Shom
682 posts


Shom
@ShomLinEd
language model | sequence modeling | education | HCI





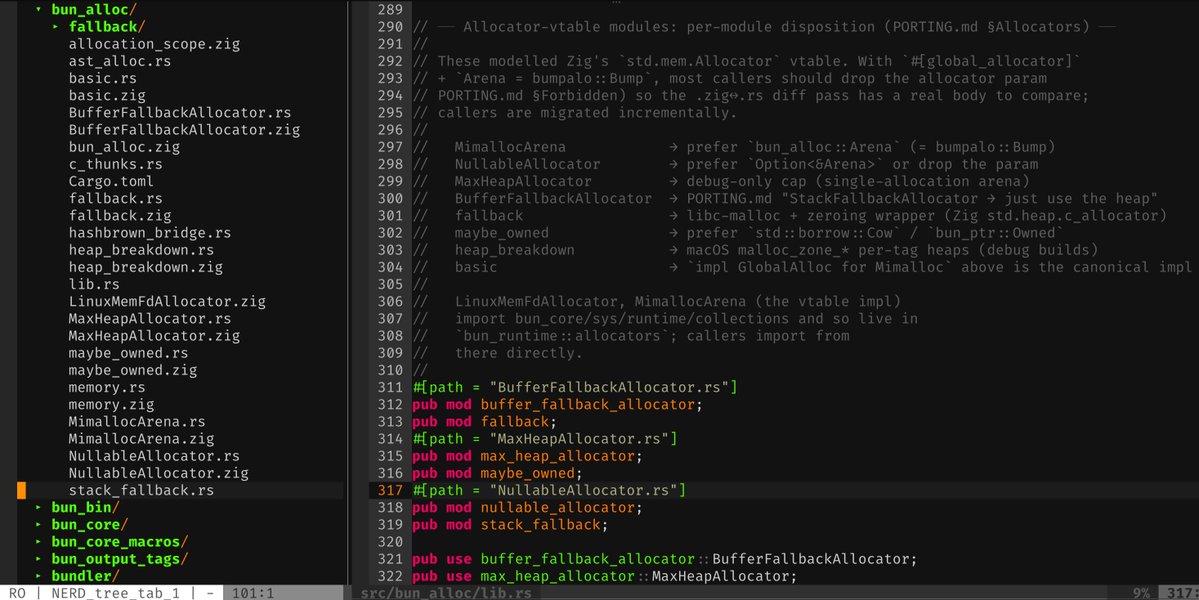
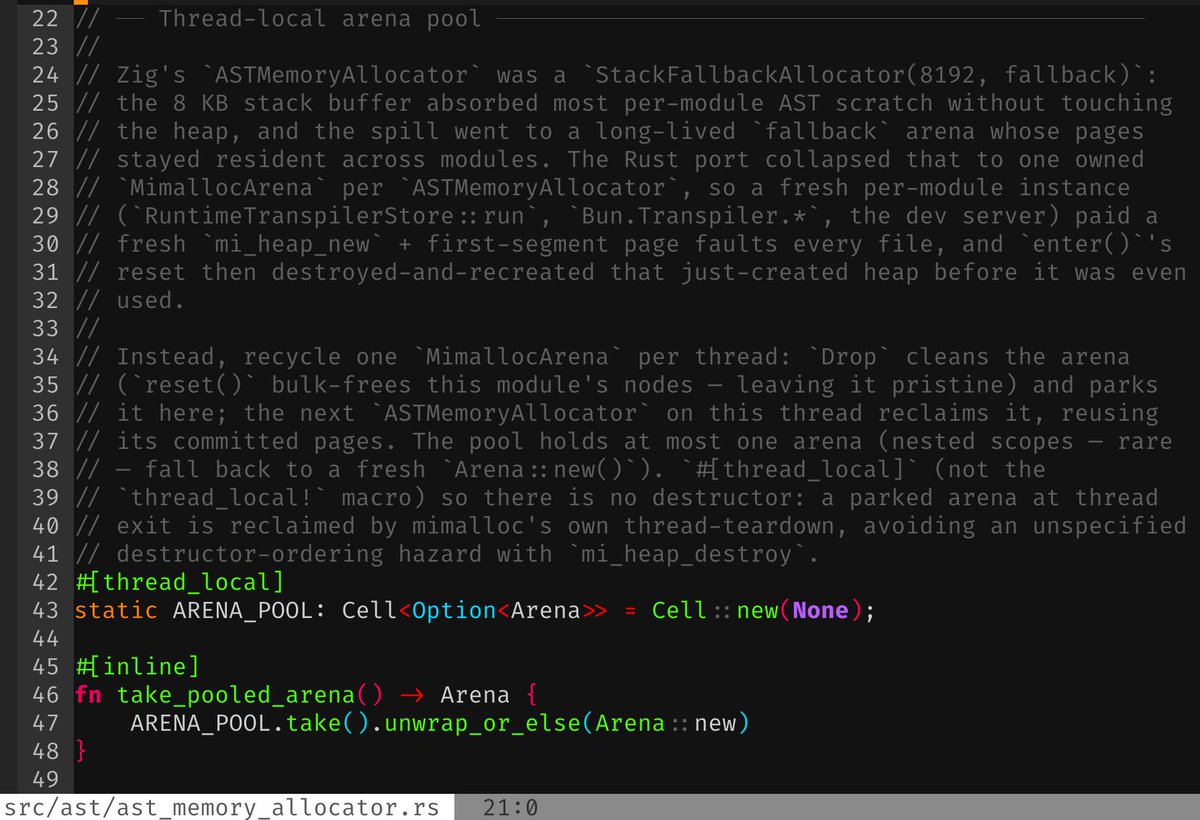


$200 FREE CREDIT! We just launched our inference platform for beta testing, and we're giving it to the community first. ⭐ Star SGLang on GitHub (github.com/sgl-project/sg…) + repost this to claim your credits. → Limited spots, first come first serve → Deadline: May 13, 2025 (AoE) Every star, every issue filed, every PR reviewed, every question answered in Slack — You built this with us. Thank you for believing in open-source AI infrastructure, in our mission, and in us. Claim your credits: platform.radixark.com





Announcing Talkie: a new, open-weight historical LLM! We trained and finetuned a 13B model on a newly-curated dataset of only pre-1930 data. Try it below! with @AlecRad and @status_effects 🧵

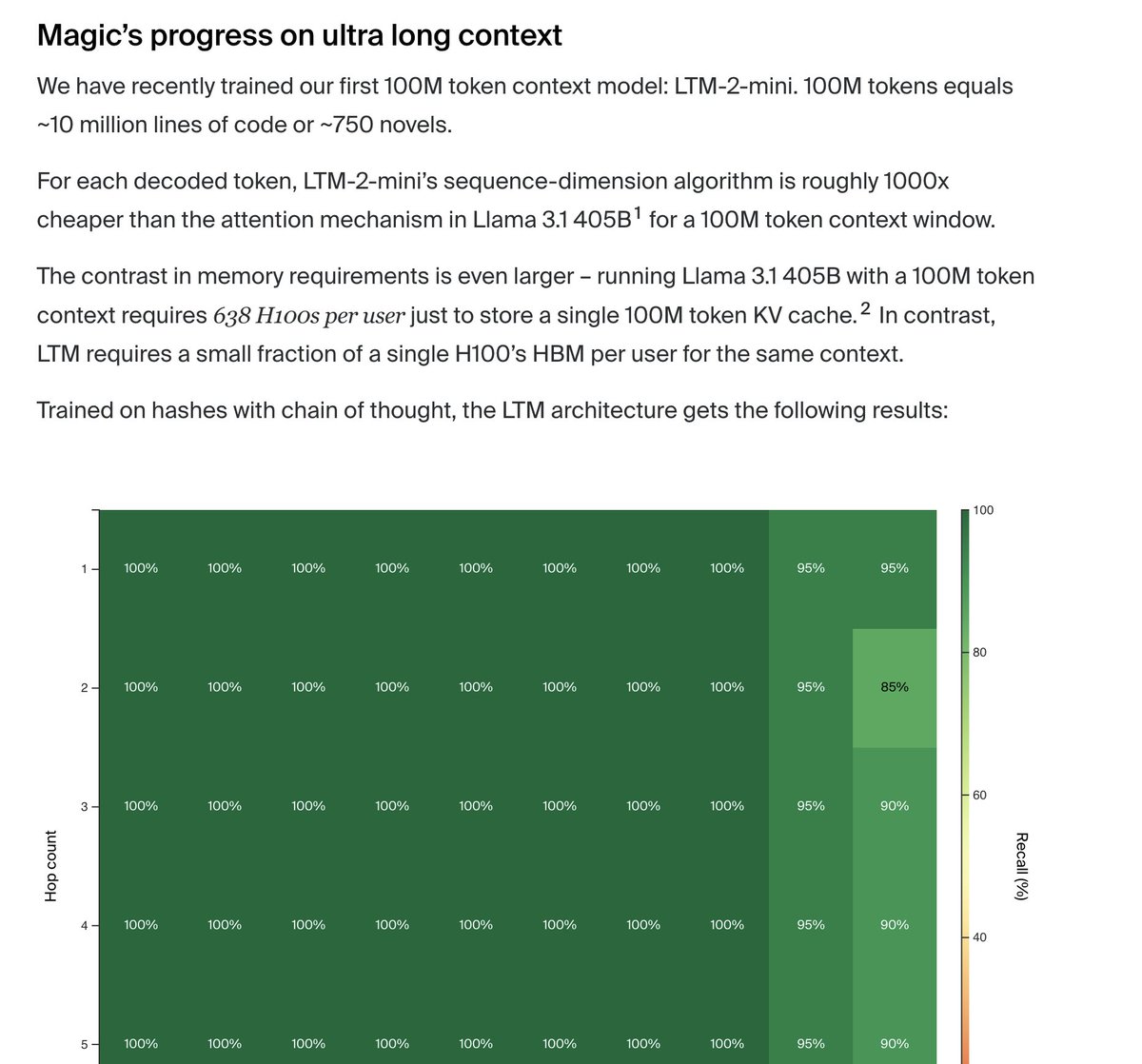
does anyone know what magic dot dev is doing now. it's been one year and we didn't see anything.

We're open-sourcing FlashKDA — our high-performance CUTLASS-based implementation of Kimi Delta Attention kernels. Achieves 1.72×–2.22× prefill speedup over the flash-linear-attention baseline on H20, and works as a drop-in backend for flash-linear-attention. Explore on github: github.com/MoonshotAI/Fla…

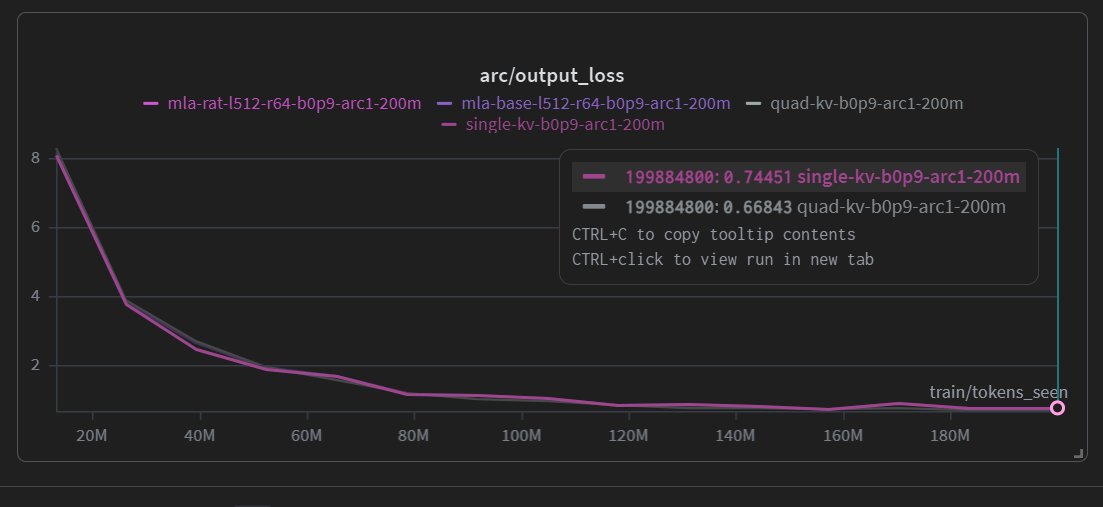
Also something like MLA should be trained like QAT but instead of converting a high precision matrix to low precision you convert a full rank master weights into low rank latent projections. You could then also do QAT on the latents maybe with turboquant and add an extra set of "perturb" weights to store how the quantization might affect the exact parameters for faster inference.




Fun project of the day. I have an AI Agent autonomously trying to create a novel lossless image compression that achieves ratios similar to PNG but beats QOI in speed. I will let you know how this goes




LOOK AT THIS COOL BEE I DREW 🐝



Introducing TurboQuant: Our new compression algorithm that reduces LLM key-value cache memory by at least 6x and delivers up to 8x speedup, all with zero accuracy loss, redefining AI efficiency. Read the blog to learn how it achieves these results: goo.gle/4bsq2qI
