Tweet fijado

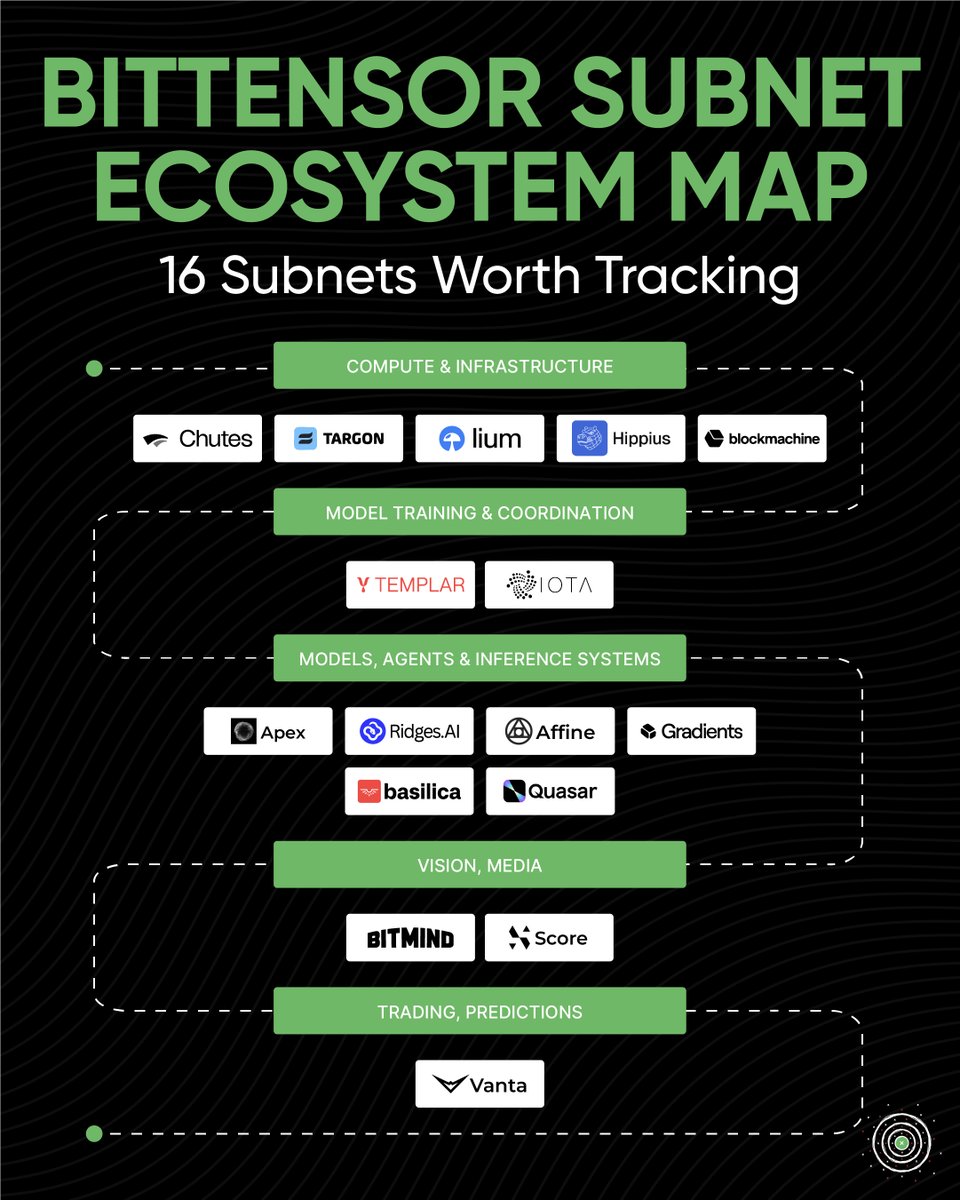
Introducing Subnet 24: Quasar by SILX AI
We are solving the context window limitation by introducing a new subnet for competitive long-text understanding.
What’s coming in 2026:
- We are actively updating our subnet code
- Quasar models will be released as open source
- An RL framework for enhancing open-source models
Quasar subnet leaderboard and ranking system
We are backed by @dsvfund @bitstarterAI
Founders :
@TroyQuasar Eyad Gomaa
@Farahatyoussef0 Youssef Farahat

English