
Bleys Goodson
91 posts



Open source AI is actually moving at an unhinged pace right now.
I literally hadn't even finished typing up my last Gemma 4 12b benchmark notes before Google went ahead and dropped the official Quantization Aware Training (QAT) checkpoints on Hugging Face.
If you missed the news, QAT basically bakes the compression directly into the training process. Instead of standard post training quantization degrading the model's reasoning capabilities, QAT trains the model with compression in mind.
Unsloth is reporting near original performance at 4-bit with ~72% lower memory footprint. Details in the comments.
Naturally, had to instantly pull the new GGUFs to see what a single RTX 4090 card (24 GB VRAM, Cuda 12.8, ubuntu 22) could do. i fired up llama.cpp engine again
Look at these numbers:
1. Unsloth Gemma 4 26B-A4B IT (QAT Q4_K_XL) flags:
./build/bin/llama-cli -m gemma-4-26B-A4B-it-qat-UD-Q4_K_XL.gguf -cnv -ngl 99 -c 250000 -fa on -v
VRAM Used: 19.5 GB
context: 250,000 tokens
decode throughput: 193 tps
2. Unsloth Gemma 4 31B IT (QAT Q4_K_XL) flags:
Command: ./build/bin/llama-cli -m gemma-4-31B-it-qat-UD-Q4_K_XL.gguf -cnv -ngl 99 -c 60000 -fa on -v
- VRAM Used: 23 GB (Tight, but zero system RAM spillover)
- context: 60,000 tokens
- decode throughput: 47 tps
We are essentially watching hardware bottlenecks evaporate in real time.
An update literally drops before you can finish benchmarking the previous one. What a time to be running local hardware.
If you have a single rtx 3090, rtx 4090, these are the latest gemma models to try this week.
Alok@analogalok
if you have a 24gb card for local llms, you absolutely cannot miss this. Gemma 4 12b vs Gemma 4 24b A4B I just ran the unsloth Gemma 4 12B UD-Q8_K_XL (dense) on a single RTX 4060 (24GB) with llama.cpp, cuda 12.8. Built the latest llama.cpp from source on Ubuntu 22. 56 tokens per second at 250k full context. 18.2 GB VRAM. then I ran the gemma-4-12b-it-UD-Q8_K_XL.gguf MoE with only 4b active parameters to see what you actually give up by not running the bigger model. it used 22.8 GB of my 24 GB, ran at 32 t/s, and barely moved the needle on benchmarks. # 12B dense flags: ./build/bin/llama-cli -m gemma-4-12b-it-UD-Q8_K_XL.gguf -cnv -c 250000 -ngl 99 -v 250k ctx → 56 t/s · 18.2 GB VRAM 128k ctx → 56 t/s · 16.2 GB VRAM decode throughput doesn't change with context length. at all. # 26B MoE (for comparison): ./build/bin/llama-cli -m gemma-4-26B-A4B-it-UD-Q8_K_XL.gguf -cnv -c 250000 -fa on -v - 250k ctx → 32 t/s · 22.8 GB - 128k ctx → 40 t/s · 22.7 GB # what the 26B MoE gets you over the 12B: - GPQA Diamond: 82.3% vs 78.8% - AIME 2026: 88.3% vs 77.5% - LiveCodeBench: 77.1% vs 72.0% - Codeforces ELO: 1718 vs 1659 - MMLU Pro: 82.6% vs 77.2% - MATH Vision: 82.4% vs 79.7% - BigBench: 64.8% vs 53.0% - Tau2: 68.2% vs 69.0% ← 12B wins you're spending 4.5 GB more VRAM and losing 24 tokens per second for those margins. on a 24 GB card that's nearly maxing out your memory for a model that runs at 32 t/s. 56 t/s. 250k context. 18.2 GB on a consumer GPU. no API. no cloud. locally. if you’re sitting on 24GB of VRAM (a single RTX 3090, 4090, or RX 7900 XTX), pull the Gemma 12B and drop your numbers in the replies. let's build a real world community benchmark.
English

@analogalok I also tested the QAT 26B-A4B on an RTX 4090. I did this sweep of performance up to 100k context (tested against latest commit of llama-cli, on Ubuntu 24.04 and CUDA 13.2)

English



@teortaxesTex Referring to the main CritPt page where they show their initial testing results. A fair caveat is that no models scored above 10% without access to tools. The best-available raw model for their initial report was Gemini 3 Pro at 6.9%

English


Pretty amazing how CritPt separates labs into tiers. Here are strongest soldiers of each. There's the absolute frontier, there are guys trying to get ready for the AI scientist era, there are the agent-pilled crowd, and then… the ngmi club.

English
Agent Arena details: x.com/arena/status/2…
or arena.ai/blog/agent-are…
Arena.ai@arena
Introducing Agent Arena: real-world agentic evals at scale. How do you evaluate agents doing actual work? We measure millions of live sessions where real users accomplish real tasks. On Arena, models now get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents. Every session produces rich signals. Users iterate with the agent turn-by-turn: approving, editing, correcting, praise or expressing frustration. The environment gives feedback too: shell errors, tool failures, recovery attempts, and more. Our leaderboard measures each model's agentic performance using causal inference across five signals: task success, steerability, error recovery, user praise vs. complaint, and tool hallucination. This leaderboard snapshot is built from 300K+ tasks, 2M+ tool calls, and 40M lines of code by agents. Top labs in Agent Arena: - #1 @OpenAI: GPT-5.5 (High) - #2 @AnthropicAI: Claude-Opus-4.7 (Thinking) - #3 @Zai_org: GLM-5.1 - #4 @GoogleDeepMind: Gemini-3.1-Pro - #5 @Kimi_Moonshot: Kimi-K2.6 More analysis in the thread, with the full technical blog below.
English
New Agent @arena pits models against each other in a real agentic harness. Congrats, dynamic real-world comparison is here!
I spotted a big next opportunity..
Their analysis of the tasks and categories is much like my analysis of DeepSWE challenge catalog: x.com/bleysg/status/…
The big opportunity:
Use task distribution and the deeper categories I broke out in the DeepSWE analysis to build a by-model signal on things like..
"Highest-complexity tasks which are full feature requests in Rust with a behavior theme of data transformation"
This then goes from, "average performance across all work types, in all languages, for all users," to, "average performance for my work types, in my languages, for my users" ... the signal people actually want.

English
Wanted to like the vision capabilities, but they're frankly way below par. Asked 12B, 26B A4B, and Qwen3.6 35B A3B all about the same images (one by one in fresh contexts). On every image (mix of photos and charts), the MoE VLMs all answered reasonably well (identifying landmarks, noting chart elements and themes accurately, etc.) while 12B was practically blind in comparison.
English

@arena just released their Agent Arena, which blindly pits models against each other in a real agentic harness. Congrats! Dynamic real-world comparison is where we knew we needed to go, and we're closer to that now!
What jumped out to me immediately is that they analyze the tasks and categorize them as seen below. This is very much like the work I did this week analyzing the @datacurve DeepSWE challenge catalog: x.com/bleysg/status/…
There's a big opportunity here to use that task distribution (and moreso, the deeper categorizations I broke out in that DeepSWE analysis) to allow a by-model signal on things like "highest-complexity tasks which are full feature requests in Rust with a behavior theme of data transformation" (or mix and match whatever filters you have meaningful data for in the same grain).
This then goes from, "average performance across all work types, in all languages, for all users," to "average performance for my work types, in my languages, for my users" ... the signal people actually want.
Arena.ai@arena
What are people actually using agents for? We analyzed the task distribution in Agent Arena across a 7-day window: 160K real user tasks spanning coding, debugging, research, document creation, frontend development, file analysis, and long multi-step workflows. The largest categories were: - Code writing (17.5%) - Research and lookup (10.8%) - Planning and brainstorming (10.6%) - Multimodal image/video work (10.2%) - Document creation (9.1%) - Code debugging (8.9%) Agent usage is broad: it’s not just coding, but research, planning, content creation, file work, and complex workflows that combine multiple tools over many turns.
English
Great work! Your breakdown by task distribution is very similar to what I did by analyzing the DeepSWE eval in this report: x.com/bleysg/status/…
There's a big opportunity here to use that task distribution (and moreso, the deeper categorizations I broke out in that report) to allow a by-model signal on things like "highest-complexity tasks which are full feature requests in Rust with a behavior theme of data transformation" (or mix and match whatever filters you have meaningful data for in the same grain).
This then goes from "average performance across all work types, in all languages, for all users" to "average performance for my work types, in my languages, for my users" ... the signal people actually want.
Bleys Goodson@bleysg
I got a lot of followup on my DeepSWE testing of Minimax M3 asking what it means to be fluent in this eval set. I dug into it. Full report covers breakdown by languages, task types, complexity, and more so you can see just how applicable it is to your type of work. entrpi.github.io/misc/deepswe-s…
English

This is our most important eval yet - Agent Arena - it measures real performance of models on real agentic tasks.
Our users use the Agent Arena, we monitor real signals (e.g. Bash Recovery) as well as their feedback on each task, without user knowing what model completed it.
This eval is important as it is based on real users with ever changing needs and not a set of pre-written questions. These rankings will never go out of date and as users' expectations will increase, this eval will evolve with them.
Arena.ai@arena
Introducing Agent Arena: real-world agentic evals at scale. How do you evaluate agents doing actual work? We measure millions of live sessions where real users accomplish real tasks. On Arena, models now get web search, filesystem, and terminal tools to complete complex workflows: writing code, creating slide deck, researching the web, building apps, and analyzing documents. Every session produces rich signals. Users iterate with the agent turn-by-turn: approving, editing, correcting, praise or expressing frustration. The environment gives feedback too: shell errors, tool failures, recovery attempts, and more. Our leaderboard measures each model's agentic performance using causal inference across five signals: task success, steerability, error recovery, user praise vs. complaint, and tool hallucination. This leaderboard snapshot is built from 300K+ tasks, 2M+ tool calls, and 40M lines of code by agents. Top labs in Agent Arena: - #1 @OpenAI: GPT-5.5 (High) - #2 @AnthropicAI: Claude-Opus-4.7 (Thinking) - #3 @Zai_org: GLM-5.1 - #4 @GoogleDeepMind: Gemini-3.1-Pro - #5 @Kimi_Moonshot: Kimi-K2.6 More analysis in the thread, with the full technical blog below.
English
@AnjneyMidha @CadeMetz @nytimes @NEA @a16z @ycombinator @stepstonegroup You've come back full circle from our talks back in 2023 when our tiny lab was making the best edge inference models on scrounged-together compute! Catch up soon?
English

thank you to @CadeMetz from the @nytimes for spending time to write about AMP PBC's vision for a healthy independent frontier technology ecosystem, and to our capital partners such as @NEA @a16z @ycombinator @stepstonegroup for supporting the mission
nytimes.com/2026/05/12/tec…
English
today, we @amppublic are announcing a $500M profit pool we have set aside to help local communities navigate the AI transition over the next few years
we'd love to hear ideas for the best way to distribute these funds
anyone can submit here: #public-wealth-fund" target="_blank" rel="nofollow noopener">amppublic.com/#public-wealth…

English
@kuchaev Exciting! Can you break out exactly what's measured by "Relative Mean Token Count Ratio"?
English

During post-training, a deliberate attention has been paid to token efficiency which together with hybrid architecture and MTP delivers superior inference cost. 3/4


English
Very excited to share Nemotron 3 Ultra, 550B total with 55B active MoE hybrid Mamba-Attention model post-trained for agentic applications!
This model delivers frontier-level agentic accuracy while being fast and open with weights, training software, and data available for commercial use. 1/4
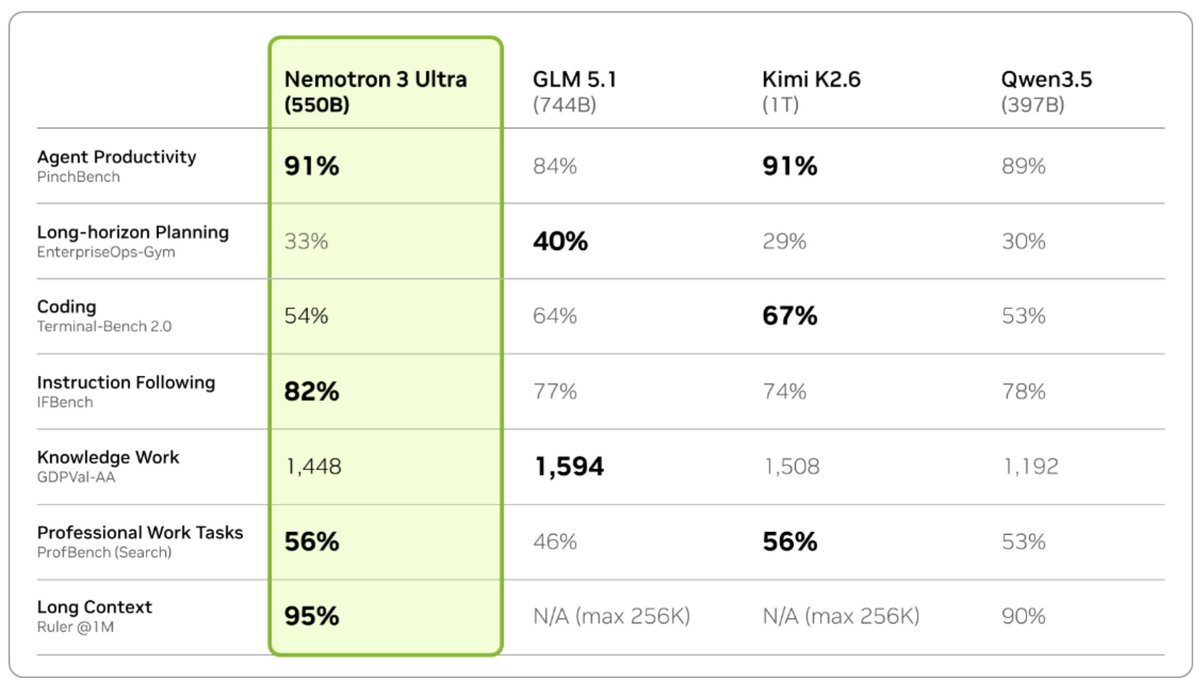
English
@teortaxesTex I submitted a PR to help address this for them. Might try my own DeepSeek V4 run.
English
DeepSWE is an interesting eval, as in a set of problems, but the actual evaluation leaves much to be desired.
V4 costs are all about cache hits. Though it seems here even that doesn't fully explain the failure. It's *cheap*. And it's stronger.
@bleysg pls check

Anime fan@badboy999654
@teortaxesTex You saw this? github.com/datacurve-ai/d…
English
When I ran it I had to deal with a lot of 429 errors from Minimax API. Likely they were seeing similar. If they didn't control for those that could drag the score down artificially. Also, Minimax just worked to roughly double their API tok/s, so the model should be able to complete more tasks without timing out and should get a better Avg time score now.
English

DeepSWE informed me that the MiniMax-M3 run had several issues during the benchmarking and that they had to retract the score
The ranking as shown in the image should be seen more as a lower bound.
Lisan al Gaib@scaling01
MiniMax M3 scores above DeepSeek V4 Pro on DeepSWE, but below other chinese competitors
English
@datacurve Every challenge is searchable with readable summaries at the end of the report as well.

English
I got a lot of followup on my DeepSWE testing of Minimax M3 asking what it means to be fluent in this eval set.
I dug into it.
Full report covers breakdown by languages, task types, complexity, and more so you can see just how applicable it is to your type of work.
entrpi.github.io/misc/deepswe-s…



English
English
