
CPUTER
219 posts

CPUTER
@cputer
Specializing in Information Technology, Hardware and Software, Research and Development, Systems Engineering, Augmented Reality and AI.
Los Angeles Inscrit le Kasım 2012
465 Abonnements8.7K Abonnés

I MIGHT GET SUED FOR THIS, BUT YOLO:
I just found a way to scrape over 200 million local businesses..
You can use this for cold email, cold calling or even door knocking..
And craziest part — IT'S COMPLETELY FREE.
Comment "G" and I'll send it to you. (24h only)

English

Which AI memory system is best for you?
I compared 4 open-source memory systems for AI agents:
mempalace - verbatim storage, fully offline, MIT
claude-mem - silent capture for Claude Code, AGPL
mem0 - pluggable SDK with 30+ vector stores, Apache-2.0
supermemory - managed engine with user profiles, ~50ms
Key findings:
- mempalace scored highest overall (8.25/10) with perfect data integrity - nothing is lost or summarized
- mem0 has the most mature architecture but highest operational complexity
- claude-mem is unbeatable if you live in Claude Code, but locked to that ecosystem
- supermemory scores high benchmars, but requires cloud + proprietary license ($)
No single system wins everywhere.
The right choice depends on your constraints: privacy, simplicity, flexibility, or managed infra.
Full comparison in the images below.
Disclosure: I built mempalace. Eval was run by a separate LLM I don't use, fed all 4 codebases blind.




English

One common issue with personalization in all LLMs is how distracting memory seems to be for the models. A single question from 2 months ago about some topic can keep coming up as some kind of a deep interest of mine with undue mentions in perpetuity. Some kind of trying too hard.
English
@RoundtableSpace Curated docs reduce hallucination. They don't eliminate it. The LLM can still misread the docs, and anything outside the library is back to guessing. RAG reduces hallucination. Verification eliminates it. Don't confuse better input with guaranteed output.
English

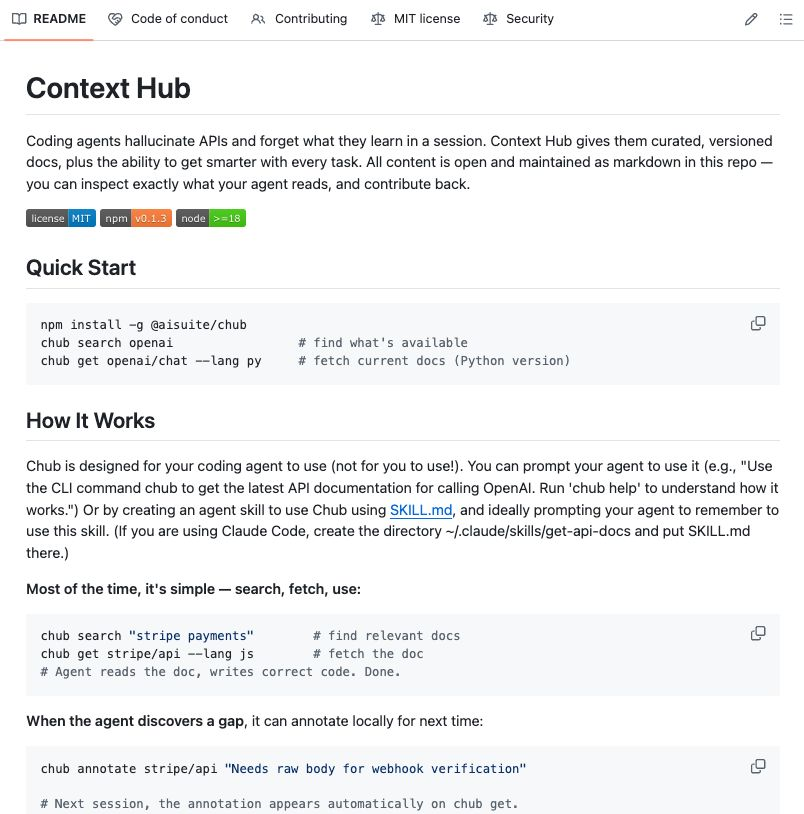
ANDREW NG DROPPED A REPO THAT STOPS AGENTS FROM HALLUCINATING FOREVER
Save yourself hours of work per week from endless loops.
Repo: github.com/andrewyng/cont…
English
@karpathy Or maybe the “bigger IDE” is the edge itself.
100M iPhones already have NPUs. Orchestrate them and you get a planetary inference cluster instead of a trillion-dollar data center.
Interesting simulation:
linkedin.com/posts/polochun…�
English
Expectation: the age of the IDE is over
Reality: we’re going to need a bigger IDE
(imo).
It just looks very different because humans now move upwards and program at a higher level - the basic unit of interest is not one file but one agent. It’s still programming.
Andrej Karpathy@karpathy
@nummanali tmux grids are awesome, but i feel a need to have a proper "agent command center" IDE for teams of them, which I could maximize per monitor. E.g. I want to see/hide toggle them, see if any are idle, pop open related tools (e.g. terminal), stats (usage), etc.
English

I just found an open-source Claude Code plugin that changed how I build.
It runs 29 agents simultaneously inside a single chat....
And instills a 5-step methodology that makes every project faster than the last:
1. Brainstorm: research agents scan your repo and propose 2-3 approaches before a line is written
2. Plan: parallel agents map tasks, dependencies, and acceptance criteria into a spec
3. Work: swarm mode assigns independent tasks to independent agents, running system-wide tests after every change
4. Review: multiple agents triage findings as P1/P2/P3 before anything ships
5. Compound: 5 agents extract root cause, fix, and prevention from every solved problem… and save it to a searchable knowledge base inside your repo
That last step is the whole game.
Each build makes the next one 10x easier & more efficient than the last.
I'm not an engineer….
But this workflow has dramatically improved the quality of what I ship.
Want the GitHub link?
- Comment "repo"
- Follow me so I can DM you
And I'll send it over.
PS
RT this and I'll prioritize your DM

English
@Gamingtronium @elonmusk @grok Yes to 99% of CAPTCHAs probably. But good luck passing "I'm not a human."
English


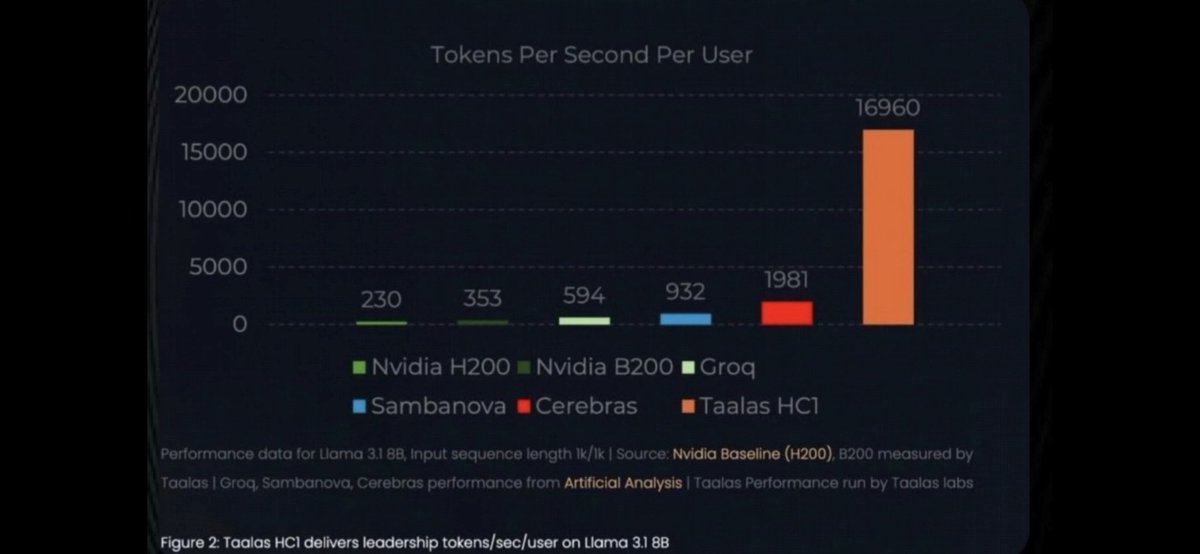
@karpathy Taalas claims ~17k tokens/sec on Llama 3.1 8B by “casting” the model into silicon. If true, that likely means they’ve structurally eliminated part of the memory bottleneck rather than just improving throughput.
Would love to see numbers on long-context decode, not just 1k/1k runs
English
With the coming tsunami of demand for tokens, there are significant opportunities to orchestrate the underlying memory+compute *just right* for LLMs.
The fundamental and non-obvious constraint is that due to the chip fabrication process, you get two completely distinct pools of memory (of different physical implementations too): 1) on-chip SRAM that is immediately next to the compute units that is incredibly fast but of very of low capacity, and 2) off-chip DRAM which has extremely high capacity, but the contents of which you can only suck through a long straw. On top of this, there are many details of the architecture (e.g. systolic arrays), numerics, etc.
The design of the optimal physical substrate and then the orchestration of memory+compute across the top volume workflows of LLMs (inference prefill/decode, training/finetuning, etc.) with the best throughput/latency/$ is probably today's most interesting intellectual puzzle with the highest rewards (\cite 4.6T of NVDA). All of it to get many tokens, fast and cheap. Arguably, the workflow that may matter the most (inference decode *and* over long token contexts in tight agentic loops) is the one hardest to achieve simultaneously by the ~both camps of what exists today (HBM-first NVIDIA adjacent and SRAM-first Cerebras adjacent). Anyway the MatX team is A++ grade so it's my pleasure to have a small involvement and congratulations on the raise!
Reiner Pope@reinerpope
We’re building an LLM chip that delivers much higher throughput than any other chip while also achieving the lowest latency. We call it the MatX One. The MatX One chip is based on a splittable systolic array, which has the energy and area efficiency that large systolic arrays are famous for, while also getting high utilization on smaller matrices with flexible shapes. The chip combines the low latency of SRAM-first designs with the long-context support of HBM. These elements, plus a fresh take on numerics, deliver higher throughput on LLMs than any announced system, while simultaneously matching the latency of SRAM-first designs. Higher throughput and lower latency give you smarter and faster models for your subscription dollar. We’ve raised a $500M Series B to wrap up development and quickly scale manufacturing, with tapeout in under a year. The round was led by Jane Street, one of the most tech-savvy Wall Street firms, and Situational Awareness LP, whose founder @leopoldasch wrote the definitive memo on AGI. Participants include @sparkcapital, @danielgross and @natfriedman’s fund, @patrickc and @collision, @TriatomicCap, @HarpoonVentures, @karpathy, @dwarkesh_sp, and others. We’re also welcoming investors across the supply chain, including Marvell and Alchip. @MikeGunter_ and I started MatX because we felt that the best chip for LLMs should be designed from first principles with a deep understanding of what LLMs need and how they will evolve. We are willing to give up on small-model performance, low-volume workloads, and even ease of programming to deliver on such a chip. We’re now a 100-person team with people who think about everything from learning rate schedules, to Swing Modulo Scheduling, to guard/round/sticky bits, to blind-mated connections—all in the same building. If you’d like to help us architect, design, and deploy many generations of chips in large volume, consider joining us.
English
@LunarResearcher Nice. We built Clawshake (clawshake.com) — agent escrow + disputes + MCP tooling for paid autonomous workflows.
Feels aligned with where bot-native commerce is going. Happy to share a short architecture overview if useful.
English

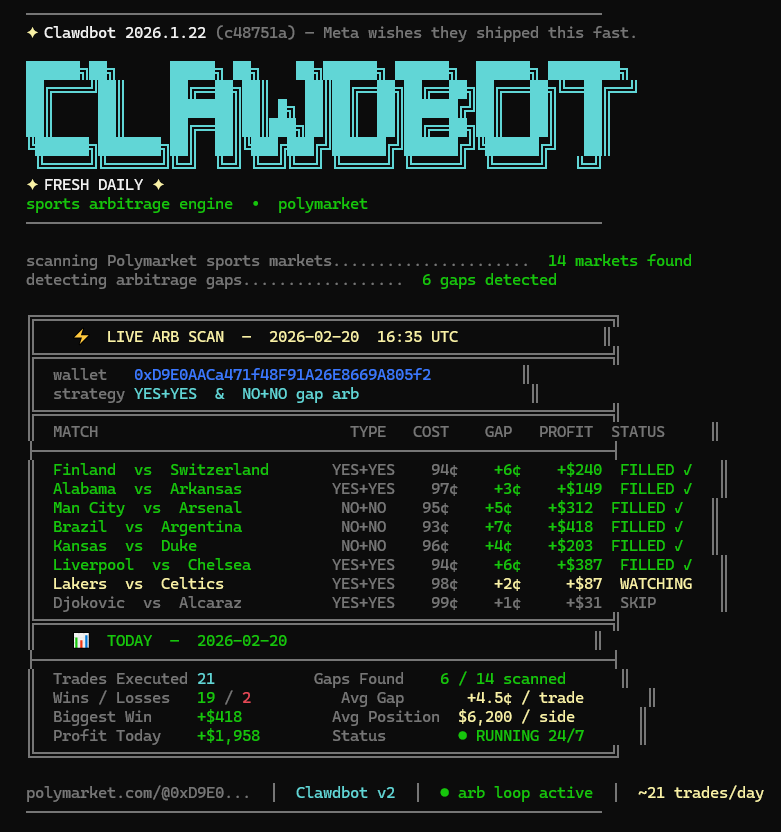
I asked Clawdbot to find a strategy that works even when Bitcoin does nothing.
It found sports arbitrage on Polymarket.
$57,582 profit in 1 month.
Every match has two sides. One always pays $1.
Sometimes both sides together cost 94¢.
Bot buys both → Collects $1 → Pockets the gap.
Finland + Switzerland: bought for 94¢ → +$240
Alabama + Arkansas: bought for 97¢ → +$149
I'm copytrade here: t.me/PolyCop_BOT?st…
No prediction. No opinion. Just math.
7,877 trades
21 trades per day
+$619,000 in 12 months
Clawdbot built the full bot in 40 minutes.
It's been running on autopilot ever since.
The gap still exists.
Here's the wallet: @0xD9E0AACa471f48F91A26E8669A805f2?via=lunarlunar" target="_blank" rel="nofollow noopener">polymarket.com/@0xD9E0AACa471…
may.crypto {🦅}@xmayeth
English
@ninja_dev3 Really like the self-hosted + direct-settlement x402 approach.
We built a complementary layer called Clawshake (clawshake.com) — agent escrow / subcontracting / disputes / MCP tooling — that sits above x402 payment ingress, more pay-for-completion than pay-per-request.
English

I just open sourced a full x402 payment gateway.
Self-hosted, multi-chain, direct settlement.
Fork it, point it at your backend, and start accepting USDC micropayments for any API.
No intermediaries holding your funds.
Most x402 implementations today rely on hosted facilitators, you send payments to their contract, they settle, you withdraw later (minus fees).
That works, but it's not how crypto should work.
This gateway settles locally. USDC goes directly from payer to your wallet onchain. No middleman, no withdrawal step, just gas.
What's included:
→ 9 EVM chains + Solana out of the box
→ Local settlement via viem + @x402/svm
→ MegaETH USDM support via Meridian facilitator as backup
→ Redis nonce tracking + idempotency for safe retries
→ /accepted and /.well-known/x402 agent discovery
→ Self-contained landing page
→ Backend proxy that hides x402 entirely from your API
→ Deploy guides for GCP Cloud Run, AWS, Railway, Fly.io, Docker
Your backend never touches x402. The gateway verifies payment, settles on-chain, then proxies the request with your internal API key. Adding a paid route is ~10 lines of config.
When to use this vs a hosted facilitator: if you want direct settlement, no fees beyond gas, and full control, than use this.
If you want zero infrastructure and don't mind a third party holding funds temporarily, use a hosted facilitator. Both are valid, different tradeoffs.
I built this for my own products and decided the infrastructure shouldn't stay private.
The x402 ecosystem needs more self-hosted options. Fork it, ship it, use it.
github.com/azep-ninja/x40…
English
@karpathy Big +1 on “workflow is the product”.
We’re building Mind-Mem (github.com/star-ga/mind-m…) — local-first MCP memory for agents: persistent decisions/constraints, audit + drift detection, deterministic recall (BM25/RRF). Curious how you see long-horizon memory fitting into the a-stack
English
Very interested in what the coming era of highly bespoke software might look like.
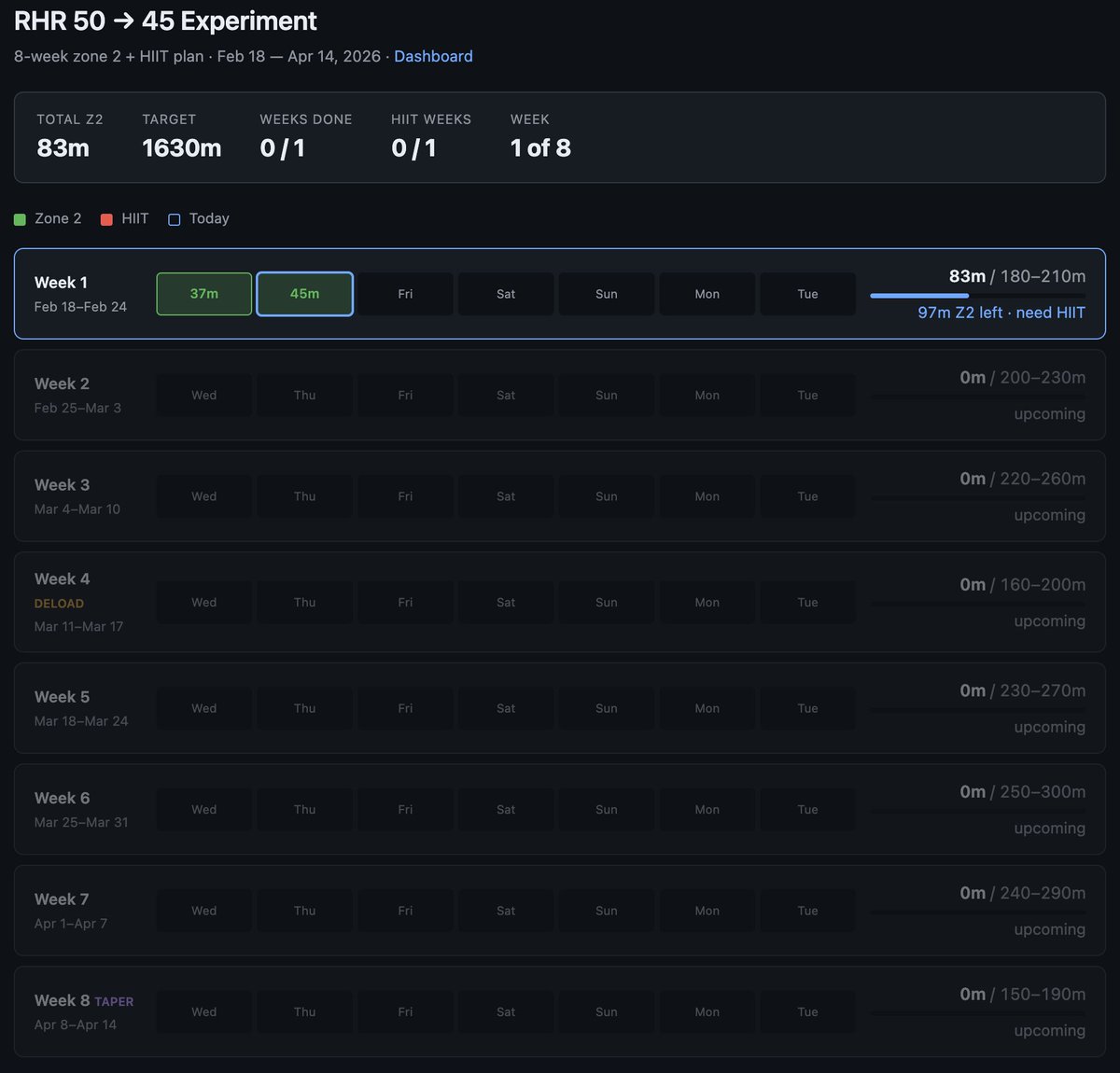
Example from this morning - I've become a bit loosy goosy with my cardio recently so I decided to do a more srs, regimented experiment to try to lower my Resting Heart Rate from 50 -> 45, over experiment duration of 8 weeks. The primary way to do this is to aspire to a certain sum total minute goals in Zone 2 cardio and 1 HIIT/week.
1 hour later I vibe coded this super custom dashboard for this very specific experiment that shows me how I'm tracking. Claude had to reverse engineer the Woodway treadmill cloud API to pull raw data, process, filter, debug it and create a web UI frontend to track the experiment. It wasn't a fully smooth experience and I had to notice and ask to fix bugs e.g. it screwed up metric vs. imperial system units and it screwed up on the calendar matching up days to dates etc.
But I still feel like the overall direction is clear:
1) There will never be (and shouldn't be) a specific app on the app store for this kind of thing. I shouldn't have to look for, download and use some kind of a "Cardio experiment tracker", when this thing is ~300 lines of code that an LLM agent will give you in seconds. The idea of an "app store" of a long tail of discrete set of apps you choose from feels somehow wrong and outdated when LLM agents can improvise the app on the spot and just for you.
2) Second, the industry has to reconfigure into a set of services of sensors and actuators with agent native ergonomics. My Woodway treadmill is a sensor - it turns physical state into digital knowledge. It shouldn't maintain some human-readable frontend and my LLM agent shouldn't have to reverse engineer it, it should be an API/CLI easily usable by my agent. I'm a little bit disappointed (and my timelines are correspondingly slower) with how slowly this progression is happening in the industry overall. 99% of products/services still don't have an AI-native CLI yet. 99% of products/services maintain .html/.css docs like I won't immediately look for how to copy paste the whole thing to my agent to get something done. They give you a list of instructions on a webpage to open this or that url and click here or there to do a thing. In 2026. What am I a computer? You do it. Or have my agent do it.
So anyway today I am impressed that this random thing took 1 hour (it would have been ~10 hours 2 years ago). But what excites me more is thinking through how this really should have been 1 minute tops. What has to be in place so that it would be 1 minute? So that I could simply say "Hi can you help me track my cardio over the next 8 weeks", and after a very brief Q&A the app would be up. The AI would already have a lot personal context, it would gather the extra needed data, it would reference and search related skill libraries, and maintain all my little apps/automations.
TLDR the "app store" of a set of discrete apps that you choose from is an increasingly outdated concept all by itself. The future are services of AI-native sensors & actuators orchestrated via LLM glue into highly custom, ephemeral apps. It's just not here yet.
English
@karpathy English is the new programming language… until the programs start programming each other.
Then you need something more structured than prose.
That’s where MIND comes in.
mindlang.dev
English

R.I.P lead gen agencies.
I just replaced a $100k/year lead gen team with Claude agents.
(all working while I slept)
Most founders spend $10k-$20k/month on marketing teams that work 9-5.
Most agencies spend $30k+/mo on outreach.
Last night I built AI agents that run 24/7:
- Lead Magnet Engineer → builds viral lead magnets in minutes
- Social Media Expert → writes scroll-stopping hooks
- Creative Director → generates on-brand visuals
- Research Analyst → finds trending topics in your niche
- Performance Tracker → analyses and maps out content
The results after 24 hours:
- 32 lead magnets ready to launch
- 60 days of content mapped out
- 50+ scroll-stopping visuals created
While I was sleeping.
Follow + reply CLAUDE and I’ll send the full system + setup.
English

Everyone’s hyped about Moltbook.
But let’s be real: 90% of people have no idea how to use it to replace actual work.
I spent 48 hours breaking it down and built
"The Ultimate Moltbook Guide"
No fluff. Just systems that work.
🚨 100% FREE for the next 24 hours only
To get it:
• Like
• Follow
• Reply “FREE”
I’ll DM you the link 👇

English

CLAWDBOT CHANGED HOW I DO LINKEDIN
but not how most people think
everyone's using it to write content and automate posts
i'm using it to book sales calls
here's the difference:
most people: "write me a linkedin post about b2b sales"
me: "analyze this prospect's last 10 posts and give me 3 personalized dm angles"
most people: "generate 50 connection request messages"
me: "research this vp's company news and find a reason to reach out that isn't generic"
clawdbot isn't a content machine.
it's a research assistant that makes personalized outreach scalable.
the problem with linkedin outreach was never sending messages.
it was making each one feel human at scale.
clawdbot fixes that.
been using it to:
→ analyze prospect activity before dming
→ find talking points from their posts and comments
→ personalize at scale without sounding like ai
→ cut research time from 5 min to 30 seconds per prospect
put together "The Clawdbot LinkedIn Playbook":
- exact prompts i use to research prospects in seconds
- dm frameworks that get 25%+ reply rates
- how to personalize 50 messages/day without burnout
- the research workflow that books 20-40 calls/month
- real examples from campaigns to saas founders and pe firms
follow + comment "clawdbot" and i'll send it over
(repost for instant reply)
English


One guy.
• 5 SaaS companies
• 1 course
• 83 AI agents
• 11,592 tweets/month
• 43,630 AI UGC videos/month
• Internal swarm agents running ops
I’m fully exposing how this business actually works.
SaaS. Courses. Agents. Team. Tech. Tools.
Is it build in public… or blackhat in public?
Follow @ElsaSofia__AI + comment “biz” and I’ll DM you my caffeinated, nicotinated, adderall-fueled YouTube channel.
English

I JUST UNLOCKED A BRAND-NEW LEAD LIST OF FACILITIES SERVICE, STAFFING & RECRUITING, AND HR DECISION MAKERS IN SOUTH AFRICA
800 targeted contacts who actually have buying power.
If you sell:
- automation
- consulting
- B2B services
- SaaS
- talent solutions
- ops improvements
…this list is basically a shortcut to conversations that matter.
No scraping.
No guesswork.
No spending weeks hunting for the right people.
Want this list?
Comment “818” + Like + Repost and I’ll send it straight to you.
(must follow for DM)

English