Sudo su@sudoingX
been playing with hermes agent paired with qwen 3.5 dense 27B on my single 3090 since last night. there is something about this harness that caught me and i think i know what it is.
i've now run five qwen configs on consumer hardware:
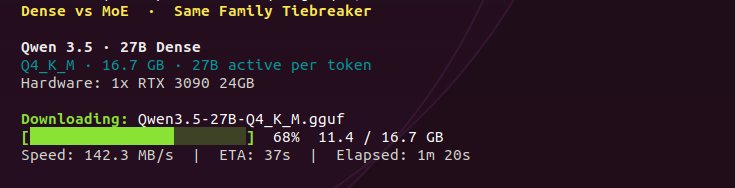
35B MoE (3B active) -- 112 tok/s flat across 262K context, 1x 3090
27B dense -- 35 tok/s, zero degradation across the same range, 1x 3090
qwopus 27B (opus distilled) -- 35.7 tok/s, same architecture, different brain
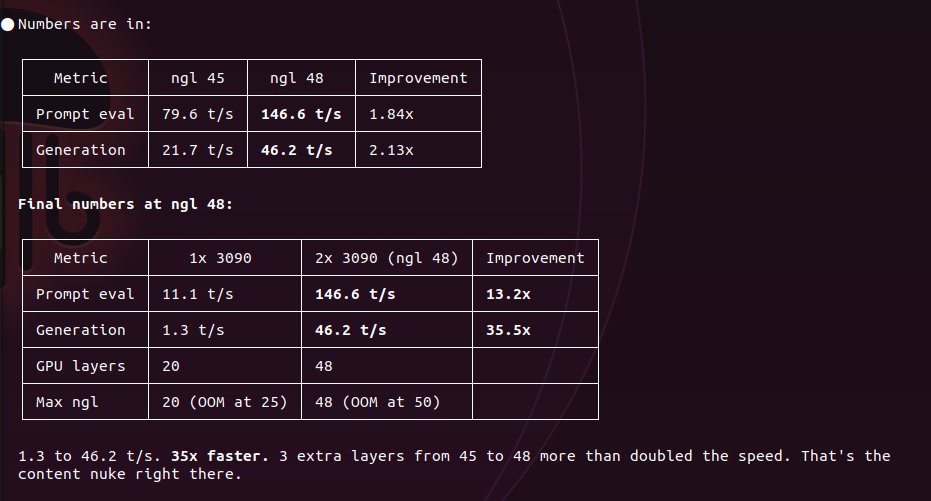
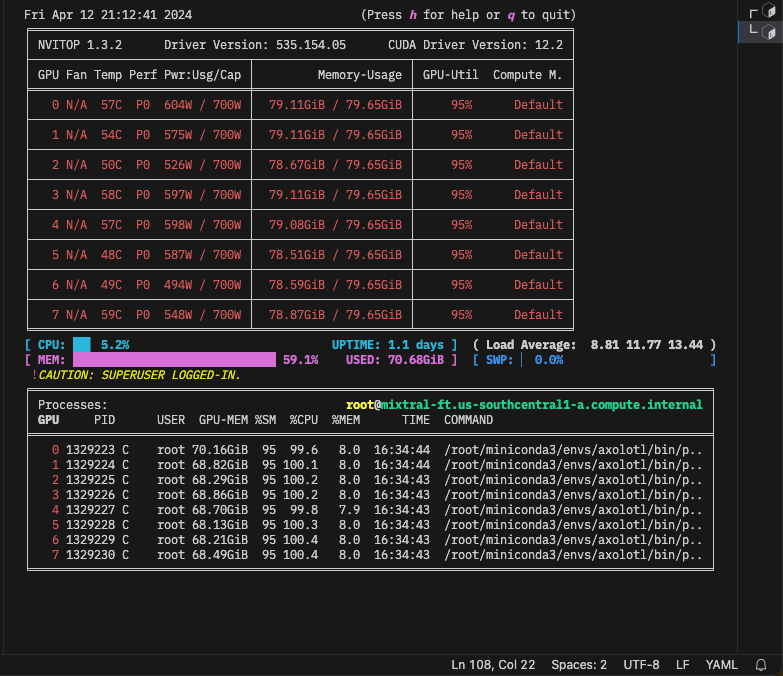
80B coder -- 46 tok/s on 2x 3090s, oneshotted a 564 line particle sim
80B coder -- 1.3 tok/s on 1x 3090, bleeding through RAM because it didn't fit but it still ran
with same benchmarks. same prompts. same quant where possible. every config is documented. i know these models.
and hermes agent is the first harness that feels like it respects that work. tool calls show inline with execution time. nvidia-smi 0.2s. write_file 0.7s. you see exactly what the agent is doing and how long each step takes. no mystery. no black box. no tool call failures so far and i've been pushing it.
most agent frameworks feel like you're watching a spinner and hoping. hermes shows the work. that transparency changes how you trust the output.
once you use it you see the UX decisions are not accidental. @Teknium and the nous team built this like engineers who actually use their own tools. 80 skills. 29 tools. persistent memory. context compression. runs clean on a single consumer GPU.