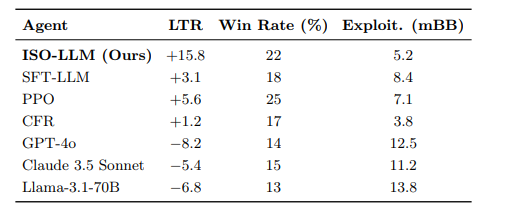
6-player No-Limit Hold'em results
-- PPO: 25% win rate, +5.6 BB/100 (wins small pots, loses value)
-- ISO-LLM: 22% win rate, +15.8 BB/100 (strategic value optimization)
-- GPT-4o: 14% win rate, -8.2 BB/100 (zero-shot fails)
ISO by @Gradient_HQ achieves 3x better long-term returns while being harder to exploit. Strategic foresight > greedy optimization
English


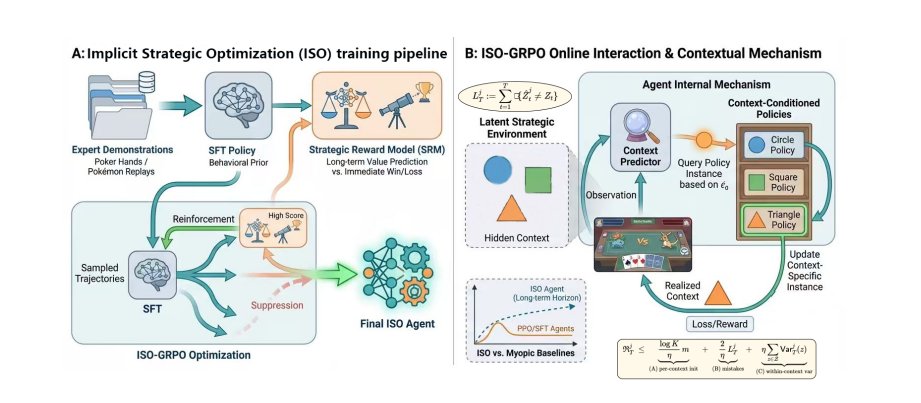
Most AI agents optimize for win rate and fail in long-horizon games because they treat non-stationarity as pure noise instead of predicting strategic regimes.
ISO by @Gradient_HQ introduces prediction-aware learning: agents forecast strategic context and adapt policies in real-time.
Here's how it works:
Pipeline: Expert demos → SFT → Strategic Reward Model → ISO-GRPO Runtime: Predict context → Route policy → Update learner
Result: 10.6x cheaper regret, equilibrium convergence scaling with prediction accuracy not horizon length. Win rate ≠ long-term value. Strategic foresight wins.
English

It’s been a year since I started diving into AI, and honestly, it’s been an eye-opening journey.
I’m also grateful to have been part of the @Gradient_HQ community for the past year being surrounded by people who share the same curiosity and passion makes the whole experience even more meaningful. What began as simple curiosity turned into a deep interest in understanding how AI works and how fast it’s evolving.
Every day feels like there’s something new to learn from tools, to concepts, to real-world applications. It hasn’t always been easy, but the process of figuring things out step by step is what makes it rewarding.
I’m still learning, still adapting, and still exploring the endless possibilities in AI. Big thanks to @HexxRL and @VinoisAsian for the support and for being part of this amazing experience 🤝
English