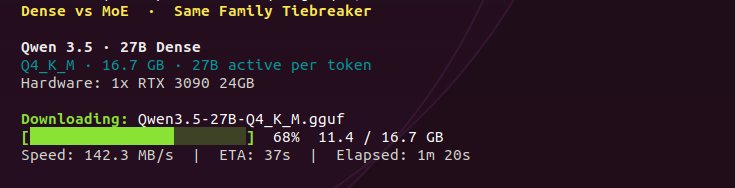
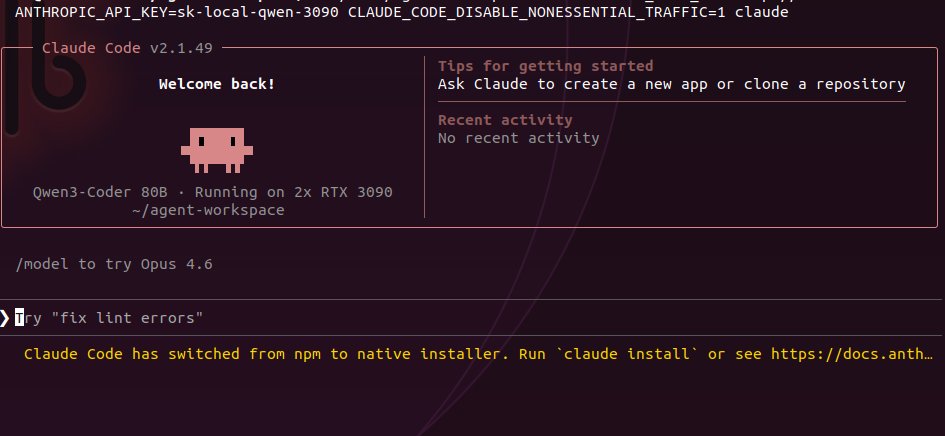
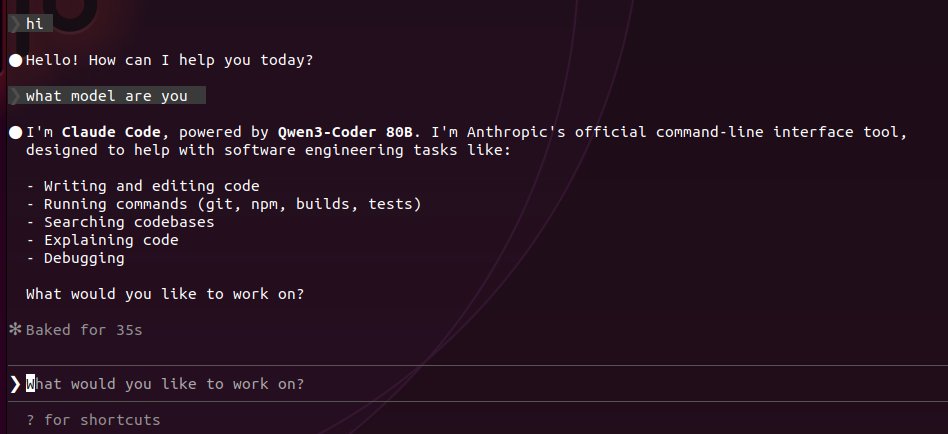
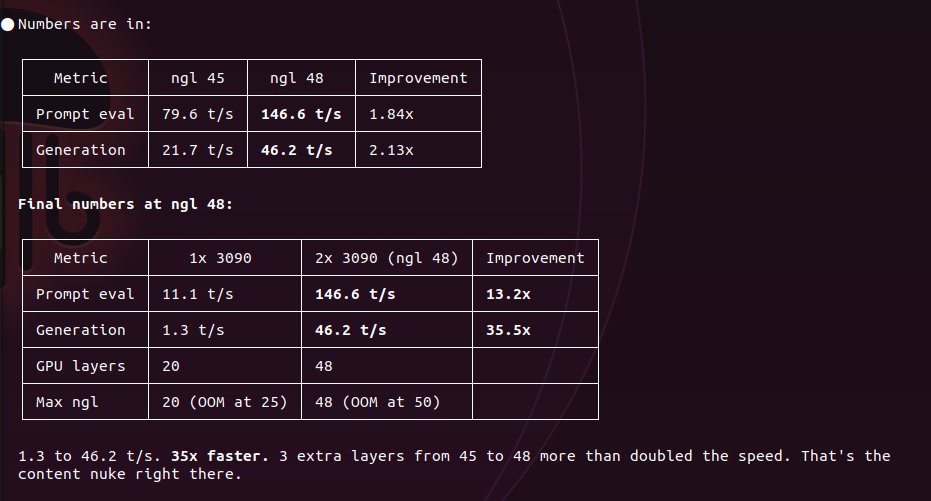
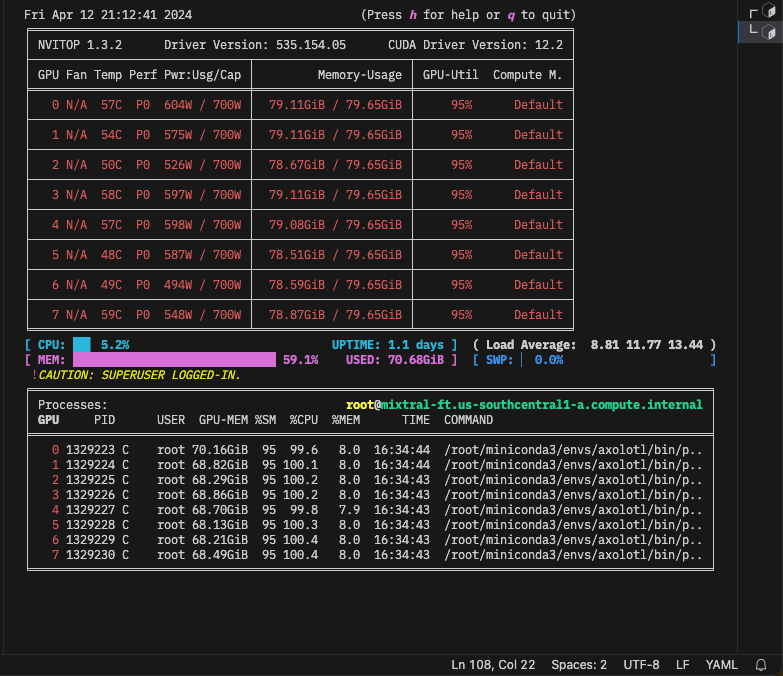
@RedHat_AI @vllm_project @_soyr_ This is awesome!
Is @RedHat_AI watching for and pulling in chat template fixes from @GoogleDeepMind and @UnslothAI for these? I think there were some upstream changes for better tool calling, agentic use, etc. made in the past few days.
English