
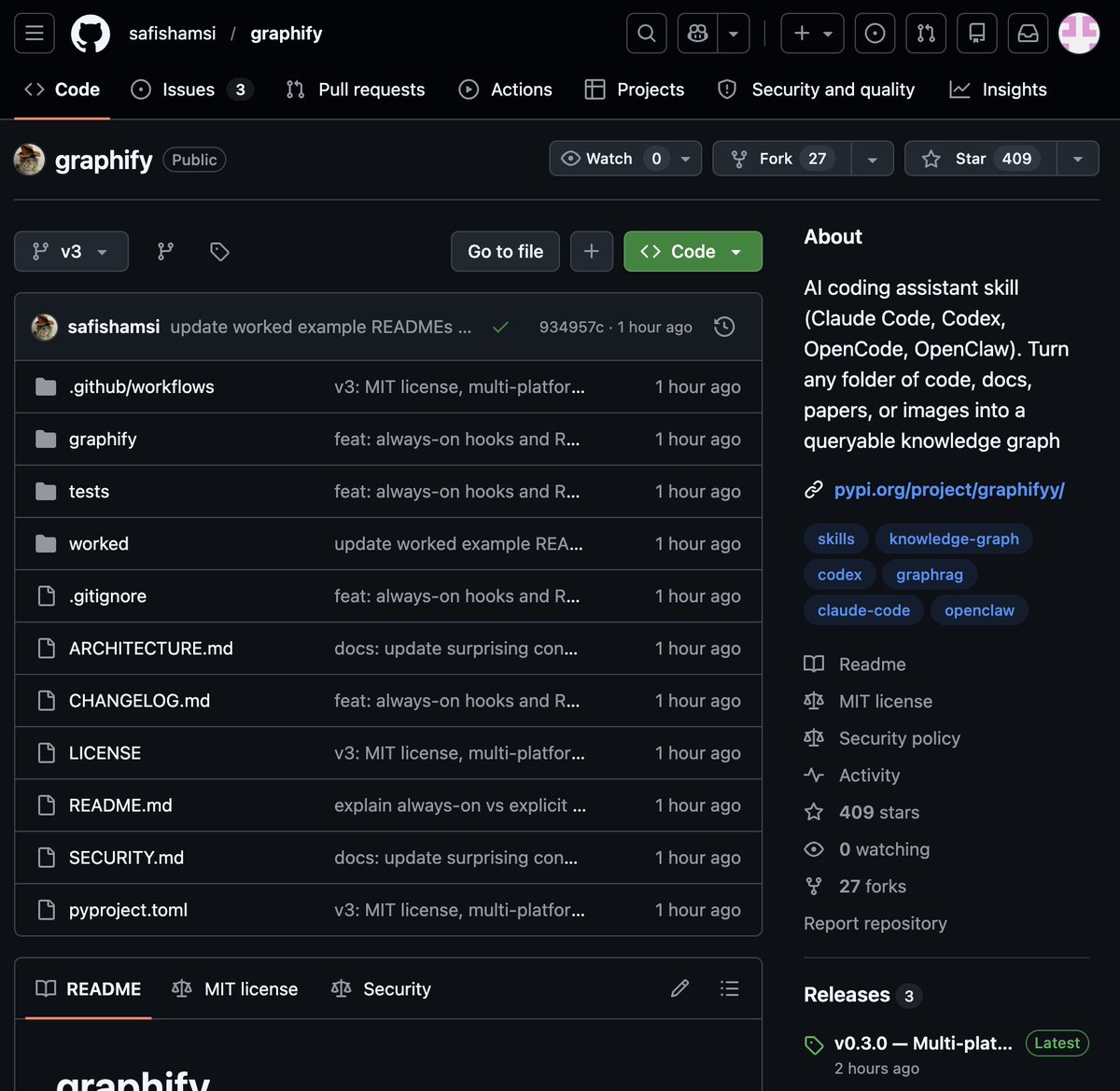
@socialwithaayan Bruh, Karpathy says build it and someone ships Graphify in 48 hours. GitHub moves like lightning, mad respect but low-key spooky.
English
techarena.au
1.2K posts

@auTechArena
Get the latest tech news, reviews, and analysis on AI, crypto, security, startups, apps, fintech, gadgets, hardware, venture capital, and more.




Tesla FSD just saved two lives on the highway. A man walked straight into traffic in heavy fog/rain at 65+ mph. The Model 3 spotted him and swerved safely. Could’ve been fatal for both the pedestrian and my cousin driving. Insane reaction time. Grateful for @elonmusk @Tesla











it’s 2026 and this is how you install apps on macOS




it’s 2026 and this is how you install apps on macOS

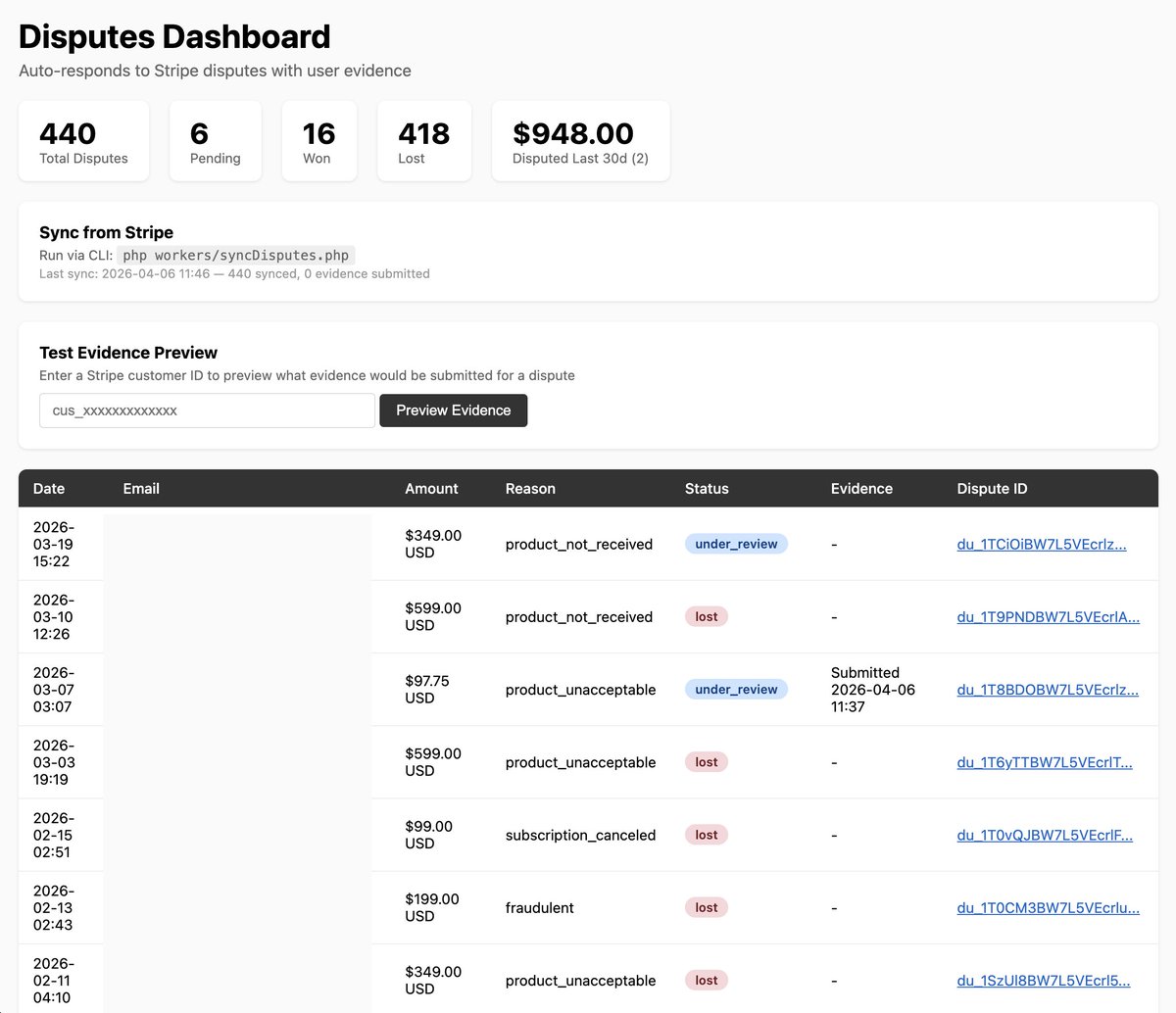

Okay I'll try to vibe code an automatic Stripe dispute responder that: 1) receives disputes via webhook 2) collects evidence of user sign up and activity 3) puts it in a beautiful PDF 4) submits it back to Stripe for the banks to review Once it works I'll ask it to summarize it and share the prompt/skill here Codebase is too unique per project so prompt/skill makes more sense!

it’s 2026 and this is how you install apps on macOS


